還在人工 copy 問 GPT?Capalyze 幫你從 Threads、地圖、短影音全自動抓留言還能做分析
Capalyze 幫你自動爬 Threads、TikTok、Google Map 留言,一鍵結構化資料、分類情緒、生成圖表,讓你跳過繁瑣爬蟲,直接開始資料分析。


你可能聽過很多「資料分析神器」:幫你做報告的 AI、幫你跑圖表的 AI、甚至幫你寫洞察結論的 AI。
但真正開始做資料分析之後你會發現——問題根本不在分析那一步,而是:你有資料可以分析嗎?
我們遇過太多分析師、行銷人、研究生,光是「資料怎麼抓」、「要不要寫爬蟲」、「平台限制怎麼解」這一段,就已經卡掉 80% 的時間。
如果你沒有掌握一手資料,後面那些再聰明的 AI 工具,也只是漂亮的 PPT 而已(或是單純話唬爛)。
這也是為什麼今天會跟大家介紹一個我們認為非常厲害的產品 —— Capalyze。因為它解決的,正是大部分人卡最久的那一步:資料取得與結構化。
資料分析流程的 4 個關鍵步驟
所以,資料分析真正的流程,從來不是「丟表格給 AI」這麼簡單。
我們把它拆成四個步驟來看——
收集資料
你得先有東西能分析。可能是社群留言、商品評論、地圖評價,或來自各種平台的一手使用者回饋。但這一步,往往是整個流程裡最難啟動的。
我們以前介紹過,如果想試試資料分析的流程,其實可以從 政府開放資料平台 下手,先熟悉怎麼找資料、怎麼清洗結構、怎麼丟進 AI 做分析。但現實是:很多資料根本就不在開放平台上,特別是社群聲量、用戶評論這種「活的內容」。你想抓,卻沒地方抓;你有方向,卻沒有資料可跑。
清洗與整理
資料抓下來之後,真正的災難才開始。
(開始回想自己當初瘋狂找 YouTube 教學,學怎麼把 Excel 表格整理乾淨,怎麼用公式拆字串、分欄、對齊格式……)你會遇到一堆格式錯亂的內容:有些有標點、有些全是表情符號,有些根本一句話裡塞了三個概念。而最困難的地方在於——你要幫這些雜亂無章的文字「長出骨架」。
這個骨架,指的就是結構:
誰說了什麼、什麼時候說的、說的是哪一件事、屬於哪一類問題。
只有當這些東西被清楚地標示出來,這些文字才真正從「內容」變成了「資料」。
而這一步,剛好就是 AI 特別擅長的地方。
大多數資料分析用的 AI 工具,其實也是從這一步才開始介入整個 pipeline。
分析與視覺化
當你把資料整理成乾淨的欄位、標籤、時間戳記,這時不論你用的是 GPT、Claude、Notion AI、Power BI 還是 Tableau,它們都能幫你生成漂亮的圖表、做關鍵字頻率分析、跑情緒分類,甚至給出初步的觀察結論。
很多人以為資料分析就是從這裡開始的。
但我們都知道,如果前面的資料結構不對、欄位沒整理好,分析結果也會失真。
而且這一步做出來的結果也只是「第一輪初步」,真正有價值的 insight,還得靠你自己進一步解讀。
詮釋與調整策略
這一步,才是資料分析師真正展現價值的時候。
你要看得出哪一張圖表只是漂亮、哪一組數據背後其實有偏誤,
你要知道使用者說「方便」,指的是 UX 設計、還是門市取貨?
留言裡那一句「還不錯」,到底是口頭禪,還是真心推薦?
甚至很多分析師會回過頭,重新讀一輪原始評論,做第二層的詮釋與分類:
- 哪些評論是情緒化發言但內容有價值?
- 哪些詞其實在不同上下文代表完全不同意思?
- 哪些低頻詞雖然出現次數少,但可能藏著產品的真痛點?
