【深度專題】AI 幫我們從植物中找藥!Nanyang Biologics:用 AI+自然加速新藥開發的生技新創


🧬|為什麼我們需要新的新藥開發方式?
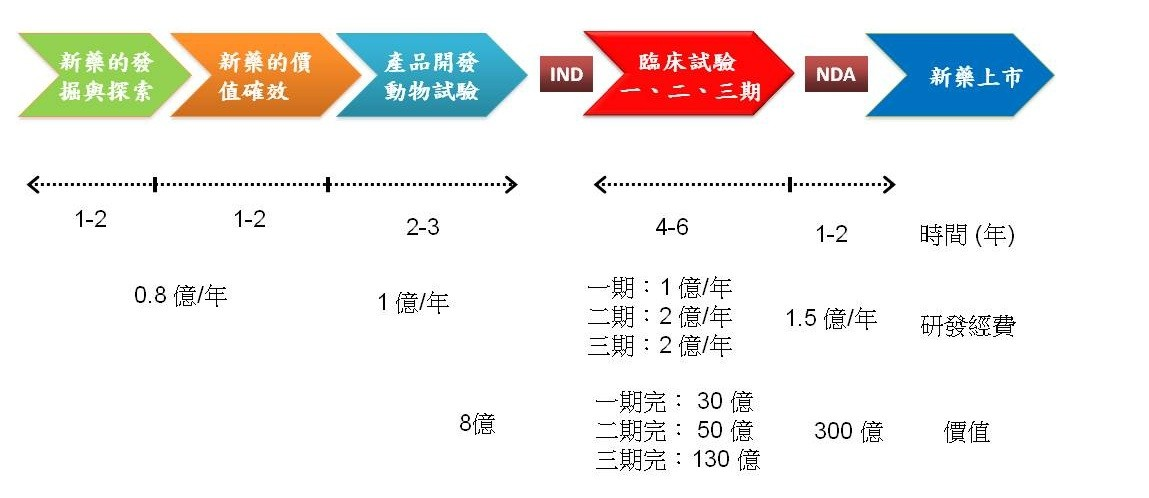
每一顆你吞下的藥丸,背後可能是 10 年以上的研發歷程,還有高達上 10 億美元 的投入。而更令人驚訝的是,在這場馬拉松裡,超過八成的候選藥物,會在臨床階段前就失敗。
藥物開發為什麼這麼難?
因為從一開始,我們就得在數以「十億計」的分子中,找出那幾顆可能有效的「潛力股」。這就像在熱帶雨林裡尋寶,比如你可能聽過的百憂解(Prozac),從最早的分子篩選到真正上市花了 15 年;而針對乳癌的標靶藥物赫賽汀(Herceptin)也花了 超過 12 年才完成驗證。即使是疫情下快速推出的新冠藥 Paxlovid,也建立在過去 超過 20 年的病毒研究基礎上。這正是為什麼新藥研發成本這麼高、風險這麼大的原因之一。
但如果有一種方法,能讓我們先讓 AI 把「垃圾」篩掉,專注研究最有希望的那一批分子呢?這正是來自新加坡的新創公司 Nanyang Biologics 正在做的事。他們結合自然與人工智慧,讓藥物研發變得更快、更準,也更有機會拯救真正需要幫助的病人。
他們怎麼做?AI+植物科學雙引擎
Nanyang Biologics 結合 大自然的藥材庫 和 人工智慧演算法,用一種全新的方式推動新藥開發。他們不只是「做實驗」,而是打造了一條從資料、演算到驗證的高速通道。
① 掃描自然界的「寶庫」
他們從亞洲地區的草藥、真菌、微生物中,累積超過一千萬筆天然化合物資料,搭建起一座專屬的「天然分子圖書館」。這些成分在傳統醫學中早有使用紀錄,但未曾被系統性地分析與開發。
② 讓 AI 模型預測哪些有潛力
接著,他們啟動自研的 AI 模型 DTIGN(Drug-Target Interaction Graph Neural Network),模擬這些分子和疾病靶點之間的交互作用,像是在幫每一顆分子做「模擬面試」:這個成分有可能對抗癌細胞嗎?會不會干擾代謝系統?
DTIGN 能從數以百萬計的分子中,預測出幾百個「值得實驗的潛力股」。
③ 進入實驗室驗證
最後,真正進入實驗階段的分子會進行:
- In-vitro(體外)測試:在細胞層級觀察效果
- Pre-clinical(臨床前)研究:進入動物模型驗證安全性與療效
如果結果理想,才會申請進入 Clinical Phase I(臨床一期) 的人體試驗
DTIGN 是什麼?圖神經網路如何看懂「分子和藥效」的關係?
