Claude Code × Codex 交叉 review 工作流:讓兩個 AI 互相挑錯,不懂程式也能安心上線
這篇拆解我實際在用的 Claude Code × Codex 雙 agent 工作流:從寫計畫、兩邊 review 到一致、Codex 執行到雙重 review 才上線,並說明怎麼用 自製 skill 去交叉review,連看不懂程式碼的人都能安心 vibe coding。


「你那套讓 Claude Code 和 Codex 互相 review 的工作流,到底怎麼跑的?會不會很費工?」
最近跟朋友討論AI工作流,發現這題經常被問到。現今,應該很多人覺得用兩個 AI 寫程式是疊床架屋,但對我這種看不懂程式碼的人來說,這反而是讓我敢把東西上線的關鍵——因為自己寫、自己檢查,太容易覺得「我寫的應該沒問題」。
這篇就把這套工作流一次講清楚:它是什麼、為什麼有效、怎麼實作,以及一個大家最關心的問題——兩個一起用,到底會不會很燒 token。
為什麼一個 AI agent 不夠?
想像一個情境:
你寫完一份考卷,然後由你自己批改。你會發生什麼事?你會傾向相信每一題的答案都是對的——因為那些答案正是你剛剛親手寫下的。錯的地方你之所以會寫錯,往往就是因為你「不知道它是錯的」,所以重看一遍,你大概率還是看不出來。
AI 寫程式,其實是同一回事。
當你讓單一一個 agent 既寫程式、又檢查自己寫的程式,它會落入一種類似「護短」的狀態:傾向認定自己的產出是合理的、邏輯是通的。這是因為它檢查時所依據的判斷標準,和它寫程式時的判斷標準來自同一個脈絡——同一個上下文、同一套假設。盲點之所以叫盲點,是因為你站在原地看不見它,你得換一個位置。
這就是為什麼「換另一個獨立上下文的 agent 來 review」這件事如此關鍵。第二個 agent 沒有參與原本的撰寫過程,它不帶著「我覺得這樣寫沒問題」的預設,而是用一雙乾淨的眼睛,從頭檢視這份程式碼到底有沒有漏洞。
對看不懂程式碼的人,這點尤其關鍵
如果你是工程師,你或許還能自己當第三道防線——AI 寫完、你親自審一遍,憑經驗攔下問題。
但對我這種看不懂程式碼的使用者來說,我根本沒有能力去判斷一段程式碼是好是壞、是安全還是危險。我唯一能依賴的「審查者」,就是 AI 本身。這時候,如果只用一個 agent,等於是把「寫」和「審」兩個責任全壓在同一個對象身上,而我完全沒有能力去驗證它的自我審查到底可不可信。
雙 agent 交叉 review 之所以讓我安心,正是因為它把「執行」與「監督」拆給了兩個獨立的對象。我不需要自己看懂程式碼,我只需要確認兩邊都點頭了——這份成果才會上線。對沒有技術背景的人而言,這是一道你自己給不了、卻又最需要的安全網。
Claude Code × Codex 交叉 review 是什麼?
簡單說,這套工作流就是讓兩個 AI agent 分飾不同角色,在「計畫」與「成品」兩個關卡互相把關,雙方都通過了,東西才上線。兩個 agent 在流程的不同位置,各自扮演「執行者」與「審查者」,並且角色會輪替。
這套做法社群裡已經有相當多的開發者——包含不少資深工程師與 vibe coding 圈的實作派——都在用類似的「雙 agent 交叉 review」模式。
現在就來跟各位說說我是怎麼做的吧!
