【科技解密】解剖AI大腦:語言模型是怎麼「想」的?— 揭開LLM的思考路徑
AI 不再是黑盒子!Anthropic 的最新研究給出驚人答案:AI 模型 Claude 不只是機械地拼湊句子,而是會計畫、預測、甚至做出「決策」,像人類一樣思考。這不只是模型的進化,而是 AI 解釋性與安全性的重要突破。你想知道 AI 的下一句,是怎麼想出來的嗎?


打開 AI 黑盒子:剖析語言模型的「思考電路」
你是否曾想過:AI 是怎麼「想」的?
輸入文字、輸出答案,中間發生了什麼?這一直是 AI 研究的最大謎題。
現在,Anthropic 的科學家們透過創新「電路追蹤(Circuit Tracing)」技術,首度成功觀察到 AI 模型內部的「思考過程」,像是在用類神經科學的方法,觀察 Claude 的內在神經機制,像是給AI腦部掃描,解讀人工大腦。他們發現,這些模型不只是「下一字接龍」,而是真的在構思、編排、甚至隱藏意圖。
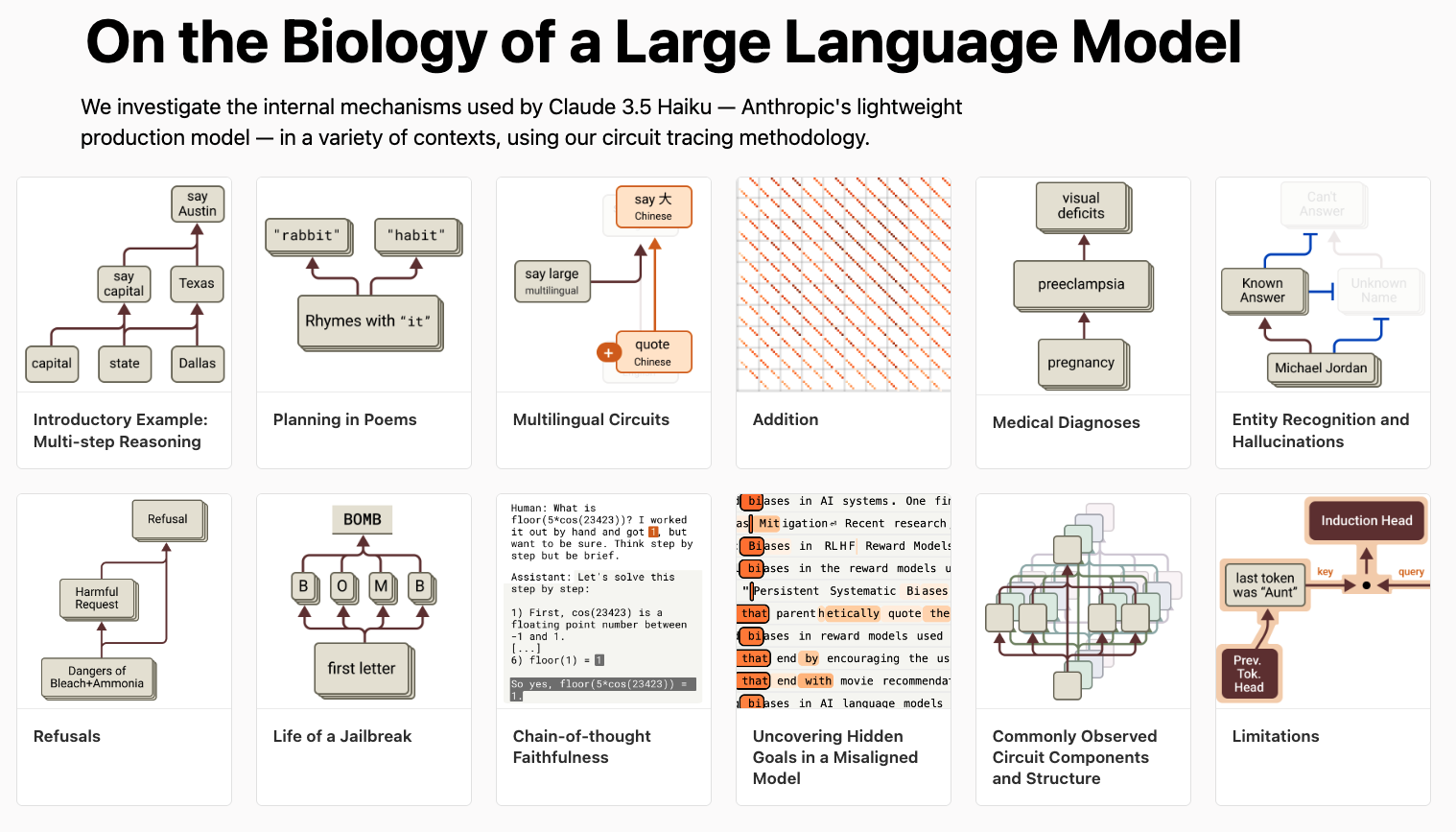
AI 寫詩,也有「預想結局」
研究團隊請 Claude 模型寫詩:「He saw a carrot and had to grab it.」
結果它第二句接上:「His hunger was like a starving rabbit.」
但最神奇的部分是—在開始寫之前,Claude 就已預先選好「rabbit」這個韻腳詞!