在 Nanyang Biologics 的技術核心裡,有一個聽起來很酷的 AI 模型 DTIGN「藥物-靶點交互圖神經網路」,英文為 Drug-Target Interaction Graph Neural Network。這個模型最關鍵的功能是,它能模擬一顆藥物分子,有沒有機會對某種疾病產生效果。
但在解釋 DTIGN 如何判斷「藥物有沒有藥效」之前,先讓我們介紹藥物開發中兩個關鍵的概念:分子 和 靶點。
🧩 分子與靶點,是什麼意思?
想像你家門壞了,需要一把能開門的鑰匙。
- 分子(Molecule) 指的是構成藥物的化學結構,就像是各種形狀不同的鑰匙,例如常見的止痛藥中,ibuprofen 就是一個分子,它具有特定的形狀與功能。
- 靶點(Target) 則是那一把鑰匙要開的門鎖 —— 通常是一種和疾病有關的 蛋白質、酵素或受體。比方說 HER2 就是乳癌中的常見靶點;如果能精準抑制它,就可能對癌細胞產生抑制效果。
如果鑰匙插得進去、轉得動,就有機會解決問題(比如關掉癌細胞、減少發炎反應)。
但問題是:人體裡的鎖成千上萬,而大自然給我們的鑰匙更多。
藥物研發團隊要從數以百萬計的分子裡找出「哪一把鑰匙可能打得開這個鎖」,難度可想而知。
🧠 DTIGN 怎麼預測?靠三個 AI 技術核心
① 圖神經網路 GNN(Graph Neural Network)
想像每一顆藥物分子,就像是一座樂高積木城堡。
有些積木是角落,有些是塔樓,組合方式千變萬化。AI 就是那個看過無數座城堡的高手,它可以快速判斷:「這個結構,有可能剛好對應到某個疾病的破口嗎?」
- 分子其實就是一張圖!
一個藥物分子由原子構成,每個原子可以視為一個「節點」,原子與原子之間的鍵(連接)就是「邊」。
GNN 擅長處理這種由點與連線構成的資料結構,所以非常適合用來「理解分子的形狀與功能」 - GNN 比傳統神經網路更能掌握「結構」與「上下文關係」,讓它在像分子這種「連結很重要」的任務上表現更精準。

延伸閱讀:Graph Neural Network Tutorial 圖神經網路教學
② 自注意力機制(Self-Attention)
不是每塊積木都重要。有些只是裝飾,有些卻是關鍵支撐點。
AI 會自己學著去注意那些特別關鍵的區塊,比如一顆分子裡面真正能作用的「尖刺」或「鉤子」。這種自我聚焦的能力,叫做「自注意力」,就像你在找房子時,自動只看廁所跟採光,不浪費時間在看牆壁顏色一樣。
- 自注意力機制是 Transformer(ChatGPT 類模型)中常見的技術,DTIGN 把它用來「關注分子中重要的片段」。
- 它就像是幫助模型自己判斷:「哪個原子結構最有可能產生藥效?」