工作流四步驟
整套流程跑起來,是這樣四步:
- 寫計畫: 我會先跟 Claude Code 聊,讓它把要做的事拆解、寫成一份開發計畫。這一步借重的是它的規劃與思考能力。
- 兩邊 review 到一致: 把這份計畫丟給 Codex 看,讓兩邊針對計畫互相 review、來回討論,直到雙方對「要怎麼做」達成共識。注意:這一步發生在動工之前——先對齊方向,再開始寫,能省下後面大量的返工。
- Codex 執行: 計畫對齊後,交給 Codex 負責實際寫程式。這一步看重它寫程式碼的速度。
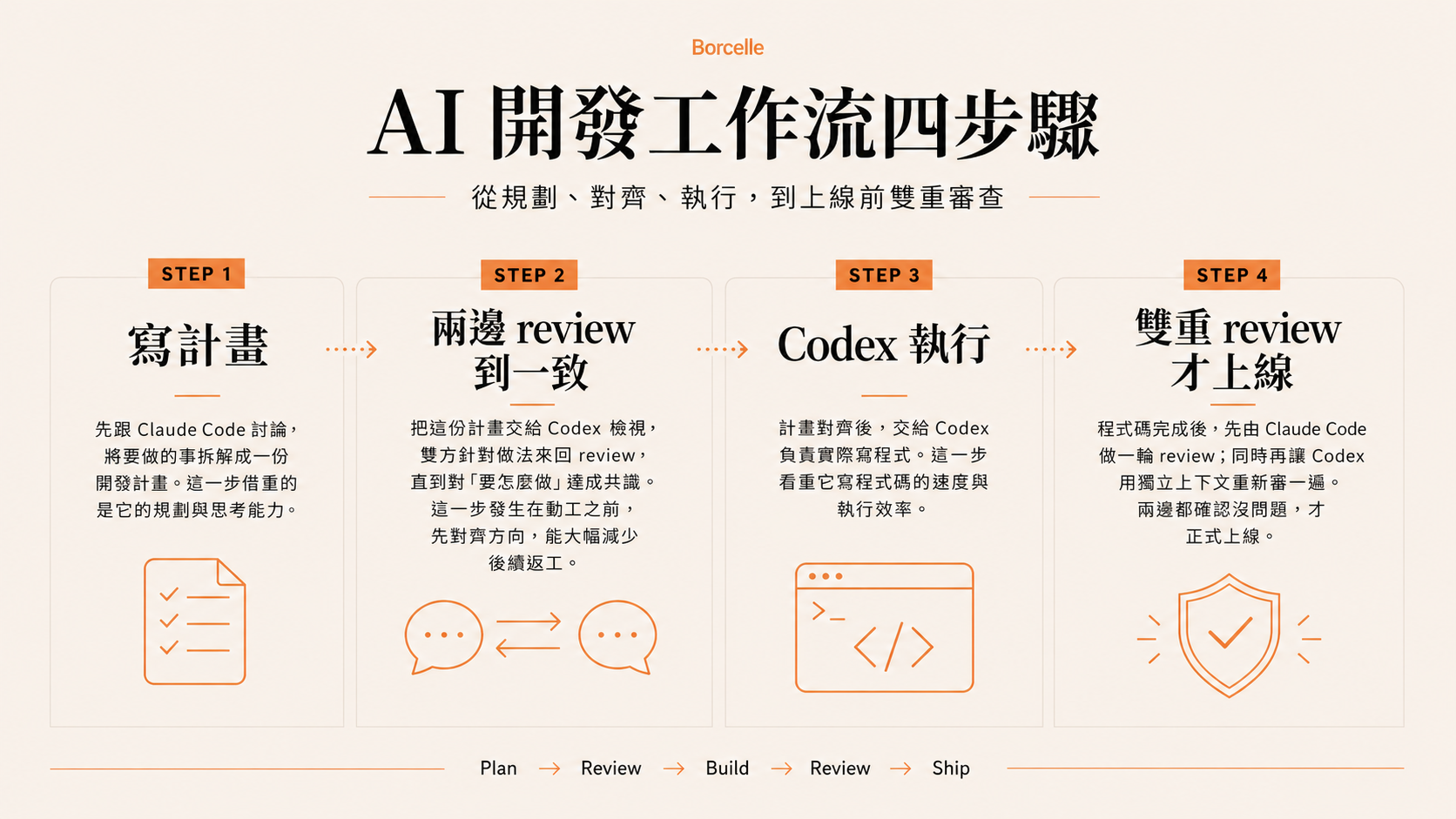
雙重 review 才上線: 程式碼寫完後,先由 Claude Code 做一輪 review;同時,再讓 Codex 另開一個獨立上下文的 agent,用乾淨的視角重新審一遍。兩邊都確認沒問題,才正式上線。
這裡的關鍵設計是第 4 步的「獨立上下文」——同樣是 Codex,但這個負責 review 的 agent 並沒有參與前面的撰寫,所以它不會帶著「這是我寫的」這層預設,能維持審查的客觀性。
為什麼是這個組合?兩邊各有所長
會使用這4步驟是有原因的,相信各位有在使用AI的人都知道,每個AI各有所長,而我們這些user,就必須使用Ai的長處來幫自己達成目的。
| 比較面向 | Claude Code | Codex |
|---|---|---|
| 最擅長的事 | 思考、規劃、寫文案 | 寫程式碼,速度快 |
| 上下文窗口 | 100 萬 token,適合需要讀大量背景的任務 | 相對較小,但執行效率高 |
| 額度 | 一般 | 額度較多,可高頻使用 |
| 多模態理解 | 一般 | 較強,丟截圖、貼圖理解更準確 |
| 內建生圖 | 無 | 內建 GPT Image 工具,做網頁配圖、海報方便 |
| 我的使用習慣 | 已長期使用,累積了我的偏好與記憶,習慣先找它聊 | 主力負責執行階段 |
所以我的分工邏輯很自然:需要讀大量背景、需要思考規劃的任務交給 Claude Code,需要快速把程式碼寫出來的活交給 Codex。 兩者不是二選一,而是各自待在最適合的位置上。
這套工作流怎麼實作?
