Alibaba Qwen3-VL震撼發布! 2小時視頻全掃描,細節定位準到秒,挑戰 GPT5
Qwen3-VL 終極三秒總結 Alibaba 把原本要燒幾百億美元、讓 Google 和 OpenAI 憂心忡忡的「兩小時視頻精準理解 + 視覺數學屠榜」能力,直接打包成免費開源扔到 Hugging Face 上。這不是升級,這是降維打擊。 封閉模型還在賣雲端算力,Alibaba 已經把視覺 AI 的「神經」白送全世界。


Alibaba Cloud 低調發布 Qwen3-VL,全球首個能完整分析2小時視頻的視覺語言模型。這不是小升級,而是視覺 AI 的革命:從掃描短片到精準定位長時序事件,開源視覺 AI 從「跟跑」變「領跑」,Google Gemini 2.5 Pro + OpenAI GPT-5 企業夢碎,2026 年視頻分析市場將血流成河。
2小時視頻全掃描,細節定位準到秒
Qwen3-VL 的殺手鐧是超長視頻理解:在「針尖於乾草堆」測試中,將語義重要畫面隨機插入兩小時視頻(約 100 萬 Token),模型精準定位並分析,準確率 100%(30 分鐘視頻)與 99.5%(兩小時)。
The Decoder 指出,這超越大多數視覺語言模型的連貫分析能力,僅與 Google Gemini 1.5 Pro(2024 早期版)競爭,但 Qwen3-VL 開源免費;Unite.AI 補充,使用文字時間戳如「<3.8 秒>」取代傳統 T-RoPE,提升時間定位精準度。
從 8,000 Token 擴展到 256,000 Token 上下文,讓模型一口氣處理數百頁文件或長視頻,企業用戶直接爽翻:監控視頻故障預測、醫療影像診斷、廣告內容分析,一掃而空。
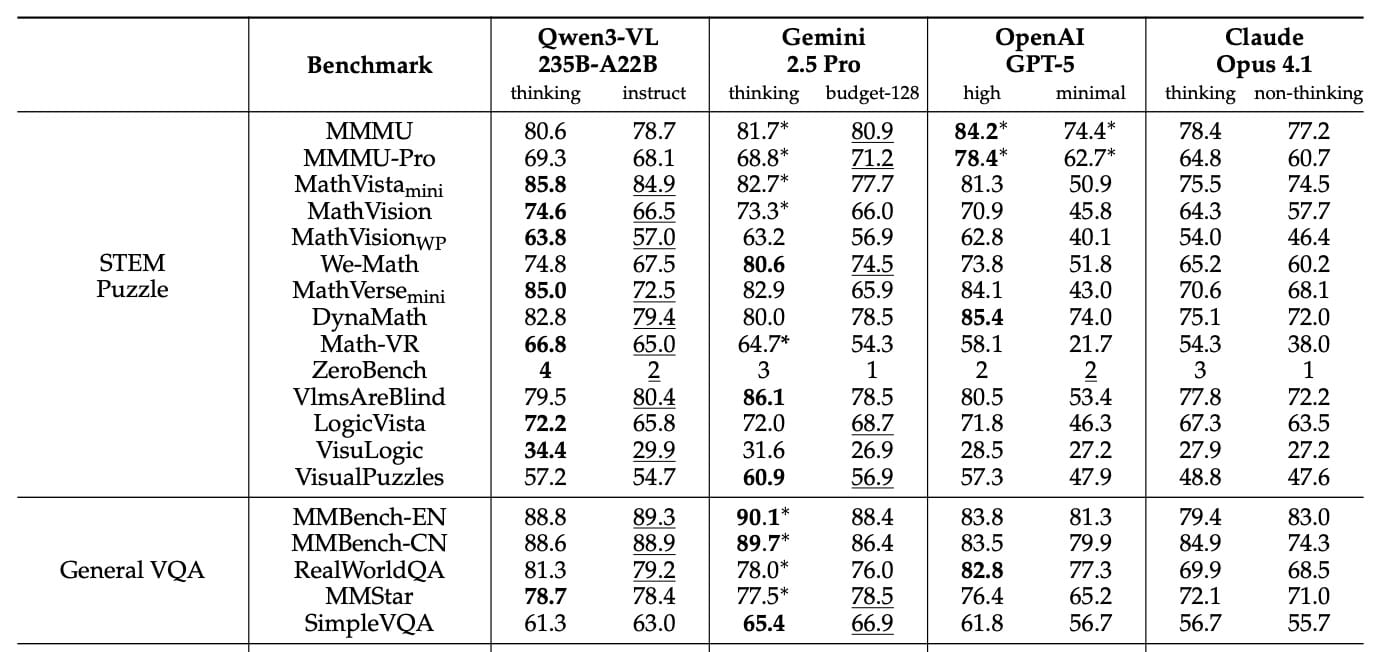
MathVista 85.8% 完勝 GPT-5,OCR 39 語言 70%+ 準確
Qwen3-VL 在視覺數學領域稱王:MathVista 準確率 85.8%,領先 GPT-5 的 81.3% 與 Gemini 2.5 Pro 的 73.3%;MathVision 74.6%,完勝 GPT-5 的 65.8%。這得益於訓練階段的 6000 萬 STEM 任務與 300 萬 PDF 資料;文件理解 DocVQA 達 96.5%,MMLongBench-Doc 56.2%,科學圖表 CharXiv 描述 90.5%、推理 66.2%。OCR 支援 39 語言,OCRBench 875 分,32 語言超 70% 準確,遠超 Qwen2.5-VL 的 10 語言。
Unite.AI 強調,這讓 Qwen3-VL 成為教育科技與科學工具的首選,開源下全球研究者可即刻迭代。
Interleaved MRoPE + DeepStack + 文字時間戳,開源家族全覆蓋
Unite.AI 詳細拆解三項創新:Interleaved MRoPE 均勻分佈時間/寬/高維度位置嵌入,提升長視頻處理;DeepStack 融合多層 Vision Transformer 中間結果,提供細粒度視覺細節;文字時間戳取代 T-RoPE,簡化時間對齊。
訓練分四階段,用 10,000 GPU 處理 1 兆 Token(網路爬取 + 300 萬 PDF + 6000 萬 STEM 任務)。家族包括密集變體(2B/4B/8B/32B)與專家混合(30B-A3B/235B-A22B,471 GB),Apache 2.0 開源 Hugging Face 下載,8B 變體超 200 萬次。
The Decoder 指出,GUI 代理任務 ScreenSpot Pro 61.8%、AndroidWorld 63.7%,開源下研究者可自由擴展。
中國 5.15 億用戶 + 全球 3 億下載,Gemini/GPT-5 企業夢碎
Qwen3-VL 延續 Qwen2.5-VL 的 2800 引用熱潮,Unite.AI 預測將加速教育/科學應用,中國 5.15 億生成式 AI 用戶 + 全球 3 億 Qwen 下載,讓 Alibaba 從跟跑變領跑。
The Decoder 警告,雖然 MMMU-Pro 69.3% 落後 GPT-5 的 78.4%,但視覺專長已縮小開源/封閉差距。
2026 年視頻分析市場將血洗,企業從 Gemini/GPT-5 轉向免費 Qwen3-VL,Meta/OpenAI 生態壓力倍增。
Source
Qwen3-VL can scan two-hour videos and pinpoint nearly every detail
Alibaba Releases Qwen3-VL Technical Report Detailing Two-Hour Video Analysis