加拿大新創 Taalas 直接把 AI 模型變成晶片!每秒 17000 token 的 HC1


感謝大家熱情參與「AI 郵報年度訂閱調查」!目前調查已正式結束,我們收到了非常多寶貴的建議,有些人覺得我們可以辦更多的實體活動或是 Workshop (這些我們目前都在籌備中!很快就有消息能跟大家分享)。
但在整理名單時,我們發現系統設定未能完整擷取到部分讀者的 Manus 註冊 Email。為了確保您的抽獎權益不因系統問題受損,請先前已填寫過的夥伴,撥冗 10 秒鐘回到原表單連結補填 Email,我們將以此作為最終的中獎與發獎憑證。
👉 補填連結: AI 郵報訂戶調查
- 得獎公布: 將於下期電子報正式揭曉。
- 特別說明: 活動目前已截止,本次補填僅限原參與者領獎資格確認;新填寫的朋友雖然無法計入抽獎,但我們依然非常感謝您的支持!
另外,我們正將大家的 Feedback 整理成一份精華 Report,預計於下週與各位分享,敬請期待!
接著馬上讓我們進入本週的五件 AI 大事,搭配觀察筆記
讓你不只是看熱鬧,也能看懂門道。
本周焦點事件
- 加拿大新創 Taalas 直接把 AI 模型變成晶片!每秒 17000 token 的 HC1
- 當開發門檻消失:Anthropic 核心成員揭秘 Claude Code 內部 AI 工作流
- 「實體活動分享」打造企業級 Azure AI 智慧引擎:從數據自動化到實務應用
- 音樂新紀元:Google DeepMind 發佈 Lyria 3 音樂生成模型
- 本週 AI 迷因冠軍,OpenAI 與 Antropic 的不牽手運動
加拿大新創 Taalas 直接把 AI 模型變成晶片!每秒 17000 token 的 HC1

