OpenAI 團隊公開內部工作流程!Codex 團隊 PM:只做短期、長期方向靠感覺,中期計劃毫無意義


上週假日跟朋友出去,他突然問我:「現在 AI 自媒體這麼多,你們會不會受到很大的影響?」
我想了一下,跟他說了一個夜市理論。
台灣夜市同質性太高,這不是新問題——十年前就有人在抱怨了。臭豆腐、雞排、杏鮑菇、地瓜球,每攤賣的東西幾乎一樣,配方也越來越 SOP 化、加盟化。但你看夜市有沒有少人去?沒有。甚至還有人從夜市出家,開出旗艦店,做出品牌,最後反過來收加盟。
AI 自媒體的爆炸,我覺得跟這個邏輯很像。工具民主化之後,進入門檻變低,同質性當然會上升。但門檻低不代表上限低。同樣用 AI 產內容,怎麼選題、怎麼把一個素材發揮到它應有的深度、怎麼維持一種讓讀者產生聯想的風格——這些東西,AI 沒辦法幫你決定。
對我來說,這才是真正的媒體修羅場。
所以與其擔心「會不會被取代」,我更在意的是:這期的內容,有沒有讓你讀完之後產生新的想法 or 對某件事情有優化或發展的慾望? 如果有,那就夠了。
(發現很久沒發這種心得的前言,所以水一下 XD)
好,收心。讓我們一起快速掌握本週五件最值得關注的 AI 大事!
本周焦點事件
- OpenAI 團隊公開內部工作流程!Codex 團隊 PM:只做短期、長期方向靠感覺,中期計劃毫無意義
- Anthropic 一週兩次資安失誤:Claude Code 50 萬行原始碼裸奔
- 別再把一堆檔案丟給 AI!OpenAI 共同創辦人分享 LLM WIKI,打造你的知識管理系統
- Microsoft 打造了吵架擂台!讓 Claude 跟 ChatGPT 互相打臉就能提高準確度?
- Google 開源新王牌:Gemma 4 來了,免費用到飽的 AI 成為地端新解決方案!

「活動推薦」線上 Webinar:AI Agent 時代來臨 — 從 GitHub Copilot 到 AI-Native Development
AI 正在重新定義軟體開發的本質。從單純的程式碼輔助,到能理解需求、自主執行任務的 AI Agent,企業正全面加速邁向「AI-Native Development」的新階段。
為什麼這場值得去
這場活動從「趨勢」到「工具」再到「實務應用」,完整呈現 AI 驅動開發的關鍵轉變。內容涵蓋 GitHub Copilot 與 AI Agent 的進化路徑、Agentic DevOps 端到端開發流程、GitHub × Azure 的企業級整合應用,以及企業實際導入 AI 開發流程的案例拆解。講者涵蓋平台技術與實戰兩端,不只給你趨勢方向,也給你可以帶回去落地的設計思路與操作策略。
完成報名並參與活動,還有機會抽中 500 USD Azure Sandbox Credit(共 10 名)。
適合誰來
- 負責技術決策與數位轉型的企業主管(CTO/CIO/IT 主管)
- 軟體工程師、開發者、Tech Lead 與架構師
- 正在打造 AI-Native 產品的 PM、產品經理與新創團隊
- 想掌握 AI Agent 與 GitHub Copilot 最新發展動向的所有人
時間: 2026 年 4 月 16 日(四)下午 2:00–4:30
活動形式: 線上 Webinar(免費參加)
主辦: Microsoft
協辦: AIPost、零壹科技、Microfusion
