強過Nano Banana ? GPT-Image-2 正式發布!實測網上流行的三種玩法
視覺生成進入「文字時代」!GPT-Image-2 不僅修復了色偏與亂碼,更透過推理能力實現角色一致性與精準 UI 生成。本文結合 LMSYS Arena 榜單數據與最新測試案例,為你分析這款「生產力級」AI 工具的商業潛力。


回顧過去的 AI 圖像生成技術,它們在處理「視覺美感」上已經相當出色,但卻始終跨不過「精確資訊」的門檻。只要畫面中出現文字、招牌或複雜的 UI 介面,往往會生成一堆無法閱讀的拼貼亂碼。這導致 AI 產出的圖片通常只能當作「靈感草圖」,企業仍需耗費大量人力進行後期的文字重繪與排版。
然而,GPT-Image-2 的發布徹底改變了這個局面。它將文字渲染準確率從過去的 90% 大幅提升至驚人的 99%。這意味著,當你要求 AI 生成一份包含特定單字的墨西哥餐廳菜單,或是一張標示清晰的歷史地圖時,它能直接輸出毫無錯漏、甚至連小字號圖例都清晰可見的成品。
這正是從「純視覺」到「精準信息」的巨大飛躍。AI 圖像生成長期以來的最大痛點——文字失真,終於被正面解決。這款工具不再只是單純的「產圖軟體」,而是真正能將視覺素材直接轉化為「可交付商業資產」的生產力基礎設施。
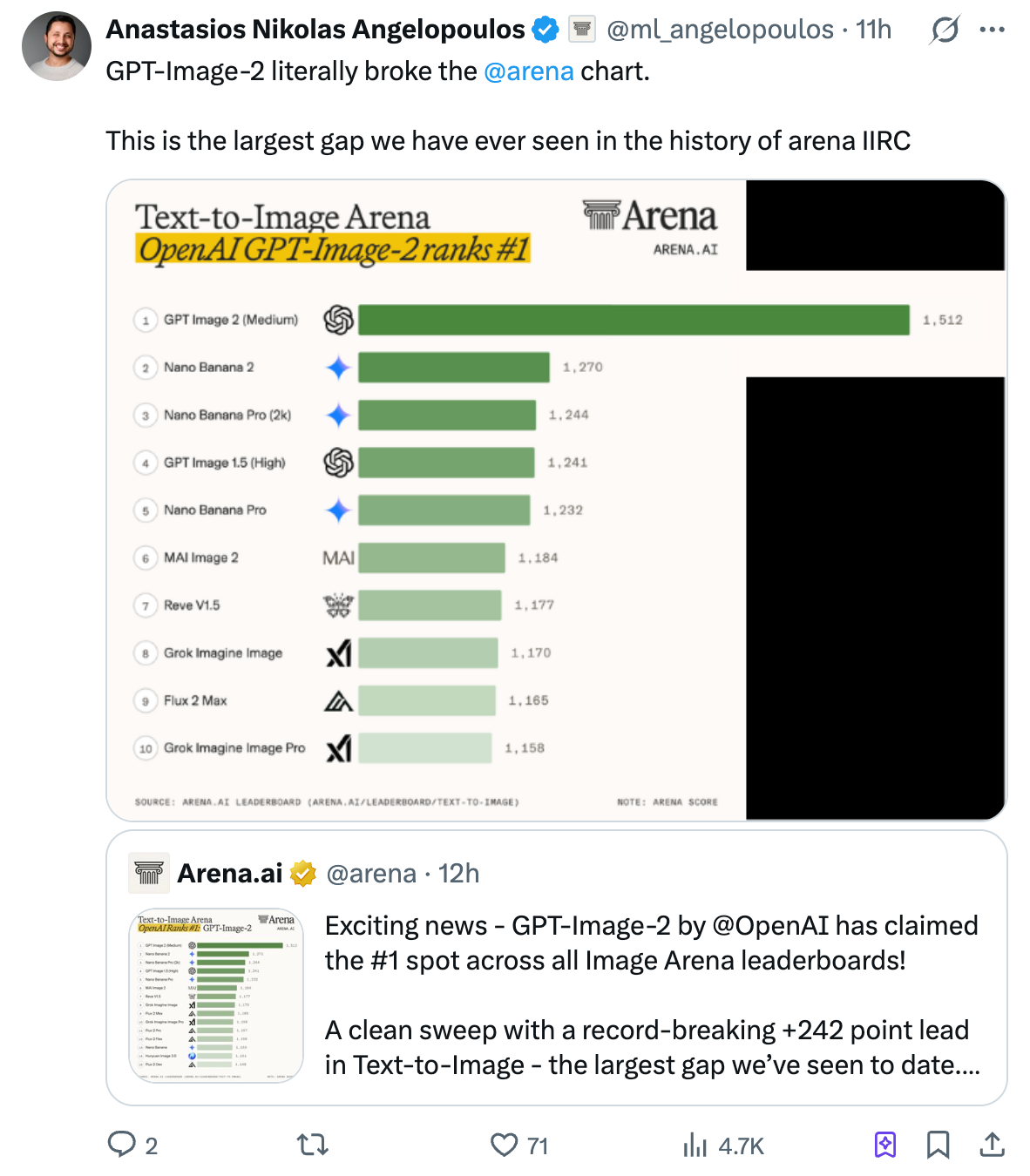
