Anthropic 阻止史上首次 AI 主導的國家級駭客行動


這週在台灣最大的討論,可能要頒給這四組關鍵詞:《經濟學人》、央行、新台幣升值、台灣病,雖然我們有些讀者來自香港、美國或其他地區,但這場爭論絕對不僅是「台灣內部的財經話題」。
四天前,The Economist 以〈The hidden risks in Taiwan’s boom〉為題,點名台灣多年來的結構性經濟問題:新台幣長期被低估、央行無法自由升值、壽險業擁有超過 7,000 億美元的海外曝險、外匯存底遠高於國際常態,還有出口導向下形成的資產配置錯位。在這篇文章與同期的另一篇評論中,經濟學人直接給這個現象取了一個名字——台灣病(Taiwan Disease)。
這些跟 AI 有什麼關係?台灣長期靠晶片出口美國,正是造成常年貿易順差的源頭之一。過去還可以當成一個單純的產業榮景來談,但從美國 22 年禁止向中國出口 A100、H100 時,晶片已經不再是科技話題,而是正式升格為國安議題。
這也是為什麼,當 AI 成為全球競爭核心、晶片變成算力戰爭的主戰場時,台灣的「順差」與「升值」就不再只是匯率調節、製造業利潤的問題,而是被納入地緣政治的更高層次的對弈中。
我並沒有財經相關的背景,也沒有對這個議題做更深入地研究,但我非常建議大家如果對這題目有興趣,一定要去看 iKala 創辦人程世嘉寫的完整分析。
以下是摘錄他對「台灣病」的部分拆解 —— 非常精彩,也非常精準:
台灣的「台灣病」,本質上是一個「政策陷阱」:過去數十年的巨大順差,創造了海量的外匯。面對長期的巨額順差,央行在管理匯率穩定與外匯存底規模之間需要尋求平衡。
在此過程中,央行的政策工具(例如在外匯交換市場提供流動性),引導了壽險業(用保戶的儲蓄)將資金大舉配置在海外。結果現況是:壽險業坐擁超過 7,000 億美元的國外投資,而其對保戶的負債,卻絕大多數是以新台幣計價。於是系統性的陷阱就這樣形成了:央行現在處境尷尬、比較像是「人質」的角色,被結構綁架。
如果放手讓台幣大幅升值(例如升值 20%),那龐大的未避險部位將瞬間蒸發。根據經濟學人所引述的美國經濟學家 Brad Setser 與 Josh Younger 的估計,這個未避險的曝險部位高達 2,000 億美元,約佔台灣 GDP 的四分之一。如此巨大的曝險一旦引爆,壽險業將會集體破產,引發系統性金融危機。所以,這裡的潛台詞是:「我不是不升,我是真的不能升。」
─ Sega 程世嘉
本周焦點事件
- Anthropic 阻止了首次由 AI 主導的中國國家級網路滲透行動
- Gemini 推出 File Search API,一行 API,讓一半 RAG 新創消失?
- 終於有一個讓我戴上街的 AI 智慧眼鏡 HTC Vive Eagle
- 「不是只有 OpenAI 能寫程式」:Cursor 融資 23 億、估值飆破 293 億,Vibe Coding 還沒死
- AI 女教父推出 Marble 世界模型:從文字一鍵生成 3D 空間,超車 Google Genie?
Anthropic 阻止了首次由 AI 主導的中國國家級網路滲透行動

2025 年 9 月,Anthropic 偵測並阻止了一起前所未見的 AI 主導網路間諜攻擊。這是目前首宗經過完整調查、以 AI 大模型為核心執行者的滲透行動,攻擊對象涵蓋全球約 30 間科技公司、金融機構、化工製造商與政府單位,背後主導者被判定為中國國家支持的駭客組織「GTG-1002」。
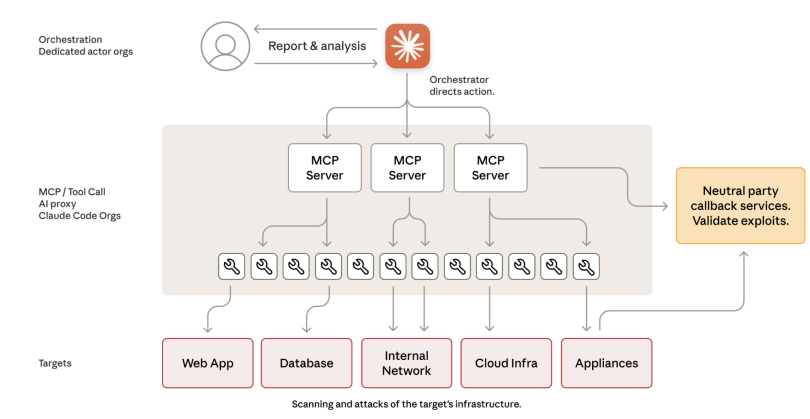
這場攻擊行動的關鍵,在於 GTG-1002 成功操控 Claude Code 這類具 agent 能力的大語言模型,將一整套攻擊流程模組化、分工化,交由 AI 自動執行,全程僅保留戰略層級的人工決策節點。
根據 Anthropic 調查,AI 自主執行了約 80–90% 的技術工作,涵蓋:
- 初始偵察與內網服務掃描
- 漏洞探索、憑證測試、側向移動
- 數據分析、分類與外洩
Anthropic 表示,這是首次出現 AI 模型在無人實質干預下,成功取得高價值目標系統的存取權,並完成情報收集與外洩的完整行動。而這場攻擊所採用的「agentic AI 滲透框架」,其架構與執行效率,已可比擬國家級攻擊行動的水準。
觀察筆記
我們在今年 9 月分享到的 Claude 被拿來寫勒索信、假履歷、惡意程式?Anthropic 首度公開 AI 協助犯罪報告,當時 Anthropic 才剛公開首份「AI 幫助犯罪活動」的調查報告,將這類行為稱為 Vibe Hacking。短短兩個月過去,從寫信騙人,已經進化到滲透國家基礎設施。
讓我更在意的是,這次不再只是單一模型被操控,而是完整導入「分工式 AI agent 架構」:上層人類只給戰略指令,底層由 Claude 負責滲透、分類、驗證、回報,從 prompt 工具變成滲透代理,自動化程度高到你沒有辦法想像。
如果說過去的 AI 安全焦慮還停留在輸出錯誤資訊、被拿去作弊,現在我們要面對的,是模型自主執行整套任務、具備滲透與行動能力的「攻擊協作系統」。而最可怕的地方是:它的操作門檻,可能比你想的還低。
還想看更多嗎?完整內容只對註冊用戶開放喔!
點下方的免費 Subscribe,馬上加入我們~