③ 半監督學習(Semi-supervised Learning)
真實世界不是教科書,很多分子根本沒人測過好不好用。
但 AI 就像一個在補習班旁聽的學生:雖然只有部分題目有解答,但它看久了還是能抓出規律。
這叫做「半監督學習」——讓模型在「部分知道答案,部分不知道」的情況下也能進步。
🧪 DTIGN 的成效如何?不只是快,更讓新藥命中率大幅提升
DTIGN 並不是概念模型,而是已實際應用在 Nanyang Biologics 的新藥發現流程中,並帶來了顯著效益。根據官方公開數據顯示:
- 命中率(Hit Rate)提升 64 倍
相較傳統高通量篩選方法或一般 docking 軟體(如 AutoDock、DeepDTA),DTIGN 能更有效率地預測哪些分子值得進入實驗。
→ 這代表本來可能要測上萬個分子,現在幾百個就能找到目標。 - 預測精準度提升 27.03%
DTIGN 透過圖神經網路與自注意力機制,在測試資料集上相較其他 AI 模型更能準確預測藥效強度(例如 pIC₅₀),讓「虛擬篩選」更可信,減少實驗誤投。 - 研發時間縮短 60–70%
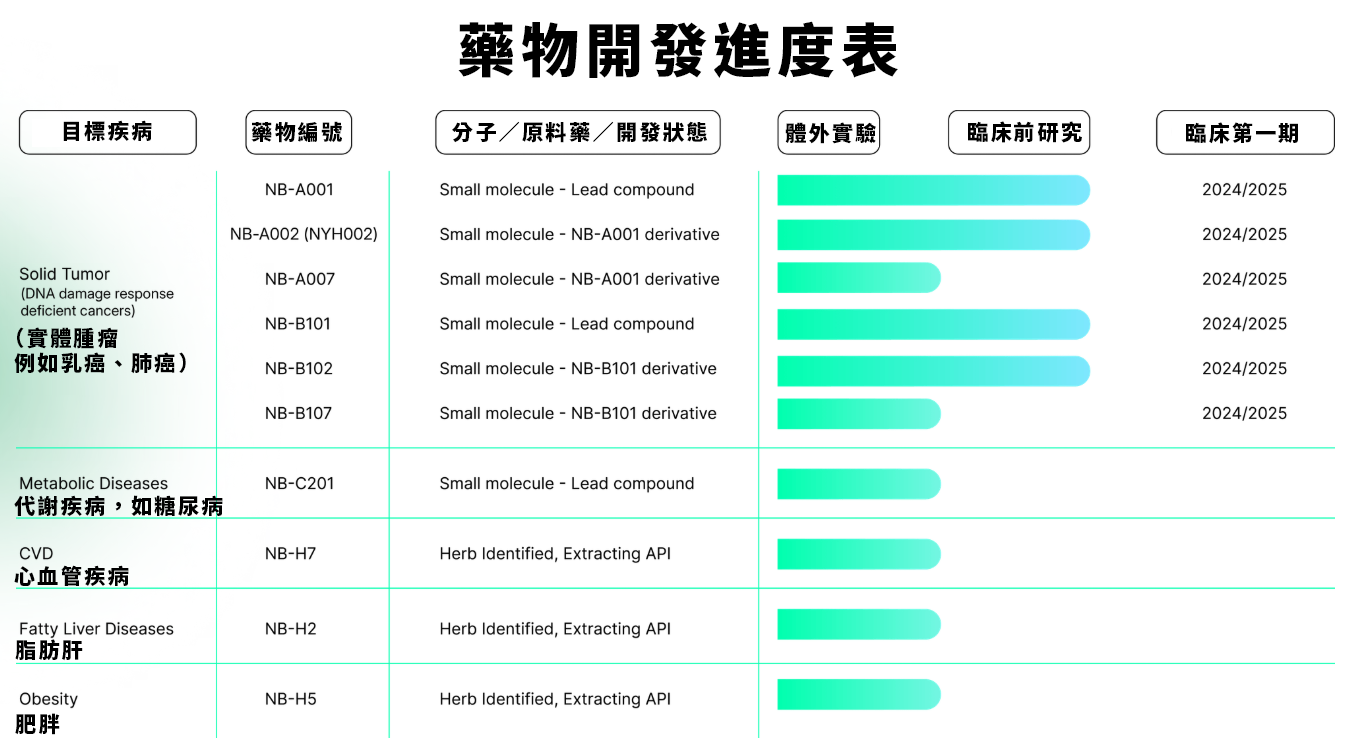
從資料整合、篩選到臨床前前期設計,早期階段的決策周期大幅縮短,讓 Nanyang Biologics 能夠同時推進多條研發管線,並預計在 2024/2025 年啟動多項臨床一期試驗。
🔚從「慢慢找」到「快速篩選」,新藥開發正在被改寫
下一代新藥,可能不是從實驗室撞出來的,而是由 AI 在自然中「算」出來的。
像 Nanyang Biologics 是透過自亞洲天然資源的大型分子資料庫,結合圖神經網路(GNN)與分子模擬技術,快速預測哪些成分可能對疾病有用。
而在全球也出現了許多用不同方法結合 AI 進行藥物開發的團隊,各自打開不同的路徑。
- Atomwise 走的是「結構模擬型」路線,利用深度學習來模擬藥物分子與靶點蛋白之間的三維結合(對接,docking),一次可虛擬篩選上億個分子,適合用於大規模初步探索。
- Recursion Pharmaceuticals 則主打「細胞影像型」,他們讓 AI 看大量顯微鏡影像資料,觀察細胞在不同藥物下的變化,從而反向推敲哪些分子可能有效,即使不知道這些分子長什麼樣。
- BenevolentAI 採取的是「知識圖譜型」,讓 AI 自動讀懂科學論文、基因資料與醫療知識圖譜,找出潛在的疾病機轉與治療連結,甚至在 COVID-19 疫情期間提出了有效用藥的建議。
這些團隊雖然方法不同,但指向同一件事:
AI 不只是加速工具,而是新藥發現的起點。




{kind=link}