GPT-Image-2 的三大核心技術革新
為什麼這次的升級能徹底解決長久以來的「文字幻覺」與「畫面假感」?這並非單純的參數微調,而是底層技術的全面重構。以下為大家拆解 GPT-Image-2 的三大核心技術突破:
1. 全新獨立架構:從「先聽再畫」到「邊理解邊畫」
根據 OpenAI 研究負責人的定義,GPT-Image-2 放棄了過去依附於多模態模型的路徑,成為一個從頭設計的「GPT for images」獨立系統,將以往的兩階段生成轉變為單次推理。
GPT-Image-2像是和你並肩作戰的設計師,採用「邊理解語意邊作畫」的模式。在生成每一個像素的當下,模型都清晰地知道自己正在「寫什麼字」、「畫什麼結構」,這正是其文字渲染準確率能逼近 99% 的根本原因。
2. 獨創 Thinking 模式:具備「自我審查」能力的 AI
GPT-Image-2 是業界首個將「推理能力」與「網頁搜索」整合進視覺生成的模型(目前鎖定於 Plus 及以上付費層級)。
開啟 Thinking 模式後,AI 就像內建了一位嚴苛的藝術總監。在正式落筆前,它會先在腦中「規劃構圖」;在生成過程中,它會主動「檢查自身輸出」。如果它發現招牌上的單字拼錯了,或是人物比例不對,它會自動進行內部迭代與修正,確保最終交付到你手上的圖片是精確無誤的。在單次指令中,它甚至能維持最多 8 張圖片的角色與風格一致性。