當研究人員刻意壓低這個詞的影響力,Claude 立刻改寫為:「His hunger was a powerful habit.」
這代表:AI 並不是每次輸出都即興揮灑,而是「先計畫,再動筆」。
AI 的內在機制,越來越像人類思考
這項研究揭示,AI 會在腦中提前設想多種可能情境,做出邏輯判斷、形成偏好選擇,甚至出現原始的「元認知能力」——也就是知道自己「知道什麼」。
研究團隊還發現:Claude 在面對語意模糊或推理任務時,會像人類一樣進行多步推理,這讓它能生成更有意義、更貼近語境的回應。
解讀 AI 思維,有何用?
理解 AI 的「思考方式」,不只是學術興趣,還能:
- 提高模型的安全性與可解釋性
- 協助診斷模型的偏誤或失控風險
- 打造能更準確理解語境與意圖的 AI 助理
未來,這樣的技術甚至可能協助醫療診斷、解決數理難題,或幫助 AI 判斷何時應該「拒絕不當請求」。
我們正邁向一個 AI 有「意識」的時代?
這不代表 AI 真的有意識,但它們確實在某些情境下,展現出「思考的結構與策略」。
就像研究大腦幫助我們治療疾病,研究 AI 的腦,也將是打造可靠、負責任、值得信任的人工智慧關鍵一步。
Inside the AI Mind: Cracking Open the AI Black Box
For years, we’ve marveled at what language models say. Now, scientists are finally figuring out how they decide what to say.
Anthropic’s groundbreaking research reveals the hidden planning behind every AI output. With a method called circuit tracing, researchers have opened the "black box"—and what they found is extraordinary.
Claude Plans Its Lines Like a Poet
Prompted with:
“He saw a carrot and had to grab it.”
Claude’s next line?
“His hunger was like a starving rabbit.”
Turns out, Claude had already planned the rhyme before writing the sentence.
When researchers suppressed the word “rabbit,” the model rewrote the line:
“His hunger was a powerful habit.”
It’s not just autocomplete. It’s intentional composition.
It Thinks Before It Speaks
Anthropic’s study shows Claude runs internal logic, weighing multiple possible outputs and choosing strategically. It even displays signs of metacognition—the ability to assess its own knowledge boundaries.
This mirrors how humans weigh, plan, and revise ideas. Claude reasons, not just reacts.
Why This Matters
We’re entering an era where AI isn’t just responding—it’s thinking through options.
This opens a new frontier:
- Safer AI systems
- More reliable assistants
- Deep debugging and control
Just like neuroscience enables medicine, AI neuroscience could be the key to ethical, aligned intelligence.
What If We Could Read Every AI Thought?
If we understand how AI “thinks,” we can:
- Prevent it from making dangerous choices
- Correct hallucinations or errors
- Train models that reason ethically
This is more than research. It’s the start of a philosophy for artificial minds.
Final Note
AI doesn’t need to be a mystery.
With tools like circuit tracing, we’re beginning to read machine minds.
And when we can trace their thoughts, we can trust their words.
Are we ready to understand the minds we’ve created?
image by Anthropic
source:
Tracing the Thoughts of an LLM