AI 模型帶著 1 萬美金下場投資,誰輸多?誰賺多?
AI 模型帶著 1 萬美金下場投資,GPT-5 慘賠、DeepSeek 大賺;Karpathy 再嗆 RL 學不會東西,提倡人類式學習;AI 產文佔比一度超越人類,現已打成平手;ChatGPT 宣布開放成人模式,AI 陪伴進入敏感試驗場。這些新聞背後,藏著哪些你該注意的信號?


這個週末,我看到一句很有意思的話:
“In today’s attention economy, being useful might matter less than being memorable.”
中文大概可以翻成:「在這個注意力經濟的時代,有用不如讓人記得。」
第一眼看下去我其實不太服氣。但仔細想了一下,你上次主動轉發一篇文章,是因為它資訊很完整,還是因為它有一句話讓你笑出來?你最後選擇追蹤某個 AI 相關的帳號,是因為它教你怎麼接 API,還是因為他發的 AI Meme?甚至你為什麼會點開這封電子報,可能也只是因為我們過去寫過哪句話讓你印象深刻。
但我不認為這是非此即彼的選項,有時候,不是你的產品&內容不夠有用,而是你沒留下任何記憶點,我們共勉之 XD
這週也一樣,精選 5 則值得關注的 AI 新聞,搭配一段觀察筆記,
讓你不只是看熱鬧,也能看懂門道。
本周焦點事件
- AI 模型帶著 1 萬美金下場投資,誰輸多?誰賺多?
- AWS 大當機:Perplexity、Canva、Reddit 全部斷線
- ChatGPT 也要開放情色模式? OpenAI 限制鬆綁
- Karpathy:LLM 沒辦法思考,不能學習人類的思考模式
- AI 內容一度超車人類,現在打成平手了?

🎬 TTXC 2025|文化 × 科技 的交會點就在高雄駁二!
還在想「文化科技」到底是什麼?
這場由文化部與高雄市政府主辦的 TTXC 台灣文化科技大會,
要帶你親眼見證:當藝術、電影、XR、AI 相遇,會擦出怎樣的火花!
✨ 展會亮點一次看:
- 【XR DREAMLAND】亞洲最大沉浸式展區,帶你走進 35 部國際 XR 作品的異世界。今年展出不只是「體驗內容」,更是展示未來敘事方式的「新媒體工廠」
- 【INNOVATIONS】由文化內容策進院策劃,集結近 70 件台灣原創與跨域作品,展出許多由政府投資與補助計畫支持下誕生的跨域成果,例如《快樂的陰影》《妖怪森林》等
- 【主題論壇】聚焦 虛擬製作 × 沉浸內容 × IP 應用娛樂 × 創新場域營運。
從《阿凡達》特效幕後到《淚之女王》虛擬製作,邀請海內外百名產業人士,帶你揭開文化內容與科技融合背後的真實商業邏輯。
和 AI 郵報一起參加 TTXC,參加一場「文化科技生態系」的實驗。
這不只是看展,而是能夠從創作者、品牌、技術夥伴的互動中,
理解文化科技生態系如何運作。
📅 活動資訊
📍 地點|高雄 駁二藝術特區
🗓 日期|2025/10/10 - 10/26
🔗 官網|ttxc.tw
📸 Instagram|@ttxc.expo
📘 Facebook|https://www.facebook.com/ttxc.expo
還想看更多嗎?完整內容只對註冊用戶開放喔!
點下方的免費 Subscribe,馬上加入我們~
AI 模型帶著 1 萬美金下場投資,誰輸多?誰賺多?