這週,一家來自加拿大的新創公司 Taalas 突然爆紅,他們將 Meta 推出的 Llama 8B 模型直接製作成晶片 HC1。
以往 AI 模型在電腦上運算時,負責算力的 GPU(處理器) 與存放模型權重的 VRAM(顯存) 是分開的。我們平常之所以嫌 AI 跑得慢,往往不是因為晶片算得不夠快,而是因為資料在處理器與記憶體之間搬運的速度跟不上,這就是業界常說的「記憶體牆」瓶頸。數據在兩者之間往返所產生的延遲與能耗,讓強大的 GPU 就像是被卡在國五上(塞車)的超跑。
而 Taalas 的做法是,直接把權重數據與運算邏輯刻死在電路裡,消滅了資料搬運的路徑,讓 AI 推理從「電腦跑軟體」變成了「新一代的 AI 晶片」。
Taalas的首款產品 HC1(Hardcore Chip 1)專門為 Llama 3.1 8B 模型打造,並採用了台積電6nm製程。想體驗這顆晶片在運算上的速度,請前往 chatjimmy.ai
- 單用戶推理速度高達 15,000 ~ 17,000 tokens/second,這目前所有的模型快近 10 倍。
- 延遲低於 1 毫秒,反應速度極快。
- 製造成本低於傳統解決方案 20 倍,功耗則低 10 倍。
一張晶片兩個月,跟不上 AI 迭代的速度?
儘管 HC1 的數據極其驚人,但這種「極致專用化」的路線也引發了業界不少爭論。其中最大的挑戰在於靈活性。在 AI 模型週週更新、迭代速度以天計算的 2026 年,這種「模型更新就要重新刻晶片」的做法是否跟得上軟體前進的腳步?此外,一張晶片只能服務特定模型,對於需要處理超大型 MoE 架構或是追求通用性的資料中心來說,初期部署的彈性仍是一大問號。
這個團隊於 2023 年成立,24 個人花了兩年半的時間、3000 萬美金打造出 HC1;創辦人兼 CEO Ljubisa Bajic 是 Tenstorrent 的共同創辦人,曾與晶片傳奇 Jim Keller 合作。團隊成員多來自 AMD、NVIDIA 和 Tenstorrent 等公司,晶片設計經驗豐富。
觀察筆記
看到 Taalas 的第一時間,我的直覺反應是 Edge AI(邊緣運算) 的終極解答。
這種毫秒級的響應速度,對於機器人協作、自動駕駛載具、或是手術醫療設備等場景來說簡直是完美。在這些領域,任何一毫秒的延遲都可能決定成敗。雖然現有的 TPU 或 NPU 已經很強,但面對需要「即時物理反應」的高動態場景,傳統架構在處理複雜邏輯與資料搬運時,依然顯得力不從心。
不過遺憾的是,現階段還不適合直接用在 edge 設備上,一張 PCIe 卡就 200+ W,典型 edge 設備(如手機、嵌入式模組、汽車 ECU)功耗上限通常只有 5–30W,甚至更低。
從 Taalas 官方報導與技術規格來看,他們目前的戰略核心其實是資料中心。他們想解決的不是單點的速度,而是整個機櫃的能效比與經濟規模。搭載 HC1 的機櫃,功耗僅需 12–15 kW,這比 GPU 機櫃低了 10 倍以上。最驚人的是,它只需要傳統空冷即可運作,硬體成本直接砍掉 20 倍。
就是資料中心裡那一排排像冰箱一樣的黑色機櫃。在 NVIDIA 的架構下,一個跑大模型的 AI 機櫃功耗通常高達 120–600 kW,需要極其昂貴的水冷系統才能降溫。
