2026 CES 第一槍:NVIDIA Alpamayo 亮相,打破過去十年的自駕模型架構


歡迎來到 2026 年的第 1 週。沒想到才從耶誕假期結束,AI 圈就已經炸開來了,首先是 NVIDIA 在 2026 CES 首次亮相的 Alpamayo 自駕「開源推理」模型。另一個則是前陣子剛從 Meta 離職的 Yann LeCun 親口爆料的 Meta Llama 跑分造假醜聞(原本是要以這個為標題的,但覺得有點 Click Bait 的嫌疑,想想還是算了)。
本週也收錄 Google 工程師 Jaana 用 Claude Code 一小時,完成團隊花了一整年的架構工作。在這篇裡面我們整理了 Jaana 在 AI Coding 的心得。從開源技術到業界八卦,再到 Prompt Engineering 的實戰技巧,本期內容非常多元。
同時,我們也啟動醞釀一陣子的 AIPost 「影響力講師」計劃。

麥肯錫 2025 年的全球 AI 調查報告 指出,AI 的採用率雖然攀升至 88%,但其中只有 6% 的企業真正從 AI 創造商業價值,市場上充斥著太多「只教工具」的雜訊,導致無論是企業或是個人在導入 & 使用 AI 上充滿疑慮。我們希望建立一個具備「實務導向 × 專業審核 × 認證價值」的平台,找回 AI 教育中失落的信任感。
所以我們與國際專業機構合作,打造一套嚴謹的 AI 課程體系。如果你擅長的是能把 AI 真正落地到工作流中,解決真實的產業問題,我們正在找你。
- 限額審核: 第一批僅開放核心講師申請,採取領域限額與滾動式審核。
- 優先規劃: 入選者將優先納入後續的長期課程、企業培訓與跨域合作。
📌 備註: 本表單為「背景初審」,提交不代表保證合作。我們將由專業顧問團隊審核後,主動聯繫合適人選。
工商結束了!馬上讓我們進入本週的五件 AI 大事,
讓你不只是看熱鬧,也能看懂門道。
本周焦點事件
- 2026 CES:NVIDIA Alpamayo 正式亮相,開源的自駕推理型 AI
- Llama 4 跑分造假!前圖靈獎得主 Yann LeCun 爆料 Meta 內部亂象
- 【2026 AI 關鍵活動|主編精選】麥肯錫:只有 6% 的企業,真正用 AI 創造價值
- 不再讓 AI 睜眼說瞎話:Meta 提出的「驗證鏈(CoVe)」技術如何改善 AI 幻覺?
- Claude Code 僅用 1 小時,完成 Google 團隊一年的架構工作
2026 CES:NVIDIA Alpamayo 正式亮相,開源的自駕推理型 AI

在 2026 年的 CES 演講中,NVIDIA 執行長黃仁勳搶先發布了 Alpamayo,名子取自秘魯著名的山 Alpamayo。這款全球首個開源的「推理型」自駕模型,標誌著自動駕駛技術的重大突破,從過去依賴反射式的「感知模型」進化到如今具備邏輯推理的「推理型模型」,終於讓車輛不只是看到障礙物,還能理解交通場景中的因果關係,並「解釋」自己的決策。
什麼是 Alpamayo?