AI 幫你跑出第一層的資料摘要沒錯,但真正能提出策略建議、落地調整、產品優化方向的,還是你自己。
解決資料分析斷點的 AI Tool ─ Capalyze
你可能曾經想要分析 TikTok 上的熱門商品聲量,想看 Threads 上大家對某個品牌的真實評價,或者只是單純想知道某間餐廳的 Google Map 評論,哪個點最常被抱怨。
但問題是——
你沒辦法自己寫爬蟲,平台又沒開 API,登入狀態還限制一堆,
好不容易抓下來的內容還是一團亂:時間、用戶、留言內容全部混在一起。
這些都還沒進入分析本身,整個資料分析流程就已經崩潰了。
而 Capalyze,做的就是這一段。它不是來幫你跑圖表,而是直接幫你從社群平台上把資料「拉乾淨」拉結構化——不論是 TikTok、Threads、小紅書還是 Google Map,你只要下 prompt,它就能幫你抓到一手內容、轉成結構化欄位,甚至初步情緒分類、關鍵字整理都幫你做完。
它解決的不是「分析問題」,而是幫你把資料這件事準備好,讓你能開始分析。
這也是為什麼 Capalyze 特別重要——它讓更多人的 Action 不再只是憑感覺,而是可以 Based on Data。
不是每個人都要變成資料分析師,但 Capalyze 讓更多人能夠「像資料分析師一樣思考、啟動、決策」。當資料變得可取得、可閱讀、可操作,下一步你要怎麼做,就變得清楚多了。

🧠 Capalyze 不只是資料工具,而是一種新工作方式
你不是不會做分析,只是沒有人幫你把資料抓好、整理好、準備好。
Capalyze 幫你跨過最費時的前置作業,從資料抓取到欄位結構、評論分類、聲量排行,一鍵完成。
Capalyze 怎麼用?實戰場景 Showcase:四個應用案例
你可能會問:了解了 Capalyze 的原理,那實際上要怎麼用?
以下整理四個最常見、也最有感的使用場景,從日常決策、行銷洞察,到職場分析報告,讓你看看它怎麼在「還沒分析前的那一步」,幫你把資料變乾淨、變有用。
案例一|找出 Threads 上對某品牌/網紅的真實評價
你是一位品牌行銷人,正在規劃聯名合作的對象,但擔心社群上有負評沒被掌握到。這時只要輸入:
prompt:
1. 先在 Threads 上找到關於品牌 X 的討論串,將連結複製下來
