Claude Opus 4.7 正式發布:程式碼、視覺雙升級,定價不變
Anthropic 於 2026 年 4 月 16 日發布 Claude Opus 4.7,SWE-bench Pro 拿下 64.3% 領先 GPT-5.4 與 Gemini 3.1 Pro,圖片解析度提升三倍,定價不變維持 $5/$25。但新版 tokenizer 最多讓實際成本增加 35%,升級前務必確認。


Anthropic 於 2026 年 4 月 16 日正式發布 Claude Opus 4.7,這是目前對外公開的最強 Claude 模型。程式碼能力與視覺解析度雙雙大幅提升,定價維持不變,但底層 tokenizer 異動讓實際使用成本有所不同,需要留意。
Opus 4.7 的核心升級是什麼
Claude Opus 4.7 是指 Anthropic 在 Opus 4.6 基礎上推出的新一代旗艦模型,model ID 為 claude-opus-4-7,主打三大方向:更強的程式碼解決能力、更高的視覺解析度,以及在長時間自主任務中更穩定的執行品質。
根據 Anthropic 官方公告,Opus 4.7 在進階軟體工程任務上有「顯著提升」,尤其在過去需要人工緊盯的高難度任務上,用戶回報可以放心交手。模型在執行時會主動自我驗證輸出結果,減少需要人為介入糾錯的情況。
值得注意的是,Anthropic 在公告中明確說明:Opus 4.7 的能力仍低於目前未對外公開的 Claude Mythos Preview,後者因安全疑慮僅提供給少數特定企業使用。
程式碼能力:跨平台數據全面領先
程式碼能力是 Opus 4.7 改幅最大的面向。在業界標準測試 SWE-bench Verified(模擬解決真實 GitHub issue)上,Opus 4.7 拿下 87.6%,較 Opus 4.6 的 80.8% 提升近 7 個百分點。
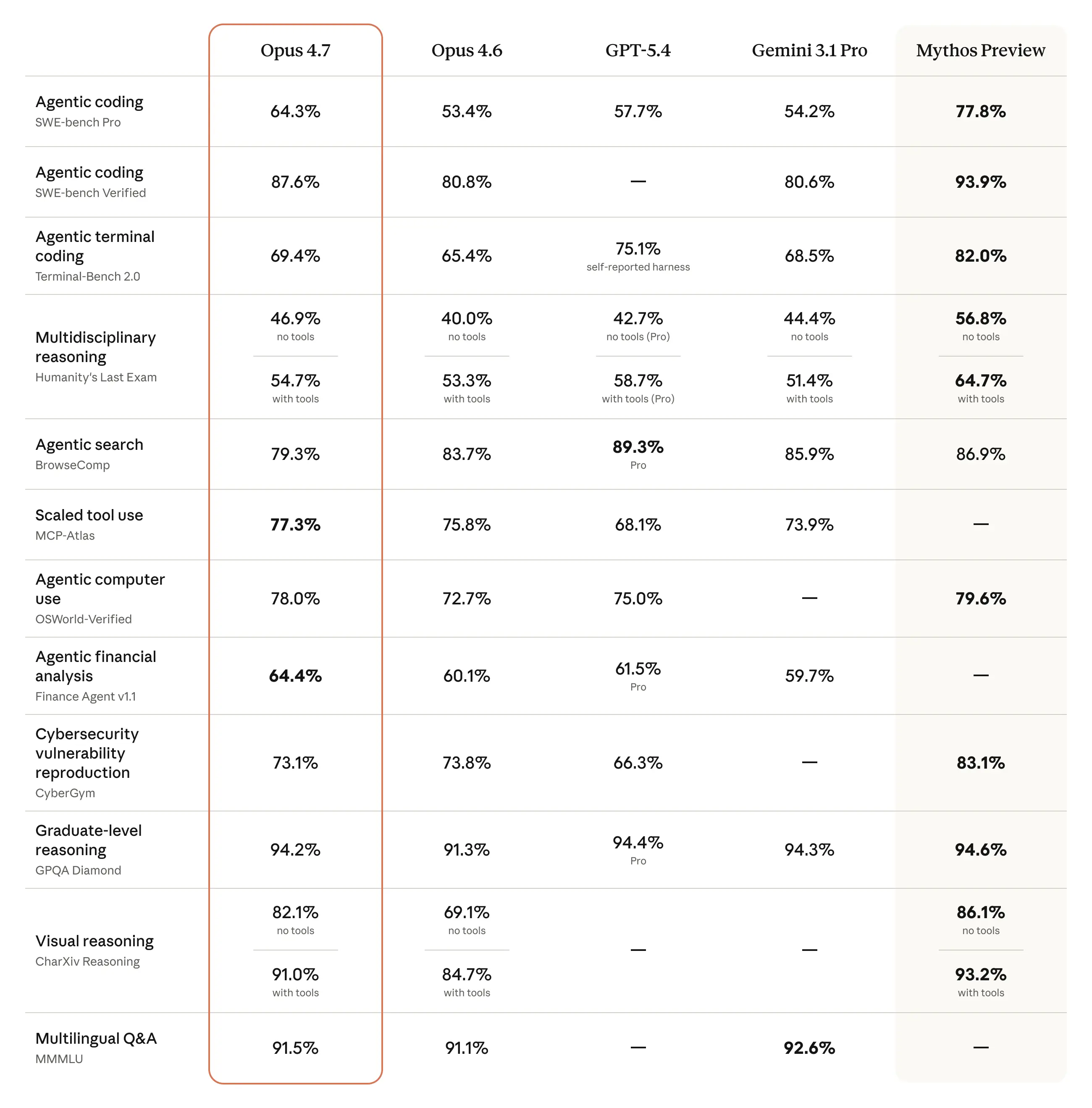
Image Credits: Anthropic
難度更高的 SWE-bench Pro 測試中,Opus 4.7 以 64.3% 居所有公開模型之首,超越 GPT-5.4 的 57.7% 與 Gemini 3.1 Pro 的 54.2%。在 Cursor IDE 內部的 CursorBench 測試上,分數從 58% 提升至 70%,上升 12 個百分點。
來自企業端的實測數據同樣具體。Rakuten 回報解決生產環境任務的數量是 Opus 4.6 的三倍;CodeRabbit 在複雜 PR 的召回率提升逾 10%;另一家金融科技平台指出,Opus 4.7 能在規劃階段自主發現邏輯錯誤,大幅降低後期除錯成本。
另外,Opus 4.7 同步新增兩項開發者工具:Claude Code 中的 /ultrareview 指令,可啟動多 Agent 協作進行程式碼審查;以及目前處於公開 Beta 的 Task Budgets,讓開發者可以為 Agent 的執行迴圈設定步數上限,避免無限循環消耗資源。
視覺能力:解析度直接翻三倍
視覺理解是 Opus 4.7 另一個大幅升級的面向。圖片解析度從 Opus 4.6 的 1,568px(約 1.15MP)提升至 2,576px(約 3.75MP),等於提升了三倍以上的像素資訊量。