過去十年,自動駕駛主要依賴感知模型,也就是車輛透過感知系統(如雷達、cam)來感知環境並作出反射性動作,比如閃避障礙物。
Alpamayo 的出現徹底改變了這一局面。它基於 VLA(Vision-Language-Action,視覺-語言-行動) 架構,賦予車輛一個「大腦」,使其能夠進行推理、解釋並語言化描述其決策過程。具體來說,Alpamayo 不僅能看到前方的障礙物,還能推斷障礙物的移動目的,並且可以像人類一樣解釋它是如何做決定的:「因為左側行人距離過近,我決定減速並向右微調。」
罕見的開源戰略:打破自駕開發的黑盒子
NVIDIA 不僅推出了創新的自駕技術,還決定採取開源策略,將 Alpamayo 1 模型 和 AlpaSim 模擬框架 完全開源,並同步上架 GitHub 和 Hugging Face。
AlpaSim:自駕車最難的是處理極端天氣或罕見車禍。AlpaSim 提供了一個完全開放的模擬環境,讓開發者可以在虛擬世界中測試數百萬英里的極端情境,而不必冒著實體車損壞的風險。
同時釋出超過 1700 小時的高品質駕駛數據。這些數據不只是影片,還包含了標註好的資料,讓中小型車廠不需要具備 Google 或 Tesla 那樣的數據收集能力,也能訓練出高水準的模型。
Llama 4 跑分造假!前圖靈獎得主 Yann LeCun 爆料 Meta 內部亂象

2024 年底,Meta 為了追趕 OpenAI 的腳步,不惜砸下重金與資源在 Llama 系列模型上。萬萬沒想到的是,2026 年才剛開始就有震撼彈,竟然還是由 Meta 自己的「AI 教父」炸開的。
Yann LeCun 不僅是 Meta 過去十年的首席 AI 科學家,更是獲得圖靈獎的三位 AI 教父之一。 近日在接受《金融時報》(FT)的告別採訪中,LeCun 不僅宣布離職創立新公司,更直接「暴力地」撕開 Meta 內部的權力鬥爭與造假醜聞。
當 65 歲的教父要向 28 歲的少年報告
LeCun 在採訪中透露,因為 Mark Zuckerberg 對 Llama (Meta 自家的模型) 進度緩慢的焦慮,所以在去年夏天豪擲 140 億美元投資 Scale AI,並挖角年僅 28 歲的創辦人 Alexandr Wang,讓其執掌新成立的 Superintelligence Labs。

LeCun 在採訪中毫不留情地評價這位新上司:「年輕、缺乏研究經驗,他根本不懂什麼叫研究,更不知道什麼會吸引或是惹毛一個研究員。」他額外說了:「你不能告訴一個研究員要做什麼,尤其是不能告訴像我這樣的研究員要做什麼。」畢竟對於 LeCun 這樣的 AI 教父,上司的角色應該是提供資源,而非管理,就像過去 Zuckerberg 做的事一樣。
同時,LeCun 選擇暴力揭疤,親口證實:Meta 內部「操弄」了 Llama 4 的基準測試。他們透過更換不同模型來對應不同的測試,以此美化數據。這件事在內部曝光後,Zuckerberg 對整個 GenAI 團隊失去信心(與 LeCun 身處的 FAIR 團隊不同),這也是為什麼他轉而將權力交給外來的 Alexandr Wang。
教父的華麗轉身:AMI Labs 啟動,法國總理的私人簡訊
LeCun 雖然離開了 Meta,但他並不是落寞退場。相反地,他隨即宣布成立新公司 AMI Labs(Advanced Machine Intelligence),且一出場就瞄準了 30 億美元 的估值。他的新戰友是法國 AI 醫療新創 Nabla 的創辦人 Alex LeBrun。LeCun 透露,法國總理馬克宏甚至親自傳了簡訊給他。兩人聯手的目標明確:拋棄 LLM 的死路,直接攻克「世界模型」。
觀察筆記
在資本市場面前,科學真理往往得讓位給股價,但對於 Yann LeCun 這種等級的科學家來說,這些全是 Bullshit。
我相信大家對 LeCun 是極有共感的。在他眼裡,LLM(大型語言模型)就是一條死路,他已經不只一次在公開場合暗示這點。所以,無論 Zuckerburg 或新官上任的 Alexandr Wang 怎麼逼他,他都不想、也不會去研究這個他認為「沒前途」的東西。
對 LeCun 來說,待不待 Meta 根本不重要,他要的是能專研領域的絕對自由。但諷刺的是,正因為他身為「首席 AI 科學家」這個神主牌角色,Meta 為了護航 Llama 的商業敘事與股價,長期對他下達了禁言令。
俗話說的好,拿槌子的人,看什麼都像釘子。 Zuckerburg 投入數百億美金為的不是五至十年後的 AI 技術進化,而是當前 Llama 模型的成長速度。當這兩者發生碰撞,偽造的跑分只是裂痕的開始。真正的代價在於,矽谷巨頭可能在追逐 5% 的數據成長的 KPI 時,錯過了下一個 100 倍的變革。
【2026 AI 關鍵活動|主編精選】麥肯錫:只有 6% 的企業,真正用 AI 創造價值

AI 正在被「廣泛使用」,卻鮮少被「深度整合」
根據麥肯錫 2025 年的全球 AI 調查報告,AI 的採用率已攀升至 88%。換句話說,AI 已完成從「新奇嘗試」到「辦公標配」的轉型。然而,真正能將 AI 轉化為企業層級商業價值、實質反映在損益表上的企業,竟然僅佔 6%。
為什麼 88% 的熱情,最終只換來 6% 的成果? 關鍵不在於模型「夠不夠聰明」,而在於「信任」與「權限」。當 AI 給出建議時,決策者心中往往存在三個心魔:
- 數據來源疑慮: 這資料哪來的?(是不是拿過期的數據在算?)
- 邏輯黑盒子: 這建議能解釋嗎?(它是憑邏輯還是憑感覺?)