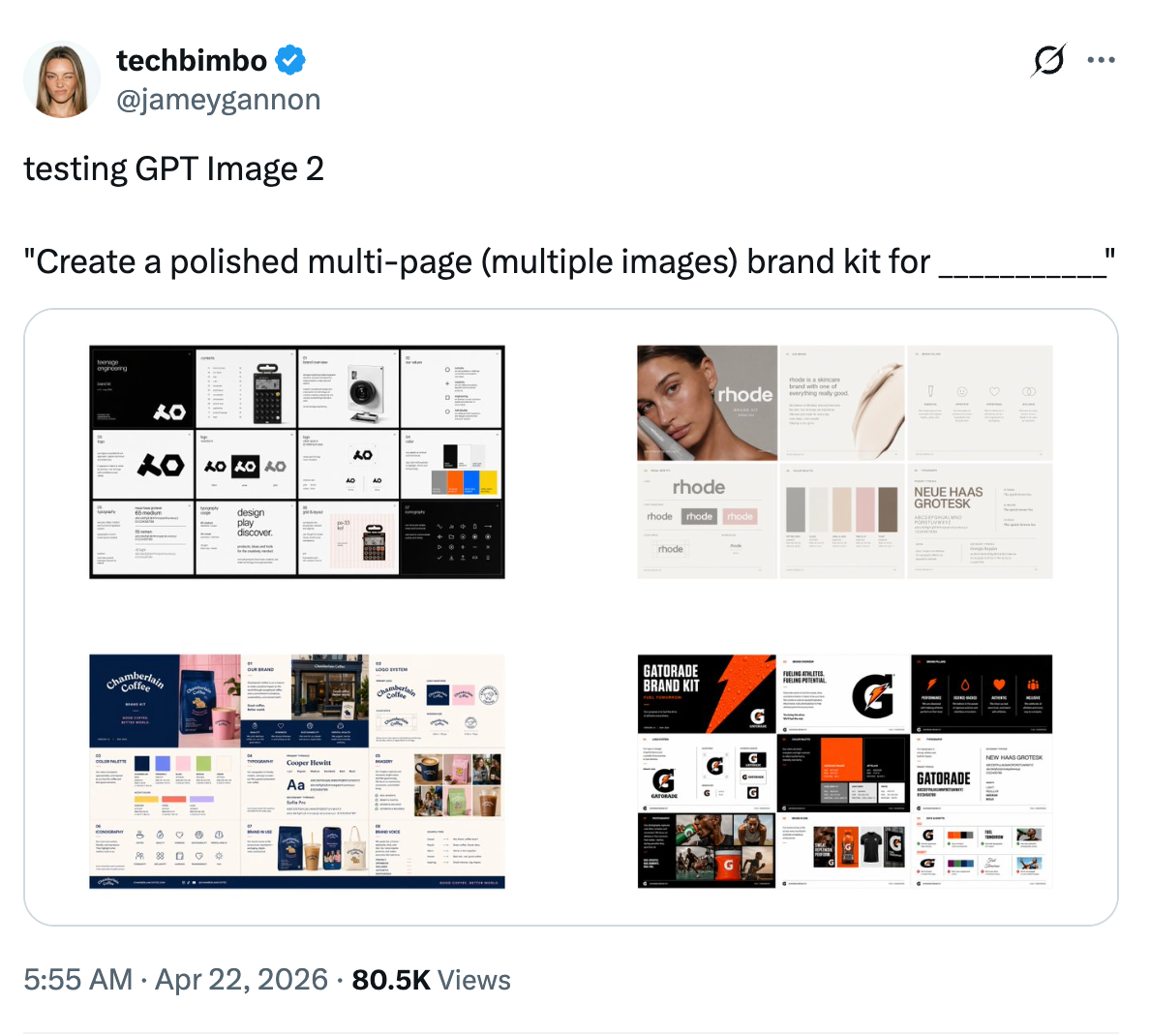
3. 深度世界知識更新:精準還原物理與空間邏輯
不僅將知識庫更新至 2025 年 12 月,其訓練數據更高度偏向真實世界的視覺素材,如 UI 截圖、店面招牌與軟體介面佈局。
新模型不再單純依賴過往的圖案去「瞎猜」,而是真正理解了現實世界的物理邏輯。當你要求生成「一位軟體工程師的工作螢幕」時,它不會像過去那樣敷衍地貼滿駭客任務般的綠色亂碼,而是會精準輸出具備說服力的開發者介面(IDE)、清晰的程式碼排版,甚至連旁邊的資料夾佈局都完全符合真實電腦的運作邏輯,產出可直接作為商業 Mockup 提案的高質感畫面。
三個實用玩法,讓圖片生成真正進入工作流
現在的 AI 圖片模型,已經不只是「畫得漂亮」,而是真正能幫助工作提效。尤其在文字生成、角色一致性,以及局部修改能力上,表現比過去穩定非常多。現在甚至可以直接生成大量文字的食譜圖、UI 草圖與各種風格化設計稿,連細節文字都能直接拿去開發使用。以下分享三個最值得實際應用的玩法。
還想解鎖更多精彩內容嗎?
完整內容只開放給註冊用戶✨
點擊下方「Subscibe now」,立即加入我們! 是免費喔~