OpenAI 團隊公開內部工作流程!Codex 團隊 PM:只做短期、長期方向靠感覺,中期計劃毫無意義

前天,OpenAI Codex 團隊 PM Alex 跟開發者體驗負責人 Roman 上了 Peter Yang 的節目,聊他們怎麼用 Codex 開發 Codex 本身、OpenAI 內部工作流程、規格文件怎麼寫、以及他們怎麼看 PM 這個職位的未來。
有趣的是,幾乎同一個時間點,Anthropic 的 head of growth Amole Evasari 也上了 Lenny's Podcast。他分享了 Anthropic 從 2025 年初的 1 億美元 ARR,在 14 個月內成長到 190 億美元( omg)——而他們內部推動這個增長的方式,是用 Claude 自動化幾乎所有的成長實驗。兩家公司的人同一週跑去 podcast,聊的都是同一件事:AI 已經在幫公司經營自己了。

說回來 Codex 這場訪談,有三個點讓我覺得特別值得拿出來聊。
第一,Codex 團隊只規劃近期跟長期,刻意跳過中期 roadmap。
近期是指「八週以內的具體衝刺目標」;長期則是一個方向感的「感覺 vibe」。我聽到他說長期的方向靠感覺,其實非常能理解,因為這些人在實際打造產品的過程中,一定會冒出很多想法,例如「未來 agent 應該可以自己部署、自己監控、不需要人提示」。而對標到現在指數性成長的 AI 產業,中間那段三到六個月的產品路線根本沒有意義,模型能力跳躍的速度,會讓所有中期預測在執行前就過期。
第二,設計師現在寫的 code,比六個月前的工程師還多。
Alex 說 Codex 把「我不會寫 code」這個門檻幾乎消除了,設計師開始直接實作自己的想法,工程師開始做更多設計決策。職涯邊界不是被政策打破的,是被工具悄悄溶解的。Boris 那邊說的也是同一件事——他們內部的 Co-work 系統讓產品設計師、數據科學家都能直接影響軟體開發流程。兩家公司,同一個方向。

第三,招人不看學歷,看你有沒有東西可以連結給他看。
有人 DM 求職,Alex 幾乎不讀 CV,但只要有作品連結他一定點開。他說他根本不記得團隊成員讀哪間大學——「Who cares? Just show me what you built.」在他看來,這個時代最重要的兩個人類特質是興趣跟主動性,AI 會補上你不想做的部分。
觀察筆記
看完這兩場訪談,我一直在想一個問題:如果今天你是一個 PM、一個設計師、或是一個工程師,你現在的位置是在吃紅利,還是已經開始被擠壓了?
Amol 在 Lenny's Podcast 裡提到:工程師產能翻了 2 到 3 倍之後,PM 跟設計師瞬間變成團隊瓶頸。這不是因為他們能力變差,而是因為完成任務的組成,組織運作的結構已經變了,但他們還站在原來的位置。Alex 那邊的訊號也一樣,Codex 團隊的設計師已經在寫 code 了,就是因為工具讓這件事的成本幾乎歸零。
過去「T 型人才」是一種加分項,是履歷上的亮點;現在它開始變成一個篩選條件,因為團隊的瓶頸已經不在工程產能,而在能不能在不同角色之間自由移動的人。所以兩個人給的啟示,我覺得可以濃縮成一句話:跨域不再是你的加分項,是你的基本生存條件。
Anthropic 一週兩次資安失誤:Claude Code 50 萬行原始碼裸奔