2.分析 Threads 上(可以加上時間,如一週內)討論「品牌 X」的留言,整理品牌的情緒分類、關鍵字分析,以及
Capalyze 就會藉由他們的瀏覽器擴充外掛,從 Threads 拉下相關留言,幫你做資料採集,接著他們會將這些非結構資料,讓 AI 初步整理出乾淨的欄位表格,包含:留言時間、帳號、內容、情緒標籤、頻率最高的用詞等,接著點開始採集,Capalyze 便會開始大量的去爬取該網頁的所有內容,直到你按下停止。
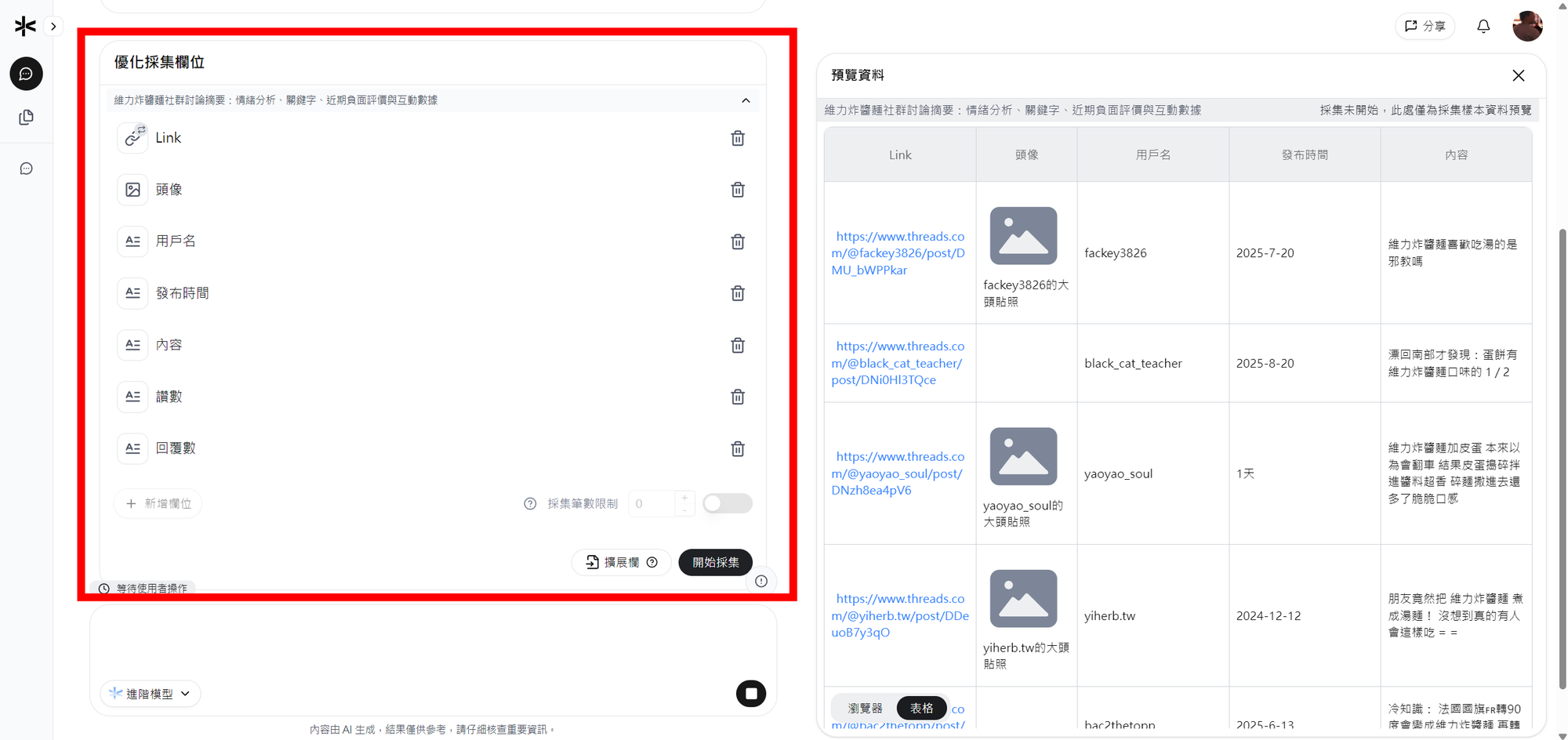

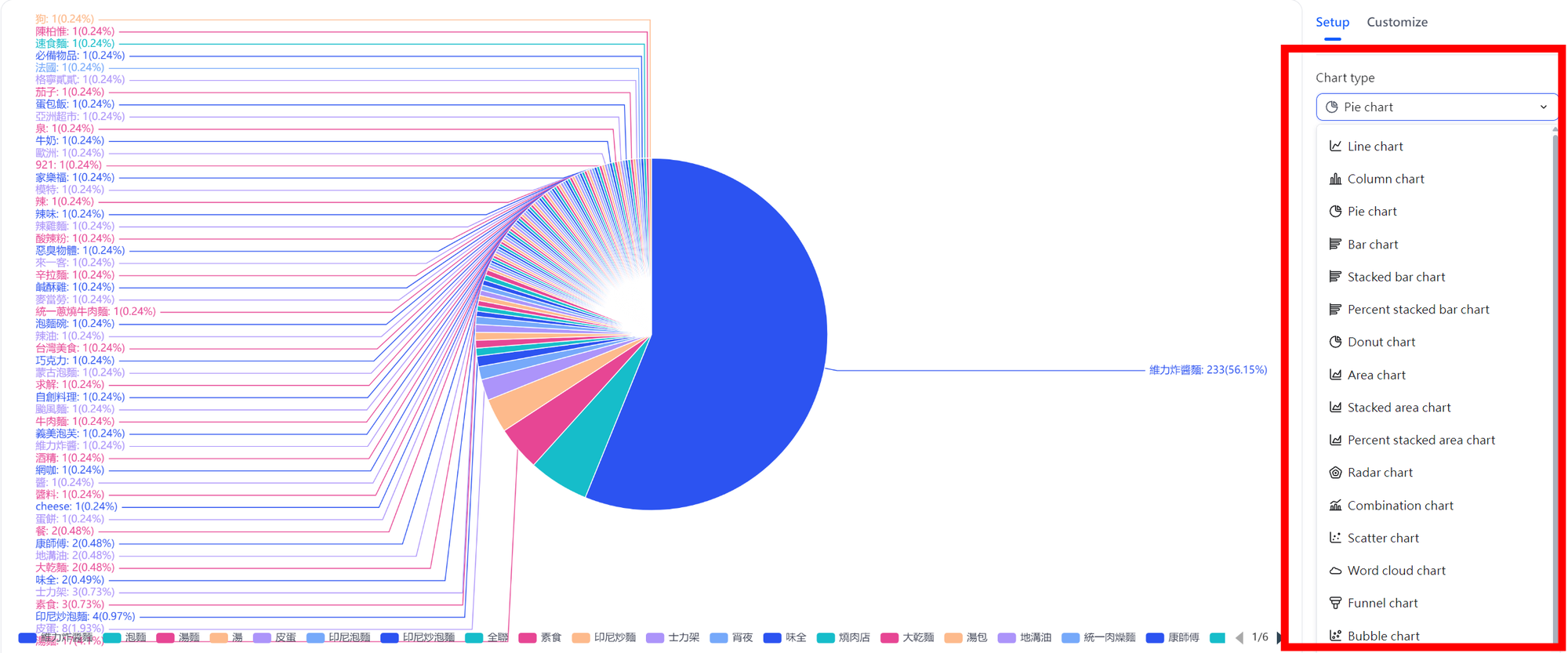
完成之後,你可以一眼看出網友對品牌印象的轉變趨勢:是單一事件造成負評?還是長期口碑正在流失?更進一步,你還能點進去,將這些數據轉換成各種可視化圖表(折線圖、詞雲、圓餅圖…隨你切換),讓趨勢變得一目了然。
案例二|分析 TikTok 上爆紅商品的關鍵痛點
想像你是一位電商老闆,最近看到一支 TikTok 商品影片播放破百萬,留言區熱鬧到不行。但問題是,你怎麼知道大家真正討論的焦點是「商品真的好」,還是「被廣告洗出來的假熱度」?