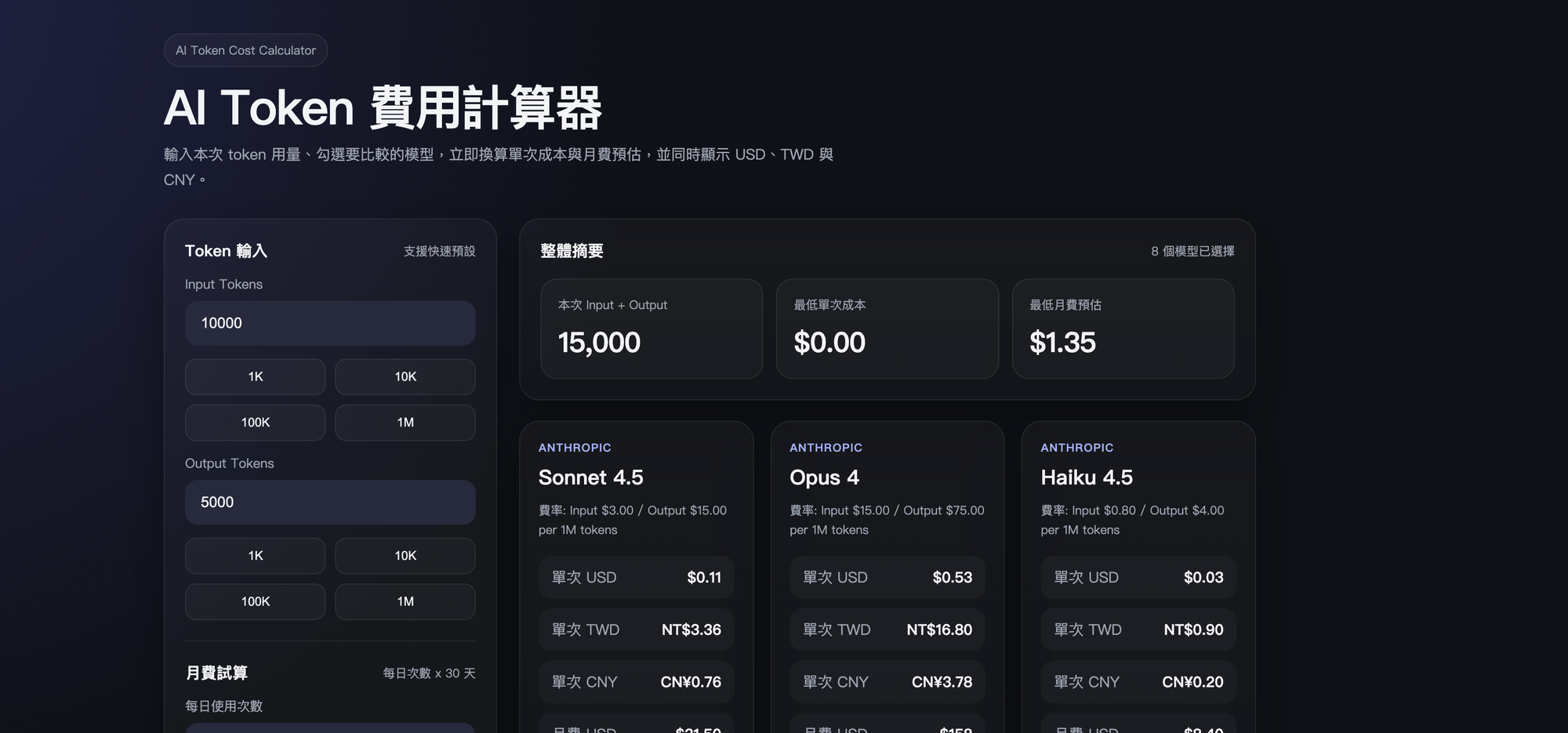
說完原理,來談實際怎麼做。我用一個真實案例帶你走一遍完整流程——AI Token 費用計算器,一個可以比較 Claude、GPT、Gemini 各模型費用的網頁工具。
step 0 — 安裝 skill
在開始之前,先把 skill 放進 Claude Code。(操控 Codex 桌面 App)
裝好之後,Claude Code 往後每次操作 Codex 都會照這份 SOP 走。
Step 1 — 告訴 Claude Code 你要做什麼
我對 Claude Code 說的是:
「我想做一個 AI Token 費用計算器,比較 Claude、GPT、Gemini 各模型的費用,換算 USD / 台幣 / 人民幣,純前端網頁,瀏覽器直接開。你來全程驅動,我不用動手。」
Claude Code 不會直接開始寫代碼。它先問了幾個問題確認方向,然後跟我做討論,這是 Claude Code 的強項——規劃和溝通,有 100 萬 token 的上下文窗口,適合在動手之前把需求想清楚。
Step 2 — Claude Code 寫規劃文件
確認方向後,Claude Code 把完整規劃存成一份 markdown 檔:
規劃包含:
- 功能需求
- 技術規範
- 驗收條件
這份文件之後會直接交給 Codex 執行,也是 review 時的核對標準。
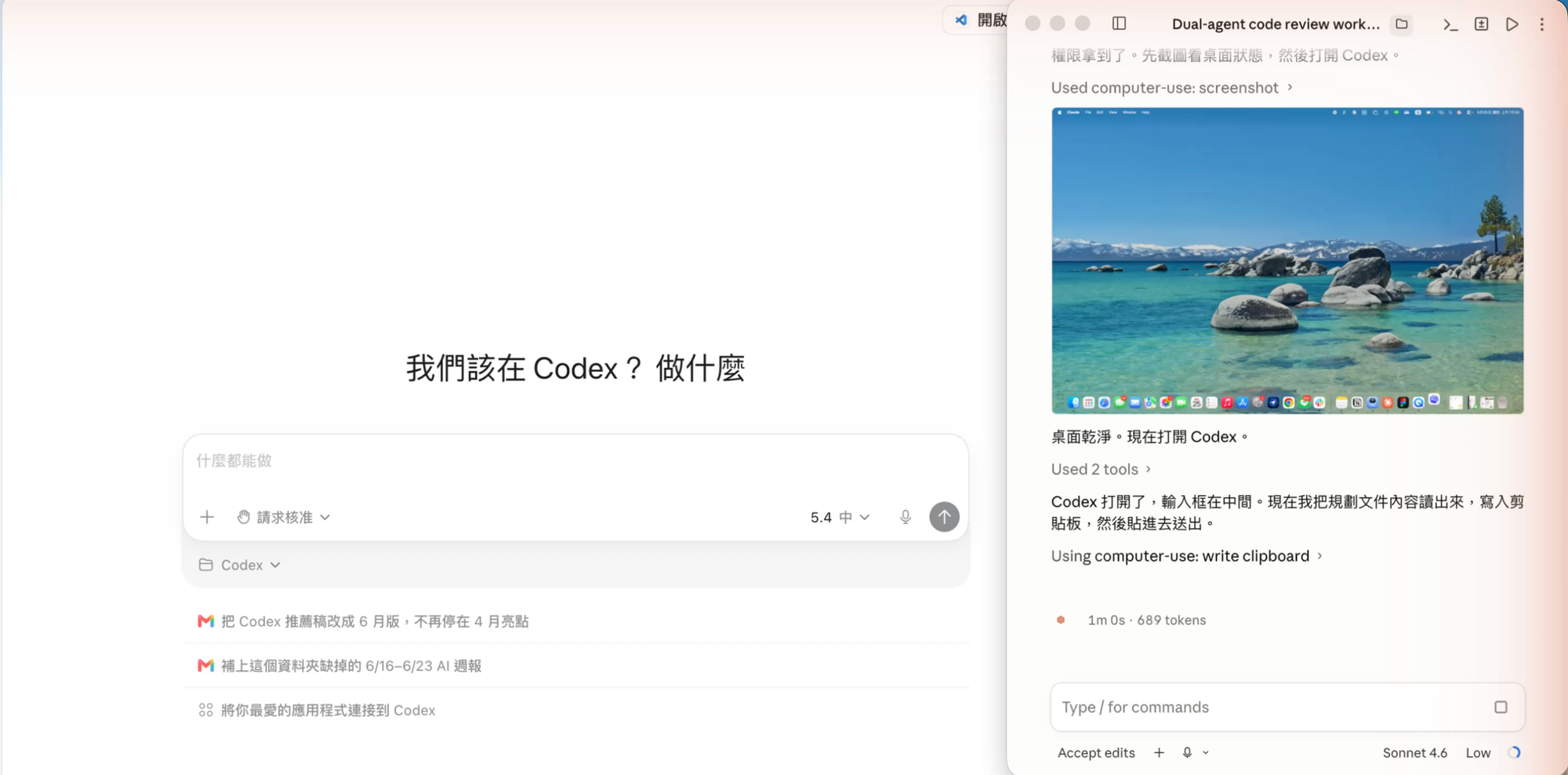