上週,Anthropic 發生了一件有點尷尬的事。Claude Code 的原始碼被意外推送到公開的 npm registry,一口氣外洩了超過 1,900 個檔案、50 萬行程式碼。整件事情最弔詭的是,這並不是什麼邊角的設定檔,而是 Claude Code CLI 層的核心程式碼。
開發者社群發現之後,裡面挖出來的東西非常熱鬧。44 個 feature flags、三個未發布的專案,其中包括跨 session 的持久記憶功能,還有一個叫「deep-planning system」的東西,看起來是某種更複雜的規劃模式。內部代號也跟著曝光,「Capybara」對應到一個 Claude 4.6 的變體版本,版本號已經跑到 v8。程式碼裡甚至有一段邏輯是在追蹤用戶對 Claude 說負面字眼的頻率。

但全場最受歡迎的發現,是一個叫 BUDDY 的 AI 終端機寵物。18 種物種、稀有度分級、屬性值包含 CHAOS 跟 SNARK。這個功能從來沒有公開發布過,但它就這樣躺在原始碼裡,靜靜等人發現。

「活動推薦」線上 Webinar:解鎖數據 × 部署 AI — Azure 一站式智慧平台實戰
根據 IBM 最新發布的《2026 企業趨勢》報告,目前僅有25% 的高階主管表示所屬企業目前已經擁有可以獨立作業的代理型 AI 應用;七成主管預估其企業到 2026年底可以具備這樣的能力。換句話說,現在這個時間點,大部分企業還在起跑線上。
為什麼這場值得去
這場活動從「有數據」到「用數據做決策」之間的具體架構與實務,讓你充分了解 數據可以如何展開。同時,內容涵蓋 Azure、Microsoft Fabric 與 AI Agent 的整合架構、零 ETL 加速數據流通、企業實際導入案例,以及從 DevOps 到自動化運維的新一代 AI 開發模式。講者陣容橫跨平台技術與企業實戰兩端,不只給你方向,也給你可以帶回去用的架構思路。
適合誰來
- 正在評估 AI 與數據如何真正驅動營運的企業決策者(CEO/CIO/CDO)
- 負責平台選型與導入策略的 IT、資料或數據相關主管
- 關注 AI 對開發與部署流程的工程師或開發團隊
- 想透過數據提升決策效率的行銷、營運或產品團隊
時間:2026 年 4 月 10 日(四)下午 2:00
活動形式:線上 Webinar (免費參加)
主辦:Microsoft
協辦:Weblink 展碁國際、Microfusion、TenMax、Zeabur、AI 郵報
別再把一堆檔案丟給 AI!OpenAI 共同創辦人分享 LLM WIKI,打造你的知識管理系統
幾天前,前 Tesla AI 總監、OpenAI 共同創辦人 Andrej Karpathy 在 GitHub 上發了一個 Gist,概念他稱為「LLM Wiki」——用 LLM 幫你維護一個會自己成長的個人知識庫。發出去幾天,社群討論就沒停過。
概念本身不複雜。大多數人現在用 AI 處理文件的方式是 RAG:把一堆檔案丟進去,每次問問題 LLM 就從原始資料裡重新找、重新合成、重新回答(相信有百分之八十的人都是這樣用的,包括我 XD )。問題是沒有累積,每次都從零開始。