- 責任歸屬: 萬一出錯,誰要負責?
當企業的資料基建尚未打底、治理邏輯混亂時,AI 就永遠只能是一個「懂聊天的查詢工具」,被擋在權限結構之外,觸碰不到價值創造的核心。
很多企業急著引進應用,卻只是把原本混亂的流程變得更混亂。我們認為,AI 獲利有一條不可跳過的邏輯:
資料基建(打底) ➔ 資料治理(定規矩) ➔ AI 導入(工具) ➔ 決策智能(獲利)
這也是為什麼,我們特別推薦本週這場深談實務的活動。
這場活動不教你「多用一個工具」,而是分享一套「結構性的解法」。我們將從最底層的資料整合出發,延伸到 2026 年最核心的 AI Agent(AI 代理人) 應用,最終直擊核心:如何讓 AI 進入決策流程,轉化為真實利潤?
如果您感覺手上的 AI 工具仍停留在「局部優化」,尚未觸及組織靈魂,這場對話將是您的關鍵轉捩點。
【 活動資訊 】
- 活動主題: AI-INSIDE:中小企業 AI 化的第一哩與最後一哩
- 活動日期: 2026 年 1 月 14 日 (三)
- 活動地點: 台灣微軟 19F (台北市信義區)
- 報名方式: 免費報名、審核制(名額有限,建議儘快登記)
不再讓 AI 睜眼說瞎話:Meta 提出的「驗證鏈(CoVe)」技術如何改善 AI 幻覺?