Step 3 — Claude Code 操控 Codex 執行
Claude Code 申請 computer-use 權限後,開始實際操作:
- 打開 Codex 桌面 app
- 截圖確認輸入框位置
- 點擊輸入框,把規劃內容分段打進去並按送出
Step 4 — Claude Code 做 review
Codex 完成後,Claude Code 讀取 ~/Codex/index.html,逐條核對驗收條件,我在途中發現,若有問題Codex 自己不會抓到——因為它剛寫完,很容易覺得自己沒錯。讓另一個 agent 用新的眼睛來看,才找得出來。Claude Code 直接把它修掉。

Step 5 — 瀏覽器驗證
Claude Code 用 open 命令把 index.html 丟進瀏覽器,截圖確認:
8 個模型卡片全部顯示、USD / TWD / CNY 三欄數字正確、最便宜的 GPT-4o mini 標上「最划算」綠色標籤、月費試算有數字。
整個工作流從「我說出需求」到「瀏覽器看到成品」,我一行代碼都沒有動手。
FAQ
Q1:兩個 agent 一起用,會不會很費 token?
體感上正好相反,反而更省。對不懂程式的人來說,過去遇到卡關的 bug,只能自己瞎指揮,常常來回十幾輪都解不掉,每一輪都在燒 token;換成兩個 agent 互相 review,往往一輪就抓出問題。真正費 token 的從來不是「多一個 agent」,而是「找不到問題的反覆空轉」。