Karpathy 的解法是在你和原始資料之間加一層持續存在的 wiki。每次你丟進一份新資料,LLM 不只是把它索引起來等你查——它會主動讀取、提取重點、更新相關的概念頁面、標記跟既有內容的矛盾點、強化整體的知識網絡。這套系統還有一個很多人忽略的點:自我健檢。LLM 會定期掃描整個 wiki,找出過時的資訊、孤立的頁面、前後矛盾的說法,主動建議你去補哪些缺口。換句話說,這個知識庫不只是在成長,它還會提醒你它哪裡還不夠完整。
整個架構分三層:raw 資料夾放你的原始材料,LLM 不碰這層;wiki 資料夾是 LLM 維護的 markdown 頁面,你讀、它寫;schema 則是一份設定檔,告訴 LLM 這個 wiki 的結構規則跟工作流程是什麼。
Karpathy 甚至往更遠的地方想——當 wiki 夠大、資料夠乾淨之後,這份知識庫可以直接拿來 fine-tune 一個更小的模型,讓它把你的個人知識庫直接燒進權重裡,變成你自己的私有智慧。
社群反應很快。有人把它 fork 成可以多人協作的 git repo 版本(幫各位找好了);有人說 Karpathy 可能意外發明了一種 AI 時代分享想法的新格式。 也已經有人做出了 llmwiki.app,把整個架構包成開源工具讓人直接上手用。
觀察筆記
我認為「知識複利」這個名詞,只適用於有好的 PKMS (Personal knowledge management system)。在沒有好的系統底下,我們會嘗試去找新潮的 PKM 來滿足我們自己的虛榮心,好像用了最新的工具,就能夠掌握知識,但我相信不只我,過去陳堆的筆記依舊躺在那。
每週我們在讀大量的一手資料——研究報告、podcast 逐字稿、產業新聞、訪談內容。這些東西讀完之後去哪了?大部分進了某個 Notion 頁面、某個瀏覽器書籤、或者直接消失在記憶裡。下一次需要用的時候,你知道你讀過,但你不記得在哪,也不記得跟這次的問題有什麼關係。
這不是個人問題,是結構問題。一個媒體團隊的知識資產理論上應該越來越厚——每寫一篇文章、每做一次研究,都應該讓下一次更快、更準。但現實是,每次都差不多從零開始,因為沒有一個東西在幫你把這些散落的知識編譯成一個可以被查詢、可以被更新、可以被傳承的結構。
Karpathy 解決的正是這件事。他不是在做一個更好的筆記 app,他在做的是讓 LLM 成為你的知識管理員——你負責餵資料、它負責維護整個知識網絡的結構、標記矛盾、提醒你哪裡還有缺口。你的知識庫不只是在成長,它還會告訴你它哪裡還不夠完整。
我一直在想,這套邏輯如果往團隊層面推會長什麼樣子。個人 PKM 解決的是「我讀過的東西不見了」,團隊 PKM 解決的是「我同事知道的東西我不知道」——而後者在媒體團隊裡其實更致命。一個人離職,他腦袋裡的產業脈絡、消息來源、判斷框架,幾乎沒有辦法留下來。這不是個人習慣問題,是整個團隊的知識一直在漏水。
我自己現在的想法是,要先把個人的 PKM 跑起來、優化到一個自己真的在用的狀態,再想怎麼把這個架構複製到團隊層面。因為一個沒有人在用的知識系統,再漂亮也是擺飾。
Karpathy 說「知識的繁瑣維護工作不在於閱讀或思考,而在於書目管理」——LLM 不會厭倦,不會忘記更新交叉引用,一次可以同時處理十五個檔案。換句話說,過去我們沒有好好維護知識庫,不是因為不想,是因為維護本身太花時間、太無聊、太容易被更緊急的事情擠掉。現在這個理由消失了。
Microsoft 打造了吵架擂台!讓 Claude 跟 ChatGPT 互相打臉就能提高準確度?
