【科技解密】OpenAI最新突破:拆解AI“黑箱”!用「稀疏電路」看懂人工智慧如何思考
OpenAI用稀疏電路打開AI黑箱,發現可理解的內部計算迴路,有望訓練出透明且強大的AI系統。

為什麼理解AI這麼難?黑箱問題的困境
時至今日,我們生活中使用的最先進的AI系統,無論是 ChatGPT、Claude 還是 Gemini,都依賴於一種核心結構:神經網路(Neural Network)。
但奇怪的是,這些功能強大的模型,並不是由工程師一行行寫下明確的、循序漸進的指令。相反地,它們是通過調整數十億個內部連接(我們稱之為「權重」),不斷學習直到精通某項任務。
這項學習的成果,卻是一個極度複雜且密集的連接網路,人類難以直接理解,因此被稱為「黑箱問題(black-box problem)」。我們設計了訓練規則,但卻無法預測或理解模型內部具體產生了哪些行為。我們可以觀察到AI的輸入和輸出,但卻幾乎無法理解中間的運算邏輯。
換句話說:我們知道AI是如何被訓練出來的,但卻不知道它「為什麼這樣想」。
在AI系統越來越強大,並開始在科學、教育和醫療決策中產生實際影響的今天,理解它們的工作原理至關重要。這就是「可解釋性(Interpretability)」研究成為 AI 安全與可靠性關鍵的原因。
什麼是「可解釋性」?兩種理解AI的路徑
可解釋性是指幫助我們理解「為什麼模型會產生某個特定輸出」的方法。這項研究支持了多項關鍵目標,例如提供更好的監督、對不安全或有策略性誤導的行為提供早期預警。它也補充了其他安全措施,像是可擴展的監督、對抗性訓練和紅隊測試。
目前,研究領域主要有兩條路徑來實現可解釋性:
- 思維鏈解釋(Chain-of-Thought Interpretability):這種方法是激勵模型在得出最終答案的過程中,「解釋自己的工作」。它利用這些解釋來監測模型的行為,對於當前的推理模型來說,這些解釋對於識別像是欺騙行為等問題行為很有幫助。然而,這種方法過於依賴模型的「自我描述」,是一個相對脆弱(brittle)的策略,可能隨時間推移而失效。
- 機械可解釋性(Mechanistic Interpretability):這是本次OpenAI研究的重點。它尋求完全反向工程(reverse engineer)模型的計算過程,試圖從最細微的層次(granular level)解釋模型的行為。雖然在過去它較少被立即應用,但原則上,它可以對模型的行為提供更完整、更有信心的解釋,因為它只需要做更少的假設。
OpenAI 的最新研究,正是屬於第二類,它試圖真正打開AI的「大腦」,從「電路層面」看清其內部結構。
顛覆性假設:將「密集網路」變成「稀疏電路」
以往的機械可解釋性研究,都是從已經訓練好的、密集(dense)且糾結(tangled)的網路開始。在這些密集的網路中,每個單獨的神經元都連接到數千個其他神經元,並且大多數神經元似乎同時執行許多不同的功能,使得理解模型幾乎成為不可能的任務。
OpenAI 團隊提出了一個具有顛覆性的研究假設:
「如果我們從一開始就訓練『解開』的神經網路,讓它擁有更多的神經元,但每個神經元只與幾十個連接相連,網路會不會變得更簡單,更容易理解?」
這就是「學習稀疏模型(learning sparse models)」的新方法。
研究人員以與現有語言模型(如 GPT-2)非常相似的架構進行訓練,但做了一個關鍵的修改:
