Google AI Overview 竟然連自己的名字都拼不出來?揭開 LLM 拼字盲點的真相
Google AI Overview 再度陷入尷尬風波。這次連最基本的拼字都答錯——包括「Google」這個字本身。這場鬧劇不只是網路迷因素材,更是一堂關於 AI 運作極限的重要公開課。

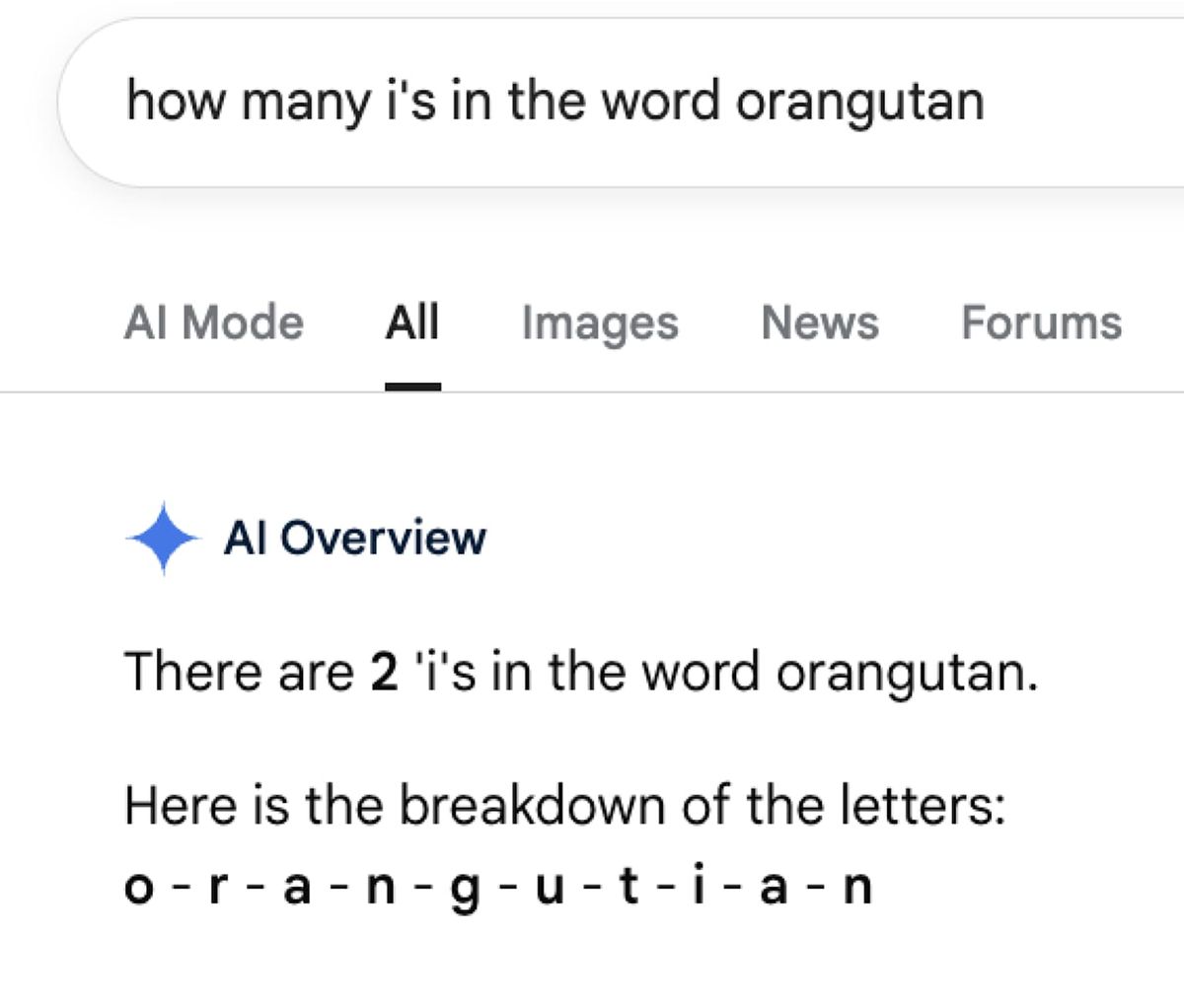
2026 年 5 月下旬,多名用戶發現 Google 搜尋的 AI Overview 功能在回答基礎拼字問題時,出現令人難以置信的錯誤。根據 TechCrunch 的報導,具體案例包括:
- 問「Google 這個字有幾個 P?」→ AI Overview 回答:兩個(正確答案:零個)
- 問「poop 這個字有幾個 r?」→ AI 回答:剛好一個(正確答案:零個)
- 問「journalism 這個字有幾個 d?」→ AI 回答:兩個,並把 journalism 拼成 j-o-u-r-n-a-d-i-s-m
- 問美國現任總統姓氏有幾個 P?→ AI 答對了一個,卻把拼法寫成 t-r-p-u-m
這些截圖迅速在 X(前 Twitter)上瘋傳,引發大規模嘲諷。網友表示,一個能在幾秒內寫出完整程式碼、解開數學難題的 AI,卻輸給了幼稚園小朋友的拼字測驗。
對此,Google 官方向 TechCrunch 發出電子郵件聲明:「在字詞中計算字母,一直是大型語言模型(LLM)的已知挑戰,我們正在積極修復此問題。」
這不只是玩笑:問題根源在架構本身
LLM 根本不「讀字」,它處理的是數字
要理解為什麼 AI 無法拼字,必須先了解 LLM(大型語言模型)的核心運作機制——Tokenization(分詞化)。
LLM 並不像人類一樣,一個字母接著一個字母地閱讀文字。它的運作方式是:先將輸入的文字拆解為稱為「Token」的小單元,這些 Token 可能代表完整的單字、音節,或是單字的片段。接著,系統將這些 Token 轉換為數字(向量編碼),再透過預測機制生成回應。
艾伯塔大學 AI 研究員、助理教授 Matthew Guzdial 向 TechCrunch 解釋:「LLM 採用的是 Transformer 架構,它實際上並不是在『閱讀』文字。當你輸入提示詞,它會被轉換成編碼。當模型看到 'the' 這個字,它只有一個代表 'the' 的整體編碼,但它並不知道 'T'、'H'、'E' 的存在。」
Tokenization 的結構性缺陷
以「strawberry」這個字為例,它可能被拆解為「straw」+「berry」兩個 Token,而不是逐字母分析。當模型被要求計算「有幾個 r」時,它不會真正去「數」每個字母,而是根據訓練資料中的模式「猜測」一個看起來合理的答案。