3 月 30 日,Microsoft 正式宣布為 Copilot Researcher 推出兩個新功能:Critique 與 Model Council。 這是 Copilot Researcher 從「單一模型」走向「雙模型互打免費」的關鍵一步。
具體怎麼運作?Critique 把研究任務拆成兩個階段,一個模型負責規劃、搜尋、整合資料並產出初稿,另一個模型則扮演專業審查員的角色,在報告送出去之前進場檢核。 目前的預設分工是 GPT 起草、Claude 負責審查來源可信度、資訊完整性與引用品質。Microsoft 表示未來這個流程也會支援雙向切換。
Model Council 則採取不同路徑:讓 GPT 和 Claude 同時跑同一個研究題目,再由第三個「裁判模型」讀完兩份報告,產出一份摘要,標明兩個模型哪裡意見一致、哪裡出現分歧,以及各自發現了什麼對方沒注意到的角度。
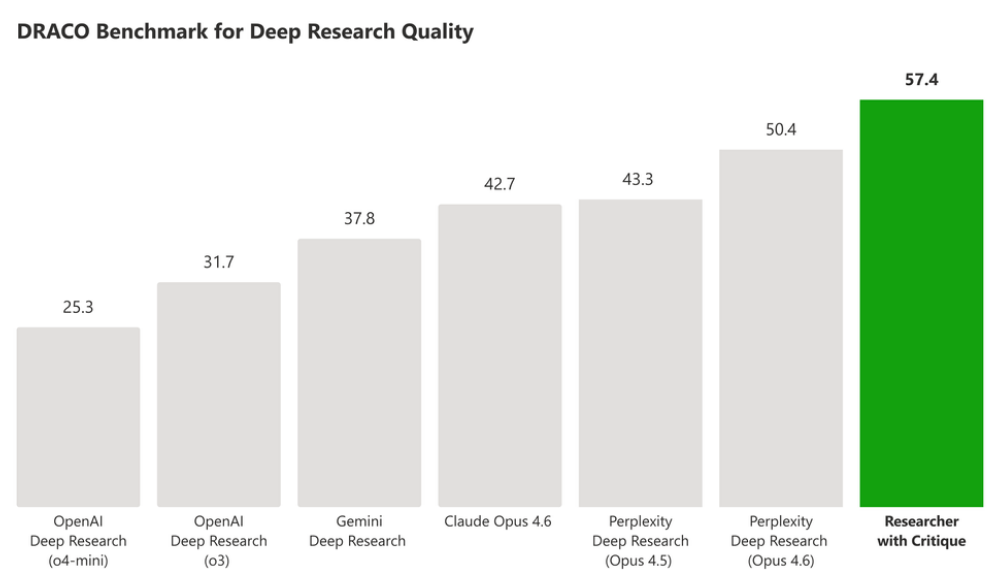
成效數字方面,在 DRACO 研究基準測試中,Researcher 搭配 Critique 的得分比 Perplexity Deep Research 高出 13.88% ——這是 Microsoft 首次公開點名競爭對手做直接比較。進步最明顯的項目集中在分析廣度、報告呈現品質與事實準確度三塊。
但代價不小。Critique 的使用成本比單一模型高出約 20%,Council 則大約貴 2.5 倍。 目前兩個功能僅限每月 25 次查詢,並需要 Microsoft 365 Copilot 訂閱資格加上 Frontier 早期存取計畫,IT 管理員也必須在租戶層級開啟第三方模型存取權限。
同步宣布的還有 Copilot Cowork 正式進入 Frontier 方案。這個以 Claude 為核心的工具主打長時間、多步驟的自動化任務——使用者描述目標,系統自動制定計畫、跨工具與檔案逐步執行,使用者可以隨時監控或介入。
觀察筆記
我想先從一個很具體的使用情境說起。你有沒有做過這件事:把 ChatGPT 的回答貼進 Claude,然後問「這個分析有沒有問題?」——然後 Claude 給你挑出三個漏洞。或者反過來。如果你做過,恭喜,你其實已經在手動跑 Critique 了。Microsoft 只是把這個動作自動化,然後拿去跑 benchmark 證明它有效,順便收你多 20% 的錢XD。
剛好,前面提到的 Andrej Karpathy 前陣子發了一篇 tweet:同一個語言模型,你叫它幫你強化一個論點,它強化得頭頭是道;你叫它推翻同一個論點,它也推翻得無懈可擊。這不是 bug,這是語言模型的根本特性——它非常擅長讓「任何一個方向聽起來都合理」。換句話說,一個模型,永遠都會讓你覺得你是對的。所以你最好問兩個。
當然,社群裡也有人冷嘲熱諷「一個 AI 幻覺,解法是加更多 AI 來投票選哪個幻覺聽起來最專業」。Critique 和 Council 降低的是錯誤的機率,不是把錯誤歸零。而且當驗證這件事也外包給另一個模型,整個迴圈裡還剩多少人類判斷的空間,說實話我也還沒想清楚,但最終判斷誰比較正確,還是到人類這關吧?
Google 開源新王牌:Gemma 4 來了,免費用到飽的 AI 成為地端新解決方案!