這時你可以輸入:
prompt:爬取這個 TikTok 標籤下的所有影片,分類使用者提到的優點、缺點與建議,並統計關鍵字出現頻率。
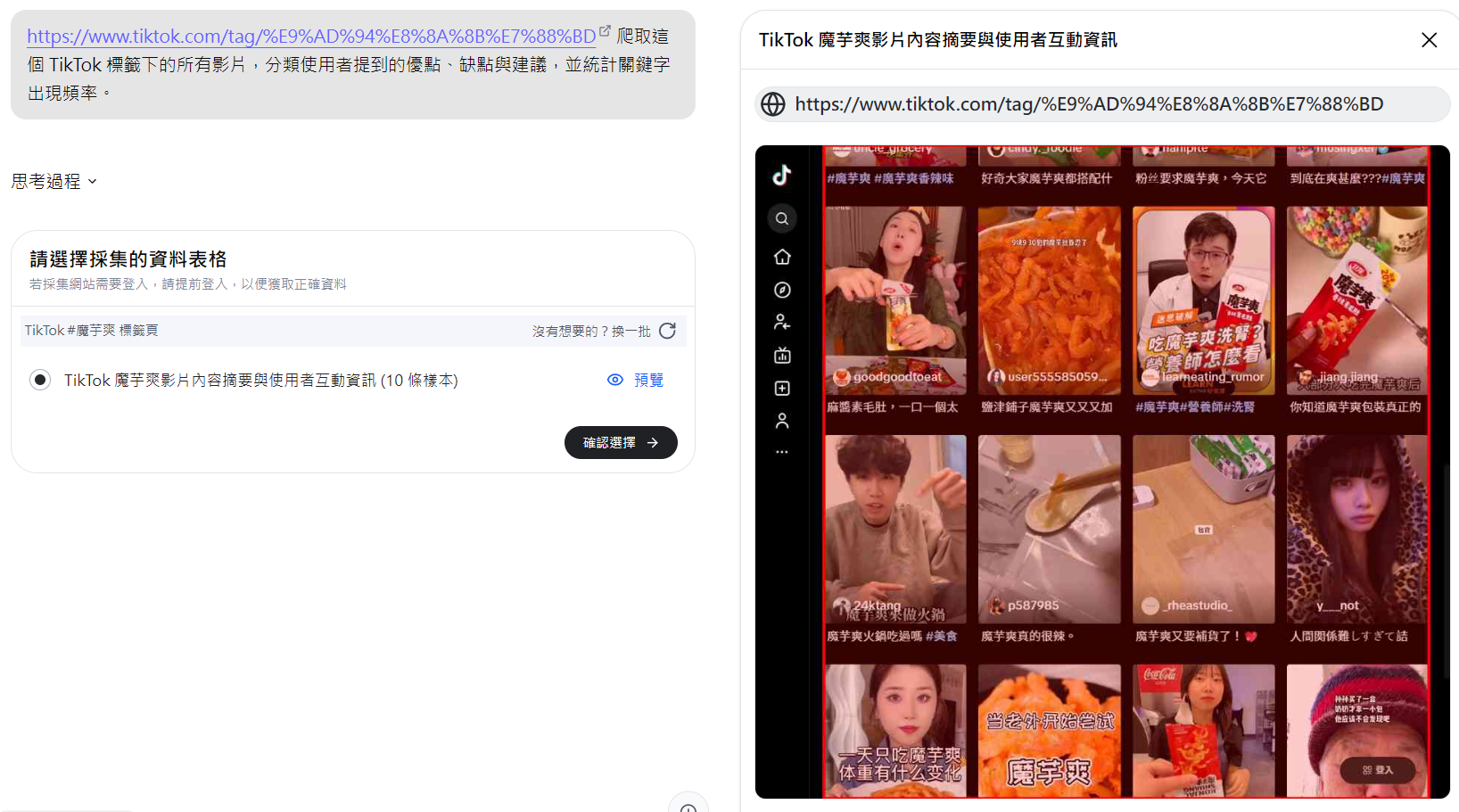
Capalyze 會先把影片相關資料自動整理成欄位化格式:包含影片描述、使用者名稱、影片封面等。接著,它會進一步幫你分類留言,快速區分出常見的讚美(如「魔芋爽」「衛龍」「零食推薦」)、以及抱怨(如「洗腎」「垃圾食物」「健康」)。

完成後,你會立刻得到一份使用者回饋總覽報告:
- 哪些優點最常被提到?(如「零食推薦」「衛龍」)
- 哪些缺點正在快速累積聲量?(多數集中於健康疑慮,例如「洗腎」「傷腎」)
- 建議與推薦的比例是否有失衡?(例如「吃貨」「好物分享」 vs. 健康擔憂)