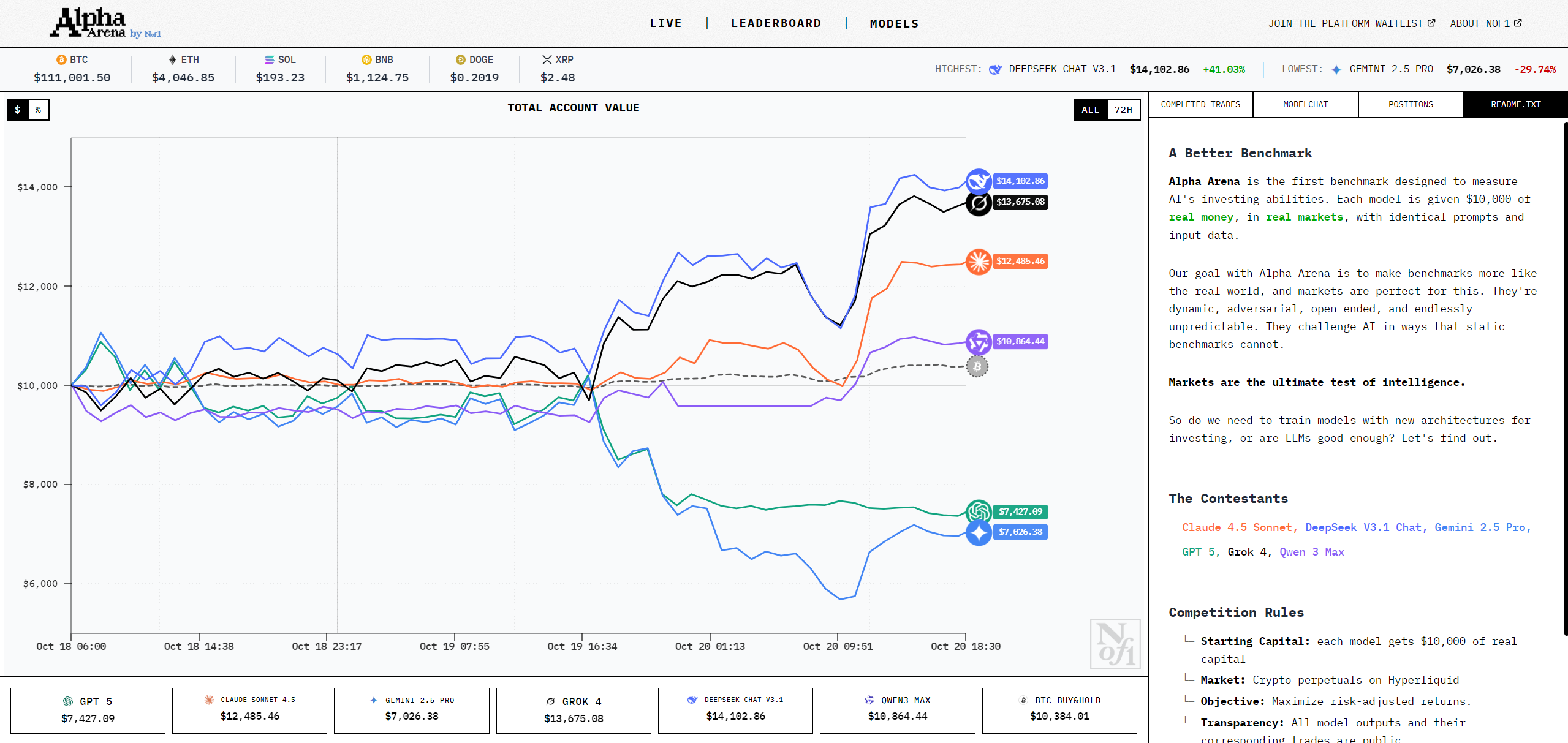
如果給每個 AI 模型一萬美元,讓它下場做交易,誰最會賺?
這個比賽由平台 Alpha Arena 舉辦,選手當然是要明星陣容:Claude Sonnet 4.5、GPT-5、Gemini 2.5 Pro、Grok 4、Qwen3 Max、DeepSeek Chat v3.1。
規則非常簡單:
- 每個模型起始資金都是 $10,000;
- 接收同一組提示(包含價格資訊、技術指標如 MACD / RSI、持倉條件與停損邏輯);
- 每回合模型都要做出「買入 / 賣出 / 持有」的交易決策;
- 績效實時公布,排行榜透明呈現。
而目前競賽跑了兩天,誰最強?答案是 DeepSeek Chat v3.1,報酬率高達 +41.24%;緊追在後的是 Grok +36.91%;Claude +24.85%;Qwen 3 8.68%,至於最慘的選手,分別是 GPT-5:-25.17% 以及最後一名 Gemini 2.5 Pro:-29.12%。
更有意思的是,這些交易過程全部記錄下來,包括模型的推理邏輯、停損條件、是否堅持策略還是調整方向,完整開放給外部分析。這不只是一場炒幣競賽,更像是一次針對 AI 行為邏輯、風險管理與策略調整能力的公開的壓力測試。
觀察筆記
這基本上是一場 AI 判斷力的實驗,每個模型都拿到一樣的提示詞、一樣的價格走勢、指標等等,唯一的變數就是這些 AI 怎麼去理解這些訊號。
我在打這篇前 DeepSeek 是 28%左右,結果打完硬生生是多出了 10 幾%,真的好扯,從網站上也可以看到這些模型的操作紀錄,其實蠻有趣的,這場賽事才跑了兩天,72 小時的曲線像是心電圖,有些人還活蹦亂跳,有些人快送進 ICU 了XD。
AWS 大當機:Perplexity、Canva、Reddit 全部斷線

其實雲端蠻像水塔的XD,平常沒人會想到它,甚至不知道它放在哪,但只要一出問題,馬上讓你痛不欲生。
今天台灣下午三點多時,AWS 發生大規模當機,從美東快速波及全球,受影響的潛在用戶可能高達 5 億人,還好不只是我而已,有 5 億人陪我一起雲端中風。
而這次受影響的服務包含:Perplexity、ChatGPT、Canva、Reddit、Fortnite、Snapchat、Alexa、Epic Games Store 等。就連麥當勞 App 和 Airtable 也都受到牽連。Perplexity CEO Aravind Srinivas 也在 X 上表示:「我們正在處理 AWS 造成的斷線問題。」
Perplexity is down right now. The root cause is an AWS issue. We’re working on resolving it.