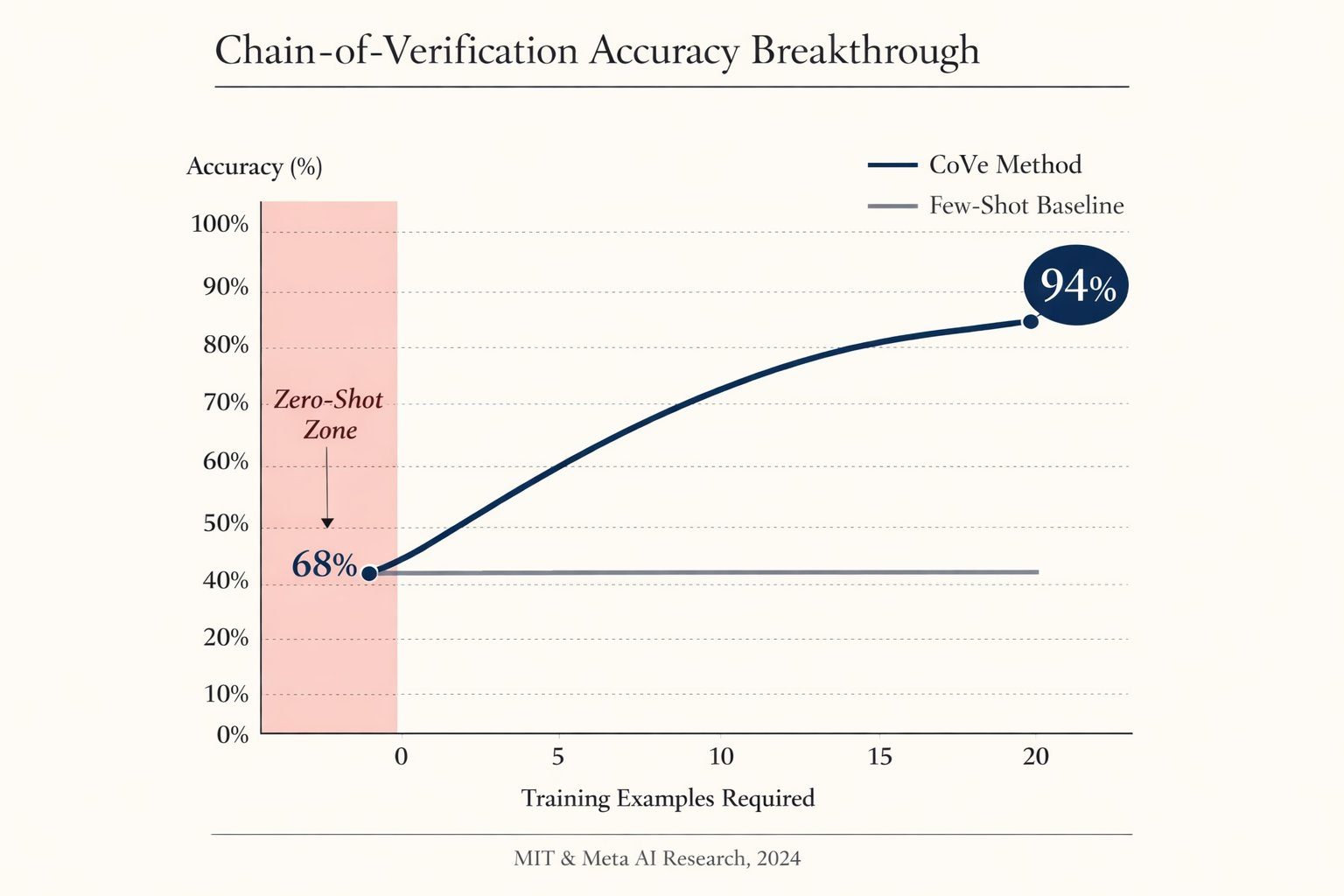
CoVe 全名 Chain-of-Verification,是由 Meta AI Research 於 2024 年發表的研究成果,透過這種 Prompt Engineering 可以讓 AI 產生自我糾正的迴路,進而降低 LLM 在生成內容時的「事實性」幻覺。
即便現在已經是 2026 年,當你要求 AI 處理高度依賴事實的任務時,CoVe 的效果仍舊為目前最顯著的 Prompt Engineering 技巧,而且適用於目前所有主流的 LLM。事實上,只要模型的架構仍處在「機率式」的預測回答,CoVe 就是 AI 時代與 AI 互動的一個利器,因為可以強迫模型從直覺反應轉向邏輯查證。
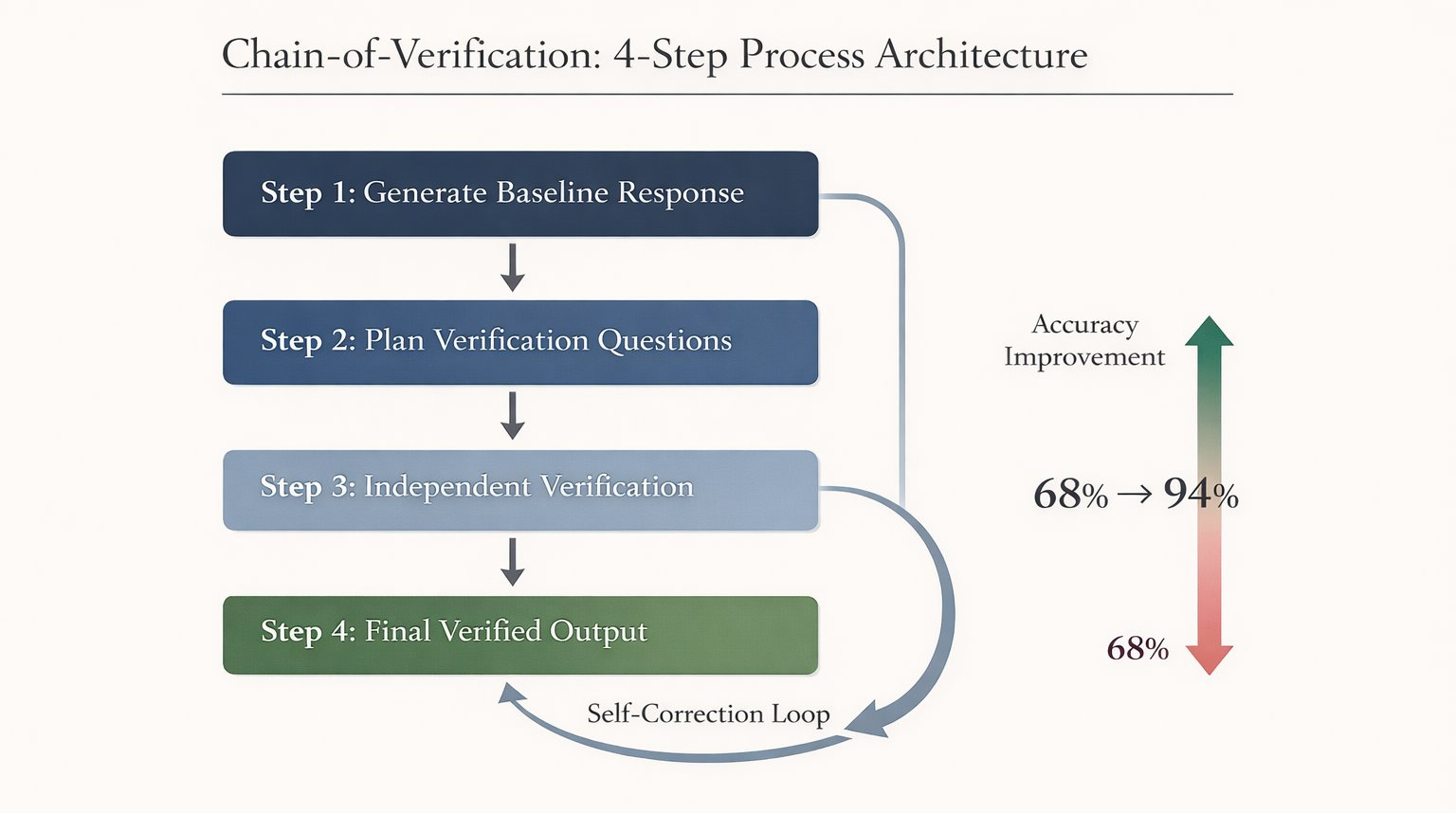
如何使用 CoVe 的 Prompt Engineering 技巧
(可以不用每次都加入,請於需要時加入即可,尤其前面提到的「高度依賴事實任務時」):
在提示詞中加入:
針對以下問題,請執行 CoVe 流程:
- 先給出初步回答。
- 列出該回答中哪些事實需要核實?