- 強制絕大多數模型的權重為零。
- 這限制了模型只能使用極少數神經元之間的可能連接。
- 結果是:每個神經元只連接到下一層中的少數幾個神經元。
這種簡單的改變,被認為能大大解開(substantially disentangles)模型內部的計算過程。
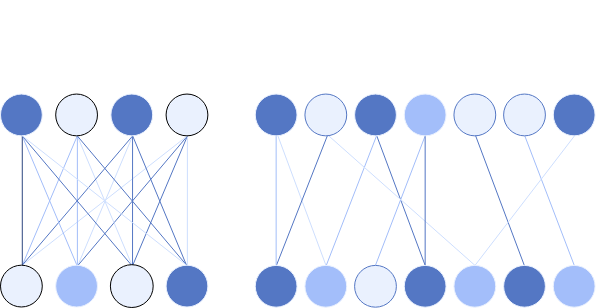
你可以把密集的網路想像成一團無法解開的電線球。而稀疏模型,就像是將這團電線球拆開,只保留那些最關鍵、最必要的幾根導線,這樣我們就能清楚地看到每條線具體「在做什麼」。
稀疏模型的成果:發現可拆解的「思維迴路」
這項工作的核心目標是證明:我們可以訓練模型使其更容易被解釋。對於簡單的行為,研究人員發現,使用他們的方法訓練的稀疏模型包含小巧、分離(disentangled)的電路,這些電路既可理解,又足以執行該行為。
為了衡量稀疏模型的計算被分離的程度,研究人員設計了一系列簡單的算法任務,並檢查是否可以隔離模型中負責每種行為的特定部分——這被稱為「電路(circuits)」。
範例一:Python 引號匹配任務
考慮一個簡單的編程任務:模型在訓練 Python 代碼時,必須正確地補全字串的引號。
- 如果字串以單引號開頭(例如:'hello'),它必須以單引號結尾。
- 如果字串以雙引號開頭(例如:"hello"),它必須以雙引號結尾。
這要求模型必須「記住」開頭的引號類型,並在結尾處重現它。
驚人的發現:研究人員在最可解釋的模型中,發現了一個完全分離的電路,它精確地執行了這個算法。
這個電路運作方式如下:
- 編碼:在第一層,它將單引號和雙引號編碼到不同的內部通道(residual channels)中。
- 轉換:接著,使用一個 MLP(前饋網路)層,將這個信息轉換成兩個通道——一個通道檢測是否有任何引號,另一個通道區分單引號或雙引號。
- 記憶/複製:在第10層,使用一個注意力機制(attention operation)來忽略中間的文本( intervening tokens),找到先前的引號,並將其類型複製到最後的記號上。
- 輸出:最終,模型根據複製的類型預測匹配的閉合引號。
研究人員強調,圖中顯示的這些確切連接足以執行該任務——即使移除模型的其他部分,這個小電路仍然能工作。同時,它們也是必要的——刪除這些連接中的少數幾個邊緣,會導致模型失敗。
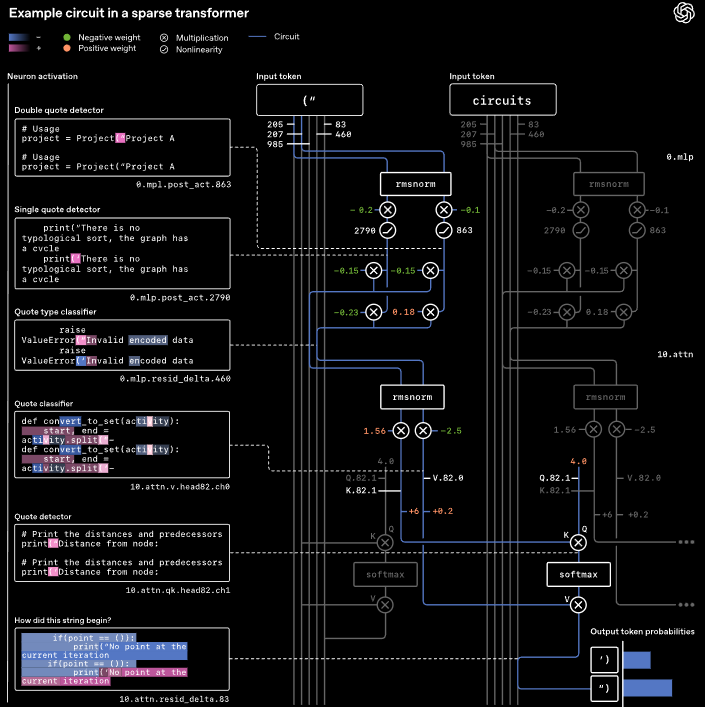
這證明了模型的「思維迴路」可以像電子電路一樣被拆解、驗證,並理解其運作機制。
範例二:更複雜的變數綁定
對於更複雜的行為,例如程式碼中的「變數綁定(Variable Binding)」,雖然電路更難以完全解釋,但研究人員仍能取得相對簡單的部分解釋,這些解釋對於預測模型行為很有幫助。
例如,當模型在程式碼中看到 current = set() 時,當它在後續看到 current.add() 時,它需要「記得」 current 的類型是一個 set 集合。
研究發現,模型內部存在兩個關鍵的注意力操作:
- 第一個操作在定義變數時,將變數名稱複製到
set()記號上。 - 第二個操作在後續使用變數時,將類型從
set()記號複製過來。

這兩個操作形成了一個「變數綁定迴路」,揭示了模型是如何一步步「理解變數關係」的。
能力與透明度:我們可以同時擁有嗎?