實際視覺準確度測試(visual-acuity benchmark)從原本的 54.5% 跳升至 98.5%,這對需要模型讀取截圖、UI 介面、設計稿或文件圖片的任務來說影響顯著。Anthropic 在公告中也特別提到,Opus 4.7 在生成介面、簡報和文件時展現出更強的設計品味與創作質感。
定價不變,但 tokenizer 異動讓實際成本可能偏高
Opus 4.7 的官方定價維持與 Opus 4.6 相同:輸入 $5 / 輸出 $25(每百萬 token)。對於已在使用 Claude 的企業或開發者,這是一個直接升級而無需重新評估預算的訊號。
不過有一點需要留意:Opus 4.7 更換了底層 tokenizer,同樣的文字輸入在新版本下可能產生 1.0 到 1.35 倍的 token 數,也就是說實際帳單最多可能增加 35%。此外,過去用於控制思考深度的 extended thinking budgets(budget_tokens 參數)已被移除,現在改由「Adaptive Thinking」自動決定推理深度,使用者無法像之前一樣手動設定上限。
資安設計:新模型率先測試 Mythos 的防護機制
Opus 4.7 還扮演了一個特別角色:它是 Anthropic 首個搭載新版資安防護機制的對外模型,系統會自動偵測並攔截涉及高風險資安用途的請求。
這項設計的背景是:Anthropic 在 Mythos Preview 上發現該模型具有強大的漏洞挖掘能力,決定先在能力較低的 Opus 4.7 上測試防護邏輯,累積真實部署經驗後再推進至 Mythos 等級的模型。合法的資安研究人員(如漏洞測試、紅隊演練)可透過 Cyber Verification Program 申請驗證,取得對應的使用權限。
Opus 4.7 vs 競品與前代版本完整比較
| 測試項目 | Opus 4.6 | Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | — | 80.6% |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | 54.2% |
| CursorBench | 58% | 70% | — | — |
| GPQA Diamond | — | 94.2% | — | — |
| 圖片解析度 | 1,568px | 2,576px | — | — |
| 輸入定價(/M tokens) | $5 | $5 | — | — |
| 輸出定價(/M tokens) | $25 | $25 | — | — |
在哪裡可以使用 Opus 4.7
Opus 4.7 目前已在以下平台全面上線,無需等候名單:
- Claude.ai:Pro、Max、Team、Enterprise 方案
- Anthropic API:model ID
claude-opus-4-7 - Amazon Bedrock
- Google Cloud Vertex AI
- Microsoft Foundry
- Snowflake Cortex AI
- GitHub Copilot(Pro+、Business、Enterprise)
對於已在使用 Claude 處理企業級程式碼任務的團隊,Opus 4.7 是目前可直接部署的最強選項,不需要等待名單或特殊申請。唯一需要確認的是新 tokenizer 對現有 prompt 的 token 用量影響,建議升級前先以實際使用的 prompt 跑一次成本估算。
想每週掌握最新 AI 工具與趨勢?訂閱 AI 郵報,每週精選重點直送信箱,讓你不錯過任何重要動態。



