能夠推理思考的新代模型?ChatGPT o1 上線
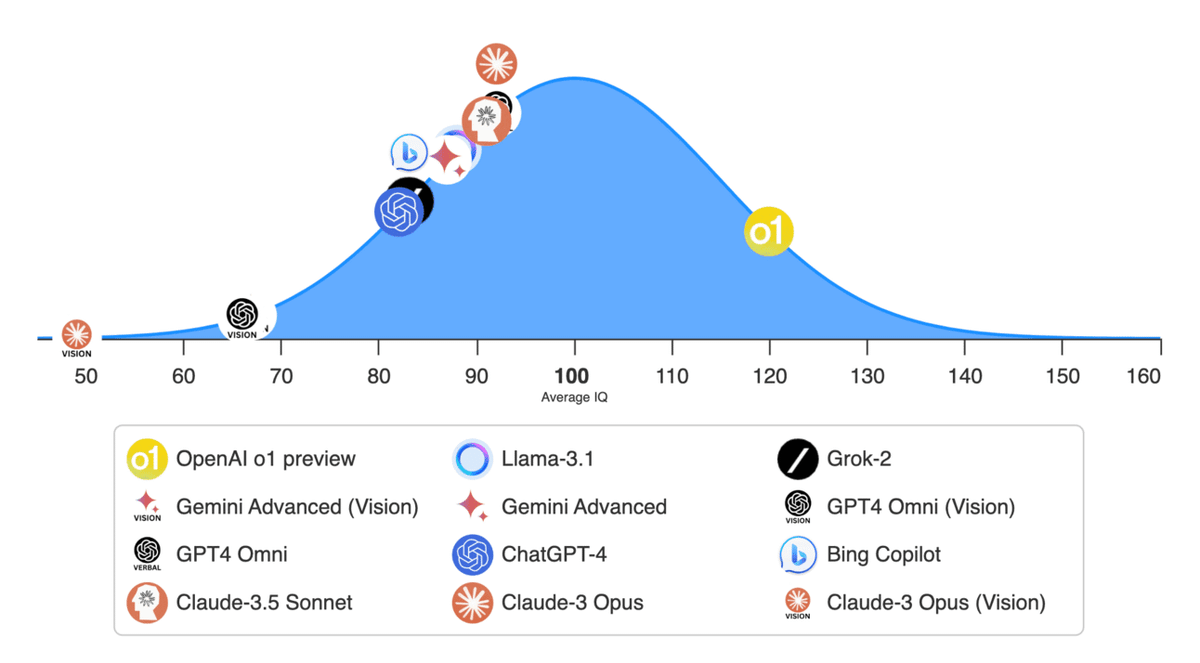
OpenAI 於 9/12 推出了最新的 ChatGPT 模型 —— ChatGPT o1。這個新模型的最大特色在於它能夠模擬「人類思考」的方式來回答問題,這使它在需要「邏輯推理」的任務中表現更為優秀,雖然回答的速度較慢,但不僅可以減少 AI 的幻覺問題,還能提高回答的準確性。根據測試,ChatGPT o1 在數學、物理、程式碼等專業領域的成功率顯著提高,尤其在面對學術性難題時,其正確率提升至 83%,相比之下,GPT-4 只有 13% 的正確率。這意味著 ChatGPT o1 已經超越了以往的 AI 模型,為用戶提供更強大的問題解決能力。就連過去 ChatGPT 無法辨別單字"Strawbe

來源: OpenAI 官網
OpenAI 於 9/12 推出了最新的 ChatGPT 模型 —— ChatGPT o1。這個新模型的最大特色在於它能夠模擬「人類思考」的方式來回答問題,這使它在需要「邏輯推理」的任務中表現更為優秀,雖然回答的速度較慢,但不僅可以減少 AI 的幻覺問題,還能提高回答的準確性。根據測試,ChatGPT o1 在數學、物理、程式碼等專業領域的成功率顯著提高,尤其在面對學術性難題時,其正確率提升至 83%,相比之下,GPT-4 只有 13% 的正確率。這意味著 ChatGPT o1 已經超越了以往的 AI 模型,為用戶提供更強大的問題解決能力。就連過去 ChatGPT 無法辨別單字"Strawberry"中有幾個r的問題,也被有效的解決!

來源:Quinton Newman
目前,o1-preview 版本已部分開放給 Plus 用戶使用!用戶只需要進入 ChatGPT 的介面,在模型選擇上選擇 o1 就可以體驗了,如果還沒有出現 o1 的選項,就必須在等等,不久後就會全面開放給 Plus 以及 Team 用戶使用了。
官方提供的提示詞建議
官方針對 ChatGPT o1 有提出四個提示詞的建議:
1. 保持提示簡單直接:這些模型擅長理解和回應簡短明確的指示,無需詳細的引導。
錯誤作法:
給模型過於冗長或複雜的指示,例如:「請詳細說明如何開發一個應用程式,從初始概念到最終產品,並且解釋每一個技術細節和設計過程。」
正確作法:
給出簡明扼要的指示,例如:「如何開發一個應用程式?」
2. 避免思維鏈提示:如 「請逐步思考」、「Step by Step」的提示詞,由於這些模型在內部完成推理,提示它們「逐步思考」或「解釋你的推理」是沒有必要的,反而會讓答案出錯。
錯誤作法:
「請逐步思考並解釋如何解決這個程式碼的問題,列出每個推理過程的細節。」
正確作法:
貼上 code 「如何解決這個 bug?」
3. 使用分隔符以提高清晰度:使用三引號、XML標籤或分段標題等分隔符來明確標示輸入的不同部分,有助於模型正確解釋各個部分。
錯誤作法:
「幫我參考範例文章A、範例文章B,寫出範例文章C,範例A:,範例B:」
正確作法:
「幫我參考範例文章A、範例文章B,寫出範例文章C
**範例A**
**範例B**」
4. 限制檢索增強生成(RAG)中的額外上下文:在提供額外的上下文或文件時,僅包括最相關的信息,以防止模型過度複雜化其回應。
錯誤作法:
「請摘要本篇文章關於Iphone 16 的資訊,不要摘錄 Ipad、Mac、Apple watch 等其他產品」
正確作法:
不要平面,要垂直「請摘要本篇文章關於 Iphone 16 的資訊,包含型號、開售日期、硬體配備、活動」