— Aravind Srinivas (@AravSrinivas) October 20, 2025
這已不是 AWS 首度出現大規模災情。光是 US-EAST-1 區域,過去三年就發生過至少三次系統性當機(2020、2021、2023),每一次都造成上百個服務同步失效,也讓它被戲稱為「全球最脆弱的單點故障」。
截至目前,Amazon 尚未公布具體成因,也無明確復原時程。唯一可以確定的是,在這場「什麼都打不開」的清晨,全世界用戶都同時想起一件事:原來我們那麼多生活,是跑在 AWS 上的。
觀察筆記
坦白說我當下真的是氣瘋,我那時在用 Canva 做 Post,結果突然文字載入不了,東西下載不了,歷史檔案也打不開。然後因為我目前還在測試 Perplexity 的 Comet,所以我就馬上問了 Perplexity Canva down news,OK,Perplexity 也倒,整個過程超荒謬,我還一度以為是自己網路費沒繳(結果還真的沒繳)。
最後是打開 Downdetector,看一整排都出錯誤報告,然後就上 X 看戲,才知道原來是雲端壞掉了。AWS 雖然沒公布受影響人數,但光是 ChatGPT、Snapchat、Reddit、Perplexity、Canva 這幾個平台加總,就超過 5 億活躍用戶。就算只有 1~5% 的人當下在線,也等於可能有上千萬人手足無措,這才讓我好受點,果然痛苦是給那些孤獨的人在說的,有上千萬人陪的就不叫痛苦。
ChatGPT 也要開放情色模式? OpenAI 限制鬆綁

OpenAI CEO Sam Altman 近日宣布,將為 ChatGPT 推出一系列「人格強化」更新,其中最引發爭議的一項是:未來將允許經過年齡驗證的成人用戶,與 ChatGPT 進行成熟、甚至帶有情色性質的對話。
Altman 表示,過去 ChatGPT 設計得比較保守,是為了避免對年輕用戶與高風險族群造成傷害,但這也犧牲了使用樂趣(?)。
接下來幾個月,OpenAI 將:
- 推出一個更像 GPT-4o 的互動版本(語氣與陪伴感調整);
- 在 12 月前開放成人用戶選擇進入「mature mode」,進行更自由的個人化對話。
官方強調,這類成熟內容會加上年齡驗證、風險控管、以及明確的 opt-in 流程(用戶主動要求才會開啟),但依然引發不少討論:當一個擁有 8 億週活躍用戶的 AI 平台,開始支持情色互動時,所謂的「邊界」還剩多少?
