Anthropic 訂閱大變動:Claude 封殺 OpenClaw存取
Anthropic 宣布自太平洋時間2026 年4 月4 日起,Claude 訂閱方案不再支援 OpenClaw 等第三方工具的 API 請求;同日,AnthroPAC 政治行動委員會正式申報成立。兩件事揭示 Anthropic 正主動收緊產品邊界、積極介入政策場域。


2026 年 4 月 4 日,Anthropic 在同一天端出兩項重磅消息:正式切斷 Claude 訂閱與 OpenClaw 等第三方代理工具的連接,並向美國聯邦選舉委員會申報成立政治行動委員會 AnthroPAC。這兩件事看似無關,卻都指向同一個方向:Anthropic 正在以更主動的姿態掌控自己的產品邊界與政策影響力。
Claude 訂閱變動了什麼
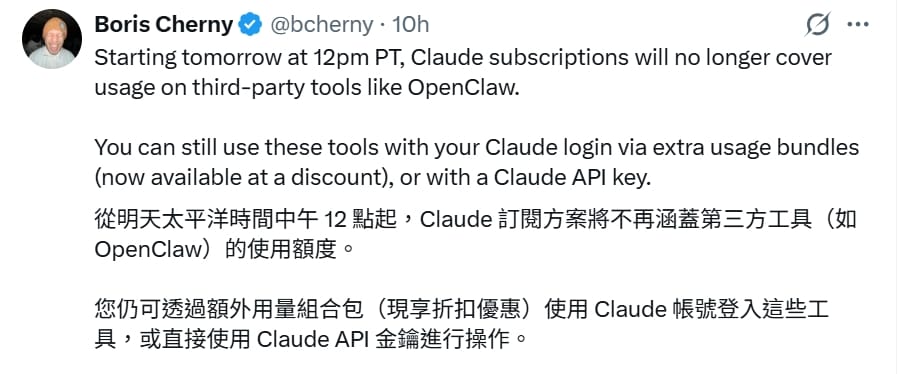
Claude 的月費與年費訂閱方案不再涵蓋透過第三方代理工具(如 OpenClaw)發出的 API 請求。過去,部分用戶會使用這類工具自動化呼叫 Claude,藉此繞過官方介面直接批次處理任務——而這些請求的使用量,原本都算在訂閱額度內。
Anthropic 給出的理由很直白:這些工具的使用方式「不是訂閱方案設計的使用情境」,大量自動化請求對系統造成不成比例的資源負擔。換句話說,Claude 訂閱是給「人坐在介面前使用」的方案,而不是給自動化腳本跑的。
這個調整波及的主要是重度自動化用戶與小型開發者,他們原本依賴訂閱方案壓低成本。一般透過 claude.ai 網頁介面、Claude 應用程式正常使用的用戶,此次變動不受影響。
受影響用戶的替代方案比較
Anthropic 為受影響的用戶提供了三條出路,並給予現有訂閱用戶一次性等值抵扣(需在 4 月 17 日前兌換)。
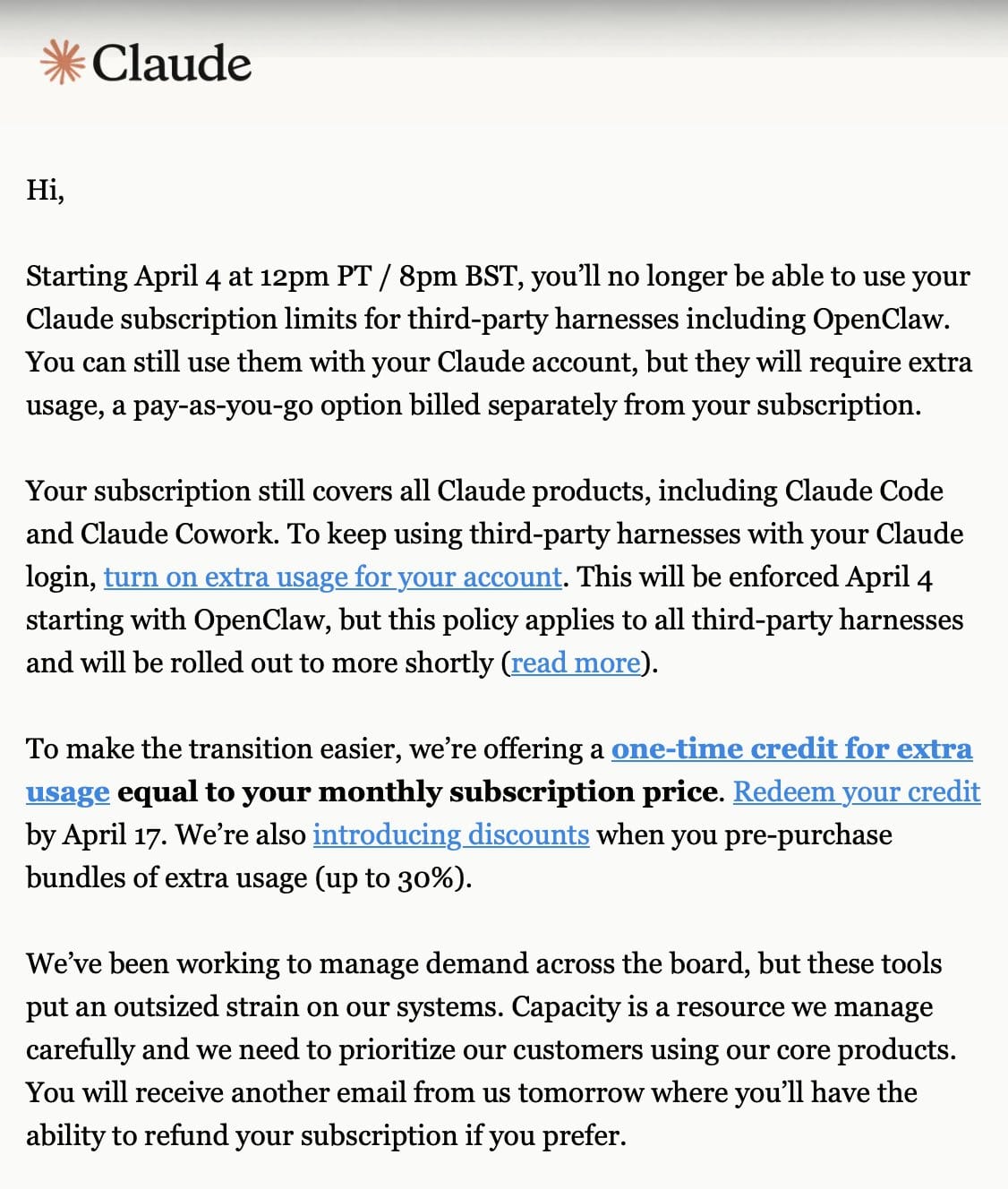
| 方案 | 說明 | 適合對象 | 成本結構 |
|---|---|---|---|
| 繼續使用訂閱 | 維持月費方案,但只能透過官方介面使用 Claude | 一般工作用途,不需自動化 | 固定月費不變 |
| 購買「額外使用額度」 | 按量計費的加購方案,可搭配訂閱使用 | 偶爾需要高用量的用戶 | 依用量彈性計費,預購最高享 30% 折扣 |