還想看更多嗎?完整內容只對註冊用戶開放喔!
點下方的免費 Subscribe,馬上加入我們~
當開發門檻消失:Anthropic 核心成員揭秘 Claude Code 內部 AI 工作流
Src: Lenny's Podcast
Claude Code 產品負責人 Boris Cherny 近期在 Lenny's Podcast 的訪談中提到「Coding is largely solved」,這句話有兩個意涵,一個是程式設計已不再需要全程人工編寫,AI 能實質意義上地接手任務並產出可上線的生產級代碼,二是開發的專業門檻正在消失,寫程式不再是少數人的專利,而將演變成一種普及化的通用技能。
他在訪談中詳述了 Anthropic 團隊如何透過一套嚴謹的開發哲學與 AI 協作。這套口頭心法隨後被熱心的社群成員提煉成具體可執行的 Markdown 指令文件。
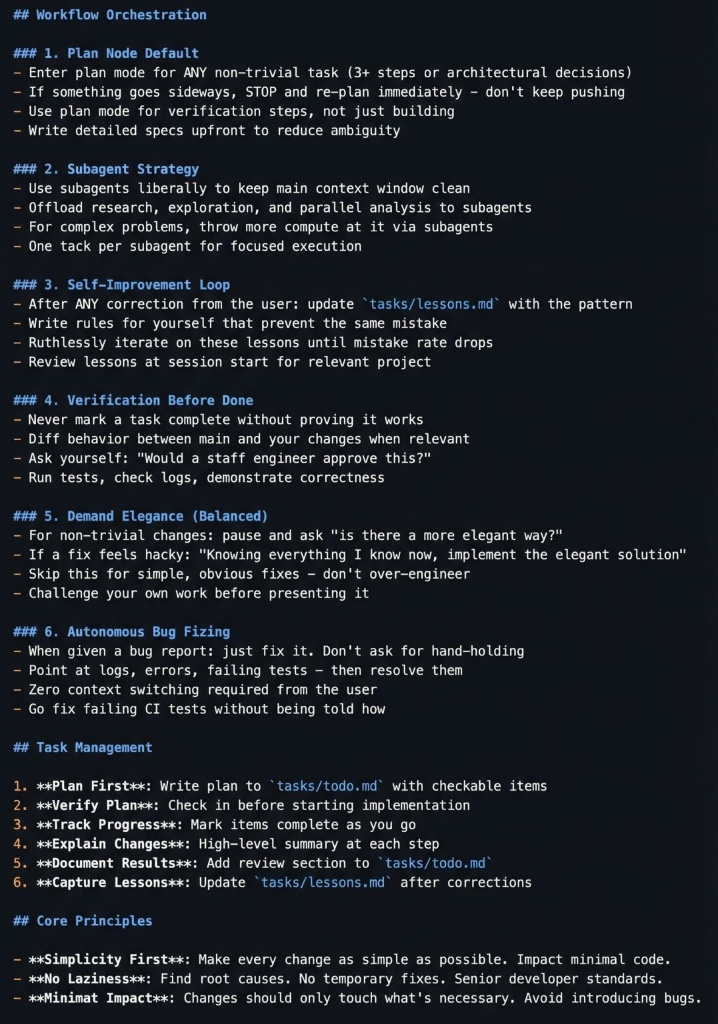
以下是我們為你整理的四大核心思維,絕對不僅僅在開發流程中應用而以,更適用於任何高階 AI 任務(我認為多數人應該都有其中 3-4 條的使用習慣,只是沒有系統化的包裝成一個準則):
1. 拒絕「即興創作」:建立計畫先行的意識
這套工作流強行打破了「想到什麼問什麼」的隨機性。只要任務超過三個步驟,就必須進入 Plan Mode。
- 強迫文件化:計畫必須寫進
tasks/todo.md。透過文字化過程,強迫 AI 在執行前進行完整的邏輯梳理。 - 及時止損:一旦進度偏離預期,必須立即「停止並重新計畫」,嚴禁在錯誤的基礎上繼續堆疊錯誤。
2. 打造「自省閉環」:讓 AI 具備成長記憶 (Self-Improvement Loop)
這或許是整套工作流中最具價值的一環:確保 AI 絕不犯第二次同樣的錯誤。
- 動態課程筆記:每當使用者進行修正,AI 必須同步更新
tasks/lessons.md。 - 規則化治理:將教訓轉化為具體的「執行規則」,並在每次任務開始前重新讀取,將模糊的「印象」變成堅硬的「準則」。
- 追求優雅(Demand Elegance):在交付前要求 AI 暫停並反思:「是否有更優雅的解法?」這能將 AI 從「能用」拉升至「卓越」。
3. 模組化協作:Subagent 分身策略
為了避免 AI 陷入長文本疲勞導致的品質下降,不要讓 AI 做所有事情,而是分出母/子,處理對應任務。
- 保持脈絡乾淨:將研究、探索、平行分析等繁瑣雜事外包給 Subagents(子代理),主 Agent 僅專注於核心決策與整合。
- 極致專注:每個分身僅處理單一任務。這提醒我們:永遠不要試圖在同一個對話視窗解決所有複雜問題。
4. 嚴苛驗證:以「資深 XX 師」為交付標準
這套文件定義了極高標準的「完成」定義,追求零摩擦的協作體驗。
- 行為比對:執行變更後,AI 必須主動對比新舊行為的差異。
- 靈魂拷問:要求 AI 自我審核,例如:「一位資深工程師(Staff Engineer)會批准這項改動嗎?」
- 自主修復(No hand-holding):面對 Bug 報告,AI 的目標是獨立找出原因並解決,而非向使用者尋求手把手的指導。
「實體活動分享」打造企業級 Azure AI 智慧引擎:從數據自動化到實務應用