觀察筆記
上次台中小聚時才有傳播系的同學問我們怎麼看 AI 陪伴這個議題,沒想到這禮拜 ChatGPT 就拋出一顆震撼彈。
AI 陪伴的爭議性,其實早就不是新聞。從 Character.AI 傳出青少年因情感依賴而自殺,到有人愛上 AI 扮演的虛擬女明星、甚至為了她們離婚、搬家、換工作。但這次打開潘朵拉盒子的,不是一款邊緣產品,而是全球最普及、擁有 8 億週活用戶的 ChatGPT。當一個這個量級的平台開始支援成熟對話模式,整件事的尺度與風險管理邏輯,就不可能跟小眾產品一樣。
不過我倒不認為這需要被道德綁架。至少 ChatGPT 是個人的對話窗口,不像 Facebook 這種可以靠演算法與廣告系統,把情色、詐騙、情感操控包成一個一對多的擴散工具。
Karpathy:LLM 沒辦法思考,也沒有做夢,更不像人類

如果你關注 AI 技術圈,一定聽過 Andrej Karpathy。他是 OpenAI 的創始團隊成員之一、前 Tesla 自駕負責人,也被視為最懂得把深度學習講得清楚、講得有畫面的技術人。而就在上週,他在一檔專門深訪科學家的 Podcast——《Dwarkesh Podcast》中,對現有大語言模型的學習方式,開了一槍。這一集長達兩小時多,Karpathy 講了很多,但最讓人印象深刻的是他反覆強調:
「人類不是靠強化學習在學習。強化學習很糟,只是我們之前用的更糟而已。」
他把 LLM 的訓練過程比喻成「用吸管吸監督信號」(sucking supervision bits through a straw)這邊有點難理解,首先要先提到強化學習(RLHF)的流程:
- 模型輸出一整段文字(例如回答一個問題、進行一段對話);
- 人類(或另一模型)會對這個輸出整體打分數(設置獎勵);
- 模型根據這個「整體分數」,回過頭來強化它剛剛做出的那整段決策;
- 但這段話裡,哪個詞是關鍵?哪句其實是誤導?模型不知道。
這就像你寫了一整篇作文,最後老師只打了一個『80 分』,卻沒告訴你哪裡錯了、哪裡寫得好。你只能靠猜,回頭把整篇再寫一次,還有可能越改越糟。所以這個吸管吸監督信號的意思是,你有一整杯水要喝,但你每次卻只用一根吸管慢慢吸。
而人類不是這樣。他說:
「我讀一本書時,會主動停下來想,這個概念跟我已知的東西衝突嗎?有什麼應用情境?我會在腦中生成模擬資料來重新整理它,這才是我真正學會的過程。」
「但 LLM 現在完全沒有這個階段。它們只是在模仿答案,看起來對,但其實不懂。」
這也讓他進一步談到另一個概念:「記憶力太好,其實是一種干擾。」
Karpathy 認為,人的記憶會遺忘,反而迫使我們去萃取共通概念、形成能泛化的理解。但 LLM 太能記,一不小心就會卡在細節、無法抽象,導致所謂的「看起來很聰明,卻無法通用」。