- 逐一針對這些事實進行查證。
- 根據查證結果,修正並提供最終準確答案。
Claude Code 僅用 1 小時,完成 Google 團隊一年的架構工作
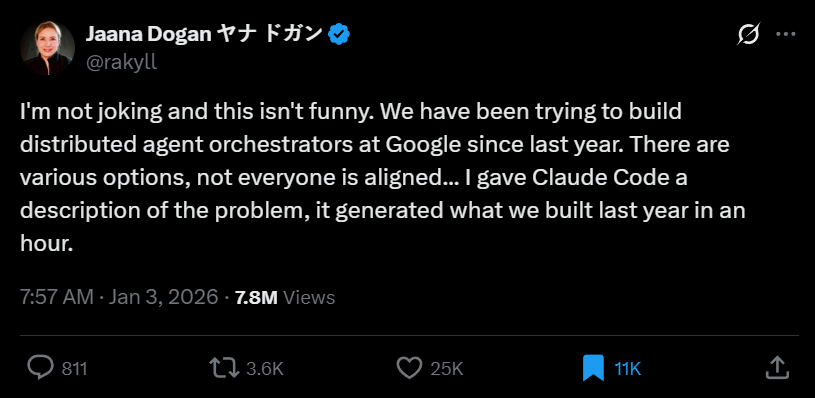
Jaana Dogan(現為 Google Cloud 首席工程師)透露,Google 內部從去年開始就一直在嘗試構建 「分散式代理人編排系統 (Distributed Agent Orchestrators)」。你可以把它想像成「管理一堆 Agent 的作業系統」,假設你想找某個產業別的職缺,這個作業系統可以接收指令、拆解任務,並分配其他 Agent 執行。如果實際上想看這種架構如何運作,可以參考 Manus 的 WideResearch 功能。

讓我們回到 Claude Code 的話題上,Jaana 給了 Anthropic 推出的新工具 Claude Code 一段約三個段落的文字描述。這段描述僅僅是問題的定義,並未包含任何 Google 內部受保護的原始碼或商業機密。結果 Claude Code 在短短 1 小時內,就生成了 Google 頂尖團隊耗時 1 年才構思出來的系統架構原型。
而針對那些對 AI 寫程式持懷疑態度的人,Jaana 給出了非常具體的建議:
- 永遠要在你的專業領域測試: 不要只叫 AI 寫簡單的程式,而是去寫一個你已經是「專家」的複雜領域。
- 親自審判成果: 從零開始構建複雜系統,因為只有專家才能判斷 AI 生成的成品究竟是垃圾,還是具備實戰價值的傑作。
Jaana 讚嘆的不只是 Claude 的聰明,而是 Antropic 打造的整個環境:
- 環境感知(Context Awareness): Claude Code 不只是讀一個檔案,它能理解整個專案目錄的結構。它知道你的
Database.py會影響到User.py。 - 自主循環(Self-correction): 當它寫完程式碼,它會主動執行測試。如果噴出錯誤訊息(Error Log),它會自動讀取 Log 並自我修正,直到測試通過。
- 高密度的邏輯壓縮: Jaana 提到的驚人之處在於,她只給了三段話(意圖),Claude Code 就能在它的 Harness 裡,利用對分散式系統的「深層知識」,迅速組裝出符合邏輯的架構。
喜歡這期內容嗎?有哪一則讓你特別有感?
歡迎回信或是 Instagram 告訴我們,我們會偷偷讀大家的回覆的!
我們下周見
—AI郵報 編輯團隊