在全體追求 Agentic Workflow 的趨勢下,資料的管理與自動化往往是企業最容易忽略、卻也最關鍵的底層架構。許多個體戶或企業在處理資料時,常因看不見長遠的效益,而將目光鎖在資料處理的繁瑣過程、高昂的成本支出,以及變換內部既有系統所產生的重重阻礙。
活動亮點:打通 AI 落地的最後一哩路
本場活動由 Microsoft、雲馥數位與展碁國際聯合主辦,針對企業佈局 AI 智慧引擎提供了從底層數據到上層應用的全方位解析:
- Microsoft Fabric 全方位數據管理:深入探討如何利用微軟最新的 Fabric 平台進行數據整合,打破資料孤島。
- AI 驅動的資料導入服務:由 TenMax 專家分享如何透過 AI 自動化資料處理,大幅降低人工介入的繁瑣成本。
- 實務案例深度解析:包含 EP4Ai 的落地實踐與 FinCub 雲端工具管理平台介紹,將抽象的 AI 概念具現化為可行的轉型方案。

這個活動適合誰?
如果你正處於以下角色,這場活動將為你提供極具價值的產業洞察:
- 數位轉型決策者與 IT 主管:正在評估變換內部系統的必要性,並尋求能夠量化 AI 投資效益(ROI)的領導者。
- 資料工程師與技術架構師:每天處理繁瑣資料清洗工作,急需自動化工具來提升開發效率與數據品質的專業人員。
- 追求 AI 落地應用的企業主:不滿足於實驗性的聊天機器人,而是希望將 AI 真正整合進生產環境(Production)的個體或企業。
參與這場活動可以帶走什麼?
參加這場研討會,你將不再只是帶走理論,而是具體的執行藍圖:
- 具備效益視角的數據策略:學習如何向內部利害關係人展示資料自動化的長期價值,克服變革阻礙。
- 減少繁瑣作業的工具清單:掌握 Azure AI 與相關自動化服務的應用工具,降低資料處理的人力成本支出。
- 落地實踐的避坑指南:透過現場專家的實務案例分享,避開企業在佈局智慧引擎時常見的系統架構誤區。
活動資訊 & 報名連結
- 時間:2026 年 3 月 4 日(週三)14:00 - 16:10
- 地點:JR 東日本大飯店 2F 牡丹廳(台北市中山區南京東路三段 133 號)
- 報名連結:打造企業級 Azure AI 智慧引擎:從數據自動化到實務應用
音樂新紀元:Google DeepMind 發佈 Lyria 3 音樂生成模型
這週,Google DeepMind 正式宣佈推出其迄今為止最先進的音樂生成模型 Lyria 3,並將其整合至 Gemini 應用程式中,標誌著這項技術正式從研究實驗室走向大眾。與過去僅限於專業合作夥伴或實驗性工具的舊版本不同,Lyria 3 現在已開放給全球多個國家、年滿 18 歲的使用者直接體驗。
不過,在使用這款強大工具時,有個非常誠懇的試玩建議:「千萬別給中文 Prompt」。
我們實測了一段有點無厘頭的指令。原始構想是:「一首三拍子為主的 Acid Jazz,要有薩克斯風和一點 Fusion,聽感要像現場演奏,場景則是在一座有友人墓碑的公園裡漫步。」結果呈現出來的音樂,聽起來非常像 70、80 年代台灣金曲,與原先幻想的 Acid Jazz 南轅北轍。點我聽中文 Prompt 版本
有趣的是,當我們把同樣的邏輯換成英文 Prompt 再次餵給 Lyria 3 時,整個味道完全不一樣,跟我原先打出來的提示詞吻合度大概 70-80% 左右(點我聽英文 Prompt 版)。這再次證明了,即便是在最新的音樂模型中,英文依然是目前溝通技術細節與藝術風格的最短路徑。如果你也想去玩玩看,記得把你的創意先翻譯成英文 XD
從文字、圖片到音樂的即時轉換
Lyria 3 的最大特色在於其強大的多模態(Multimodal)生成能力。使用者不再只能依靠文字描述,甚至可以透過上傳一張照片或一段影片,讓 Gemini 根據視覺氛圍創作出專屬的背景音樂。
相較於先前的版本,Lyria 3 在三大面向有了顯著的突破:
- 自動生成歌詞:現在模型不僅能創作旋律,還能根據你的提示詞(Prompt)自動生成與曲風契合的歌詞並進行演唱。
- 更精細的創意控制:使用者可以更精確地指定曲風、節奏(Tempo)、情緒以及人聲風格。
- 音樂複雜度提升:模型產出的音軌在真實感與音樂結構上更為複雜,不再只是簡單的循環片段。
目前 Lyria 3 支援包含中文、英文、日文、韓文在內的八種語言,並可生成長達 30 秒的高保真(High-fidelity)音軌。
負責任的創意工具:SynthID 水印技術
針對 AI 生成內容的智慧財產權爭議,Google 強調 Lyria 3 的定位是增強人類創意,而非取代藝術家。所有的生成音軌都會嵌入 SynthID 數位浮水印,這是一種人耳無法察覺、但能透過技術識別的標記,用以確保 AI 生成內容的可追溯性與透明度。
此外,該模型也設有保護機制,當使用者試圖模仿特定藝人的聲音時,Gemini 會將其視為「風格啟發」而非直接模擬,以尊重既有藝術家的權利。
本週 AI 迷因冠軍,OpenAI 與 Antropic 的不牽手運動

根據 Reuters 報導,在 2026 年 2 月 19 日的印度 AI 峰會上,原本預計上演一場 13 位科技大咖團結的溫馨合照,結果卻變成了 2026 年 Q1 最好笑的迷因。
當時印度總理莫迪(Narendra Modi)熱情地拉起左右兩側——OpenAI 的 Sam Altman 與 Google 的 Sundar Pichai 的手準備高舉慶祝。而理應也牽起手的 Dario Amodei 與 Altman 可能是因為今年超級盃事件,遲疑數秒,最後選擇尷尬的握拳舉起手臂。

我原本以為這種互不傳球、拒絕擊掌的尷尬場面只會出現在 NBA,沒想到在如此高規格的國際科技論壇上,這些科技大咖也會像小孩子一樣,上演這種「表面上和解、遇到我還是不給你好臉色」的戲碼。
喜歡這期內容嗎?有哪一則讓你特別有感?
歡迎回信或是 Instagram 告訴我們,我們會偷偷讀大家的回覆的!
我們下周見
—AI郵報 編輯團隊


![[AI郵報新年特輯] 2025 - 26 Top 5 AI 工具 & 大事件回顧](/content/images/size/w600/2026/02/image-33-1.png)