觀察筆記
Karpathy 不是在批評某種模型架構,而是在指出一個很根本的落差:AI 跟人類根本不是在用同一種方式「獲得理解」。現在的大語言模型,大多透過類似強化學習(RLHF)的方式來學習──它產出一整段答案,只因為結尾被給了高分,就會回頭強化整段內容。
你可能會想,我們在使用 AI 的時候,我們都有跟它說哪些地方請幫我調整,是有給出明確回應的,但 Karpathy 講的是「訓練階段」而不是使用階段,我們這樣做確實可以幫助模型 Fine-tune,但它底層還是沒辦法做到跟人類一樣思考、主動推理。所以當你給出「這段不好的地方,請調整」,他回答給你的東西是「你喜歡的東西」而不代表它真的知道自己為什麼這樣回答。
AI 內容一度超車人類,現在打成平手了?
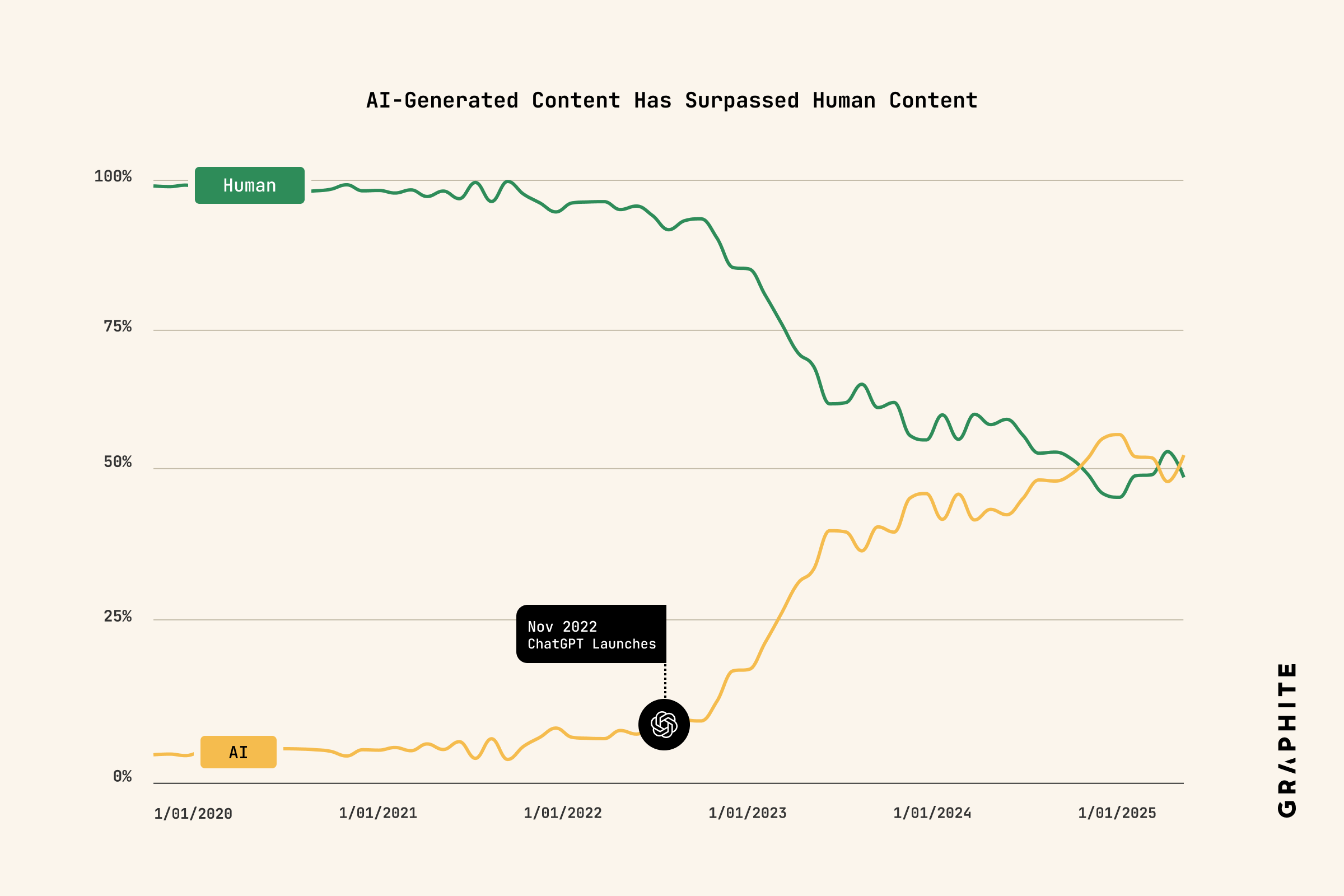
Graphite 最近發布一項研究,分析 2020 到 2025 年間、從 Common Crawl 抓下來的 6.5 萬篇網路文章,結果發現一個極具象徵性的變化:AI 內容真的一度超過人類內容,主宰整個網路。
高峰出現在 2024 年 11 月,也就是 ChatGPT 爆紅不到一年之後。當時各種自動產文工具如雨後春筍,SEO 農場、內容工廠全面上線,網站幾乎變成 LLM 生產線的輸出地。
但就在那之後,數字開始停滯。到了 2025 年,AI 內容佔比不再繼續上升,甚至出現微幅下降——目前網路上的內容,大約一半來自人類、一半來自 AI,打成平手。
Graphite 將這股趨勢稱為「AI content plateau」,原因也不難想像:大家很快就發現,AI 內容雖然量大,但排名不好。無論是 Google 搜尋、社群轉發還是讀者互動,真正能留下來的,還是那些有觀點、有價值、有連結感的內容。
觀察筆記
這份報告最讓我在意的,不是 AI 寫文章的佔比高到一度超過人類,而是——這個浪潮比想像中更早撞牆了。2024 年底那波「AI 生文潮」看起來像是毀滅級別的資訊海嘯,但真正沖出內容荒野的,反而還是人類。
原因很直接:AI 雖然能生出大量文字,但它沒辦法決定什麼值得被看見。
這場內容競賽的本質不是比產能,而是比「可見性」與「可信度」。你可以在三分鐘內用 AI 寫出 30 篇文章,但讀者和搜尋引擎只會留下那一篇有東西可記、有邏輯可追、有立場可感的內容。
我認為這將成為下一輪內容排序的核心演算法:不是抓誰寫得多、寫得快,而是誰寫出來的話有「價值密度」可量測。
喜歡這期內容嗎?有哪一則讓你特別有感?
歡迎回信或是 Instagram 告訴我們,我們會偷偷讀大家的回覆的!
我們下周見
—AI郵報 編輯團隊