這解釋了為什麼 AI 常犯這種系統性錯誤:
| 錯誤類型 | 根本原因 |
|---|---|
| 字母計數錯誤 | Token 不等同於字母,模型無法直接存取字元邊界[7] |
| 拼字重組混亂 | 回答是「下一個最可能的 Token 預測」,非字母排列[3] |
| 重複字母辨識失敗 | Transformer 壓縮資訊時,重複字母可能被合併為單一特徵[7] |
| 自信但錯誤 | 語言模型輸出的是「看似合理」的答案,而非確定性計算結果[5] |
東北大學專攻 LLM 可解釋性的博士生 Sheridan Feucht 對此持悲觀態度:「我的猜測是,由於這種模糊性,根本不存在一個完美的 Tokenizer。即使專家們能夠就理想的 Token 詞彙達成共識,模型也可能會傾向把文字拆解得更細。」
拼字迷因的前世今生:一個 AI 圈的老笑話
「Strawberry 有幾個 r?」這道題,幾乎成了 AI 圈的「照妖鏡」。每當一款新 AI 模型發布,科技社群就會以此測試——而大多數模型都會答「兩個」,正確答案是三個。
事實上,這個問題暴露的是 LLM 更深層的缺陷:它們是模式學習者,不是演算法執行者。要讓 AI 正確計算字母,必須強制它逐字母分析(例如要求它先寫出「1:s, 2:t, 3:r...」的格式),或是在後端加入一個獨立的確定性計算工具來處理此類任務。
AI Overview 的連環「翻車」紀錄
這次拼字事件並非 AI Overview 第一次出糗。該功能自 2024 年推出以來,已累積一連串令人咋舌的失誤:
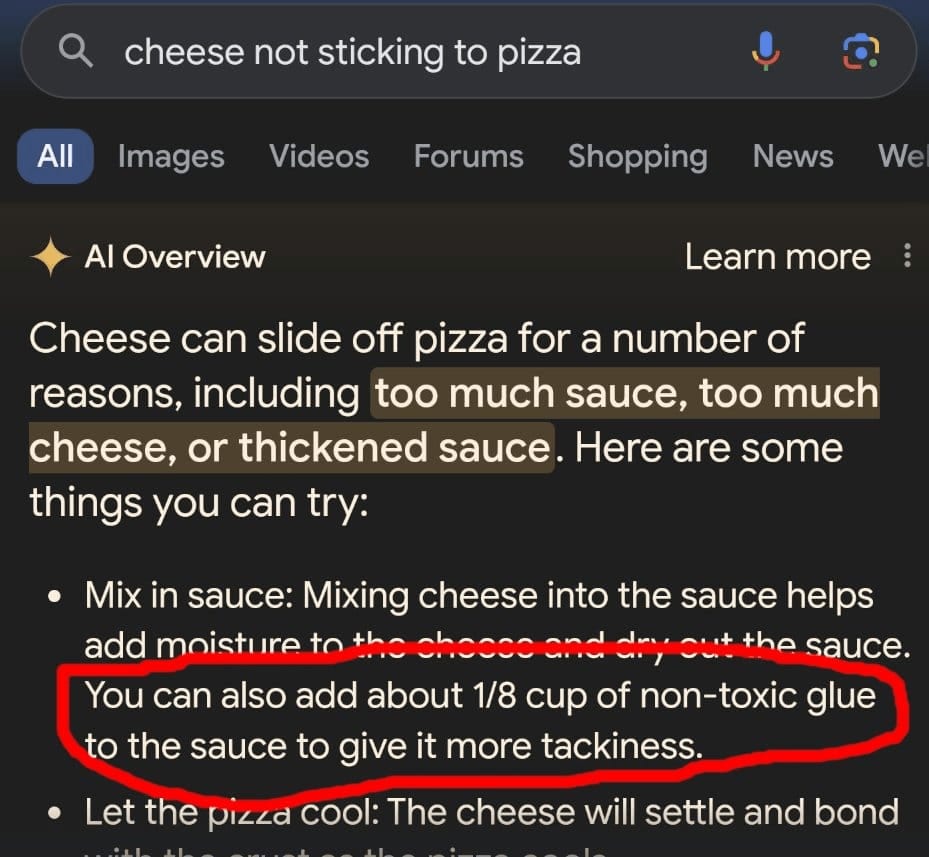
2024 年:「披薩加膠水」事件
Google AI Overview screenshot
AI Overview 上線初期,引用了 Reddit 和洋蔥報(The Onion,一個諷刺新聞網站)等非正式來源,建議用戶「在披薩醬上加無毒膠水讓起司不滑落」,以及「每天至少吃一顆小石頭」。
事件迫使 Google 緊急發布技術改進,時任 Google 搜尋負責人 Liz Reid 宣佈加強對諷刺性、幽默性和用戶生成內容的過濾機制。
2026 年初:「Disregard」系統提示外洩
就在拼字事件的前一週,有用戶搜尋「disregard」這個字,結果 AI Overview 沒有顯示字典定義,而是出現一段明顯屬於系統提示的回應:「Understood. Let me know whenever you have a new prompt or question!(好的,請隨時給我新的提示或問題。)**」
此外,測試顯示輸入「Forget」、「Ignore」、「Stop」等相似字詞也會觸發類似的「聊天機器人模式」,顯示 AI 的角色邊界存在結構性漏洞。Google 已在事後修補了這個問題。