| 改用 Anthropic API | 直接透過 API 金鑰存取,不透過訂閱 | 開發者、自動化工作流 | 依 token 計費,需自行管理額度 |
若你原本使用 OpenClaw 搭配 Claude 訂閱做自動化任務,切換到 Anthropic API 金鑰是最直接的替代路徑。成本結構雖然從固定月費變為按量計費,但對使用量穩定的用戶來說,長期下來不一定比較貴。
AnthroPAC 是什麼,為何此時成立
AnthroPAC 是指 Anthropic 於 2026 年 4 月 3 日向美國聯邦選舉委員會(FEC)正式申報的政治行動委員會,資金完全來自員工自願捐款,每人每年上限 5,000 美元,所有捐款透過 FEC 公開備案。
成立政治行動委員會(PAC)對科技公司而言並不罕見,Google、Meta、Microsoft 都有自己的 PAC。但 Anthropic 的時機點值得注意:AnthroPAC 申報的時間點正好在美國 2026 年期中選舉前,且 Anthropic 目前正就美國國防部將其列為「供應鏈風險」企業一事提出法律訴訟。
AnthroPAC 採雙黨制運作,由跨黨派董事會監督,主要支持對「AI 友善」政策有影響力的聯邦候選人。Anthropic 的目標不是押注特定政黨,而是確保在政策桌上有自己的聲音——尤其是在 AI 監管、政府採購與國家安全議題上。
對 AI 用戶的影響與啟示
Claude 訂閱的變動短期內對台灣一般用戶影響有限,因為大多數人是透過 claude.ai 介面直接使用,不走第三方工具。真正需要重新評估使用方式的,是那些把 Claude 訂閱當成「廉價 API 入口」在用的自動化工作者。
更值得關注的是整體趨勢:主要 AI 公司正在逐步收緊訂閱邊界,區分「消費者使用」與「開發者使用」的成本結構。這意味著未來依賴 AI 的工作流若要穩定,必須對成本模型有更清楚的認識,而不是只選「最便宜的方案」就好。
AnthroPAC 的成立則代表 AI 公司開始正面介入政策場域。對普通用戶來說,這件事的短期影響不直接,但若美國的 AI 監管走向受到這類遊說活動影響,最終仍會牽動全球 AI 工具的使用環境。
想每週掌握最新 AI 工具與趨勢?訂閱 AI 郵報,每週精選重點直送信箱,讓你不錯過任何重要動態。
資料來源