4 月 2 日,Google DeepMind 在 Google Cloud Next 正式發布 Gemma 4 ,這是 Gemma 系列迄今最強的一代——四個尺寸的模型,從手機到工作站全都覆蓋,底層技術直接來自 Gemini 3 的研究成果。
先說這次最關鍵的變化:授權改了。 前幾代 Gemma 是「開放權重」但不是真正意義上的開源,使用者不能自由修改或商業再發布。 Gemma 4 改成 Apache 2.0——沒有客製化使用條款、沒有藏在細則裡的終止條款、沒有法律審查的摩擦,這也是 Gemma 系列第一次這樣做。過去不少企業團隊寧可選 Qwen 或 Mistral,原因不是那些模型更強,而是 Gemma 的授權讓法務部門頭痛(用 vLLM 接 Gemma 4 的時候來了!)。
模型本身呢?四個尺寸分別是 E2B、E4B(針對邊緣裝置優化)、26B MoE、以及 31B Dense。 E2B 和 E4B 是最小的兩個,加入了原生音訊輸入,支援語音辨識,並且可以完全離線跑在手機上。 較大的兩個模型則有高達 256K tokens 的上下文視窗,全系列原生支援超過 140 種語言。
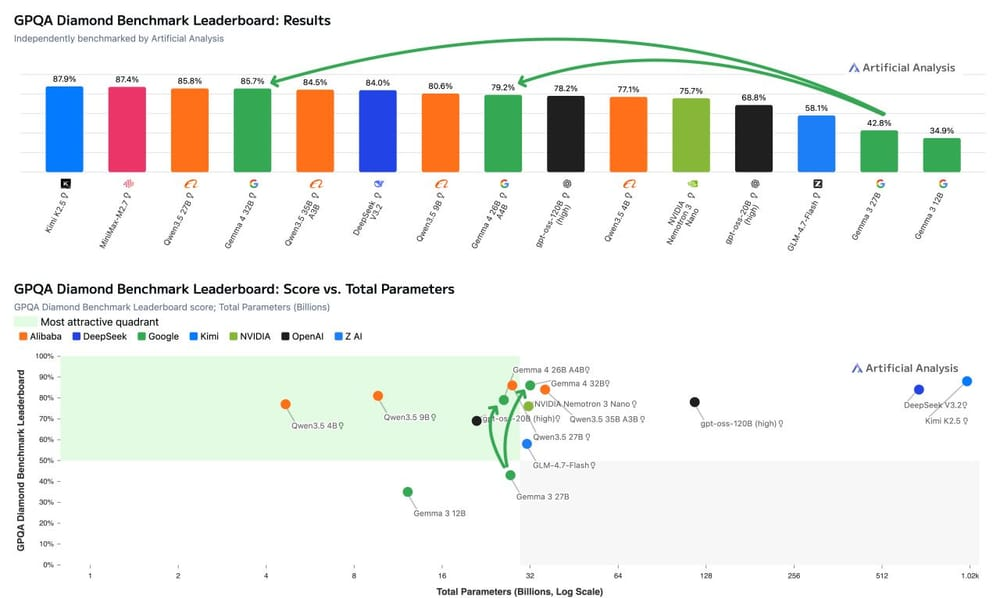
效能數字跳很大。31B 模型在數學推理基準 AIME 2026 拿下 89.2%,上一代 Gemma 3 同測試只有 20.8%;Agent 任務基準 tau2-bench 則從 6.6% 暴增到 86.4%,超過十三倍。 Arena AI 人類偏好排名上,31B 目前全球第三,這不是只跟開源模型比,而是跟所有模型包含閉源商業模型一起排的。
模型目前已上架 Hugging Face,支援 Transformers、llama.cpp、MLX(Apple Silicon)等主流框架,Google 也將 Gemma 4 定為下一代 Gemini Nano on Android 的基礎。
喜歡這期內容嗎?有哪一則讓你特別有感?
歡迎回信或是 Instagram 告訴我們,我們會偷偷讀大家的回覆的!
我們下周見
—AI郵報 編輯團隊