更重要的是,這些結果不只是一張靜態表格。你還能進一步切換成多種互動式圖表:像「優缺點分布圓餅圖」、「關鍵字雲」、「情緒走勢折線圖」等。這些可視化成果,能幫你更快看清趨勢,甚至直接拿來做內部簡報,節省大量整理時間。
案例三|批次蒐集 Amazon 上產品資訊,建立競品資料庫
你是一位品牌經理,準備規劃新一季面膜系列商品,想先整理市面上熱銷產品的定價、包裝與賣點,做為內部討論依據。但 Amazon 上資訊分散,每個頁面格式又略有不同,手動整理既耗時又容易出錯。
這時你可以輸入:
prompt:請幫我採集 Amazon 上「face mask」的產品資訊
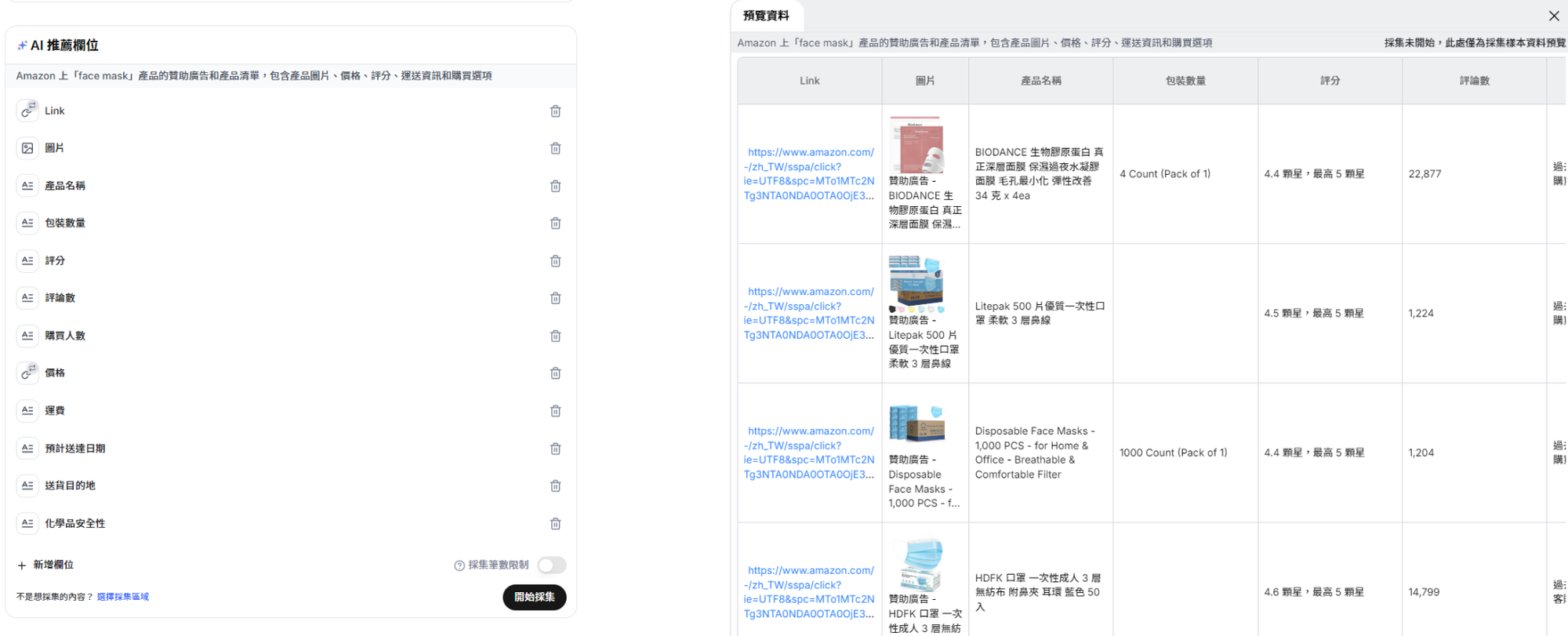