Q2:什麼任務適合雙 agent?什麼用一個就夠?
任務越複雜、越怕出錯,雙 agent 的價值越高。牽涉多環節、需反覆驗證、出錯成本高的開發專案,雙重把關才有意義;至於做簡報、跑數據分析這類單純直觀的日常任務,用單一 agent 反而更俐落,動用兩個是殺雞用牛刀。
Q3:我完全不懂程式,也能用這套工作流嗎?
可以,而且這套做法本來就特別適合不懂程式的人。你不需要看懂程式碼,只需要確認兩個 agent 都點頭,就能安心上線。
Q4:一定要用 Claude Code 和 Codex 這個組合嗎?
不一定。這是我個人的使用習慣,重點在「兩個獨立 agent 交叉 review」這個機制,而非特定工具。你可以依自己的偏好替換成順手的組合。
Q5:為什麼負責 review 的要另開「獨立上下文」?
因為要避免「護短」。沒參與撰寫的 agent,才不會帶著「這是我寫的」這層預設,能用乾淨的視角挑出真正的問題。
結語
說到底,雙 agent 交叉 review 的核心,從來不是「用更多 AI」,而是將邏輯釐清,把「執行」和「監督」拆給兩個獨立的對象,讓 AI 不再自己改自己的考卷。Claude Code 負責想清楚、Codex 負責做出來,再彼此交叉檢查——分工各司其職,盲點自然無所遁形。
當然,這套做法只是我的個人習慣,提供給你參考。最好的工作流,永遠是你依自己的偏好、親手調出來的那一套。不必照單全收,挑你用得順的部分,慢慢長出屬於你自己的節奏。