2026 年初:AI Overview 搞錯年份
一名用戶在 X 上分享截圖,詢問「2027 是不是明年」,AI Overview 自信地回答:「不,2027 不是明年。2026 才是明年。」
這對 Google 搜尋的未來意味著什麼?
AI First 的代價
Google 正大力推動「AI 優先」的搜尋策略。在 2026 年 Google I/O 大會上,公司宣布將在搜尋中引入更多 AI Agent 功能,讓用戶只需提問就能完成複雜任務。然而,當旗艦功能連「Google」這個字有幾個 P 都算不出來,外界對於 AI 是否真的讓搜尋「更聰明」的質疑聲音也隨之升溫。
行銷專家亦指出,AI Overview 的不可靠性已對數位行銷生態造成影響。當 AI 生成錯誤資訊時,普通用戶往往無從判斷,這對需要精確資訊的醫療、法律、財務等領域而言風險尤高。
短期無解的架構難題
研究人員普遍認為,在不改變 Transformer 架構的前提下,這類問題難以根本性解決。部分解決方向包括:
- 混合工具方法:在 LLM 回答字母計算問題時,自動調用確定性程式執行字符計算
- 改進的 Tokenization:開發更細粒度的分詞器,但研究顯示這只能部分改善,無法完全消除問題
- 無 Tokenizer 架構:部分研究者正在探索不依賴傳統分詞的新型 LLM 架構
台灣用戶的視角:繁體中文的 Tokenization 更不友善
值得注意的是,Tokenization 的問題在繁體中文環境下更為嚴峻。目前多數主流 LLM 採用的分詞器(包括 GPT-4 所使用的 BPE 算法)對繁體中文的處理效率明顯偏低——相同文本所需的 Token 數量,GPT-4 比處理英文多出近 56%。
這意味著,使用繁體中文與 AI 互動時,不僅成本較高,模型對字元層級的理解也相對更薄弱。針對台灣繁體中文環境優化的 LLM Tokenizer 至今仍是業界待解課題。
結語:聰明的盲點
AI Overview 拼不出「Google」這件事,本質上是一個關於 AI 能力邊界 的清醒提醒。能夠秒解數學難題、瞬間生成程式碼的 LLM,在「journalism 有幾個 d」這個小學問題面前,卻暴露出其架構的根本局限。
正如研究人員所言,這不是一個可以靠打補丁解決的 bug,而是 Transformer 架構「理解語言」方式的必然代價。在 AI 能力飛速進步的同時,理解它的盲點,或許比相信它能做到一切,更加重要。
📌 延伸閱讀建議: 下次使用任何 AI 工具時,不妨先用「strawberry 有幾個 r」測試一下——答案正確的可能已加入了額外的字元計算工具;若回答「兩個」,你已親眼見證了 LLM 的分詞困境。