當然,我們會擔心這種「稀疏化」會不會讓AI變笨?這聽起來就像是給AI「削骨」。
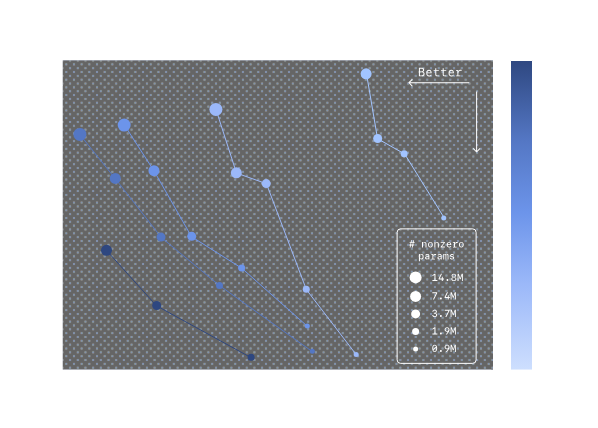
研究者繪製了模型性能(Capability)與可解釋性(Interpretability)之間的關係曲線。他們發現:
- 對於固定大小的稀疏模型,增加稀疏度(設置更多權重為零),會降低能力,但增加可解釋性。
- 然而,擴大模型規模時,這條界線會向外移動。
這項發現暗示了一個非常重要的未來方向:我們可以構建出規模更大、同時既強大又透明(capable and interpretable)的AI系統。
結語與展望:通往可讀AI的漫長道路
這項工作是邁向「使模型計算更容易理解」這一宏大目標的早期一步。研究團隊坦言,當前的稀疏模型遠小於像是 GPT-5 或 o3-mini 等前沿模型,且其大部分計算仍然未被完全解釋。
但這仍然是個很有前景的早期結果。未來,研究人員希望將這些技術擴展到更大的模型。通過列舉潛藏在這些稀疏模型中、更複雜推理背後的「電路主題(circuit motifs)」,我們可以發展出一種理解方式,幫助我們更好地研究前沿模型。
為了克服訓練稀疏模型的效率問題,他們提出了兩條發展路徑:
- 從現有的密集模型中提取稀疏電路:這相當於從一棟運作中的大樓裡,找到執行特定功能的可獨立運作的電路板。
- 開發更高效的「可解釋性訓練」技術:讓未來的大模型在訓練時,就能自然形成結構化的電路,而不是事後再去剖析。
最終目標是逐漸擴大我們能夠可靠解釋的模型部分,並建立工具來使未來的系統更容易被分析、除錯和評估。這項研究為我們帶來了希望,或許有一天,我們真的能夠「閱讀」AI的大腦,清楚地知道它做出每一個判斷和選擇的原因。
理解AI的「稀疏電路」概念,就像是拆解一部複雜的機器:
想像AI是一個巨大且充滿線路的工廠,原先的密集神經網路就像是工廠裡所有的電線都纏繞在一起,你無法知道哪根線控制哪台機器。 而 「稀疏電路」技術,就像是工程師將這些電線一根根解開,只保留那些執行特定功能(如「報價單確認」或「計算變數」)所必需的線路。 透過這種方式,當機器做出特定反應時(例如:引用了單引號),我們可以直接追蹤到是哪幾根線路在發揮作用,從而真正理解它的工作原理,讓AI工廠變得透明化且可管理。
Source:
OpenAI: Understanding neural networks through sparse circuits