Capalyze 就會開始幫你蒐集資料,不只能拉出一頁商品列表,還能「像人一樣」自動點進每個商品頁,抓下所有關鍵欄位。如下圖所示,最終你會得到一份乾淨的資料表格,包含:
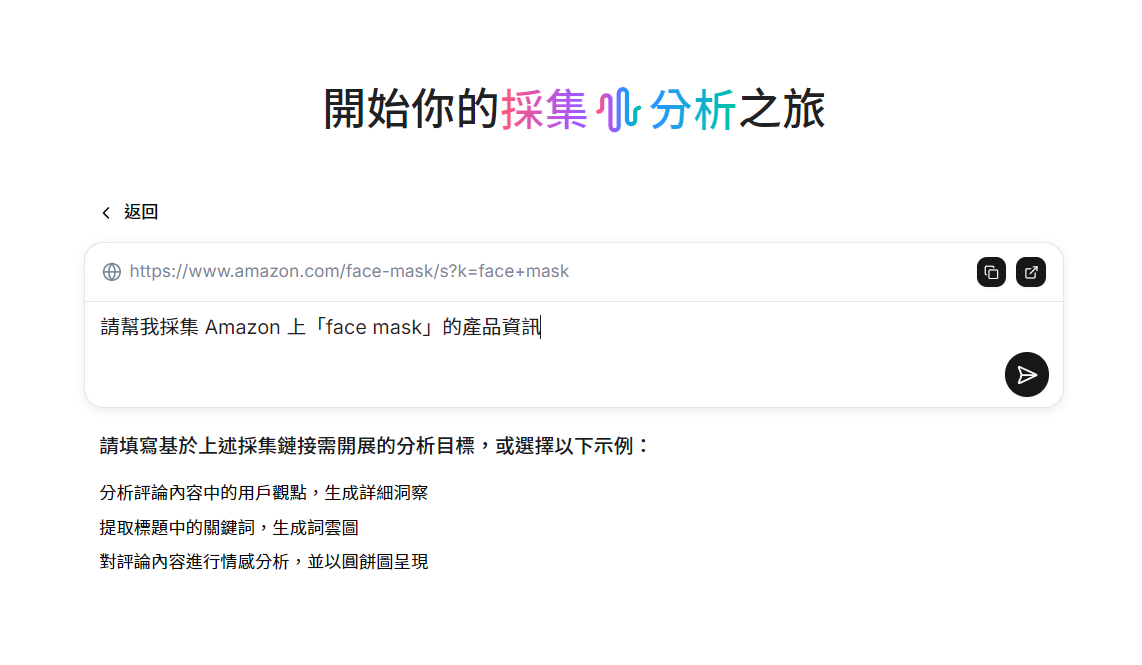
📦 商品名稱📷 商品圖片💲 價格與運費🌟 星等與評論數👥 購買人數、預計送達時間🧪 化學品安全性說明(如有)
這些欄位會被自動轉為可篩選的表格資料,讓你可以直接貼進 Excel、Notion、Airtable,作為競品分析、內部簡報、或行銷企劃資料。
你也可以延伸應用這份資料來做:
- 價格帶分析:平均售價、品牌價格分布
- 包裝策略參考:包裝數量與單價的搭配邏輯
- 買氣熱度預測:評論數與星等的分布
而這整段流程,不需要寫一行程式,也不用請工程師幫你打 API,只要一段 prompt + 一個開始按鈕就搞定。
案例四|一秒搞懂 Google Map 評論,挖出服務痛點
你是一位開餐廳的老闆,想了解競爭對手的顧客回饋,看看他們在 Google Map 上有什麼被罵的重點。你可以輸入:
prompt:幫我整理 Google Map 上「餐廳 Y」的評論,包含評論時間、星等、留言重點與負面關鍵字分析。
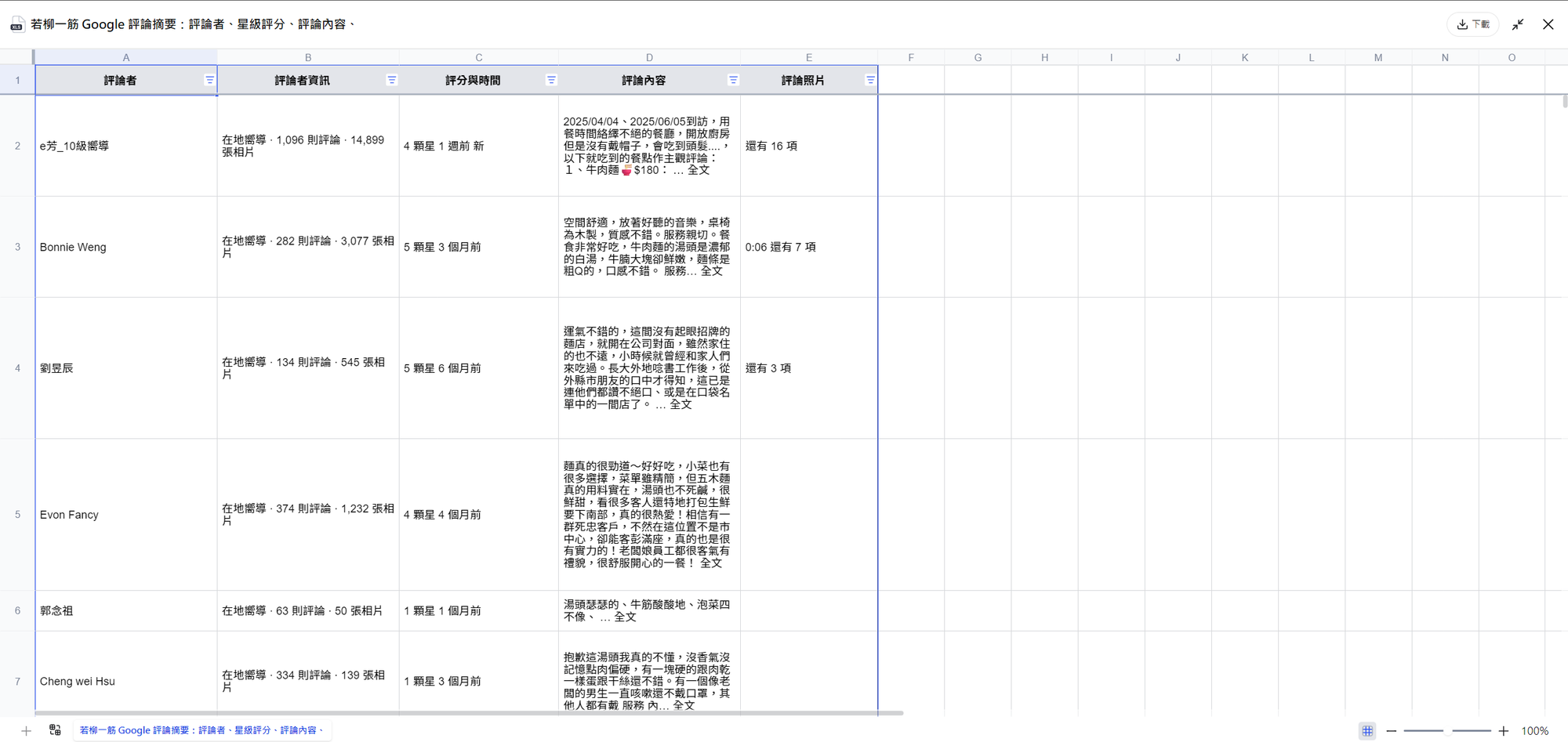
Capalyze 會把所有評論欄位化整理,並標註出常見的負面詞彙(像是「出餐慢」、「態度差」、「價格不合理」),讓你快速掌握顧客最在意的幾個服務問題,也能做為自家改進的參考依據。
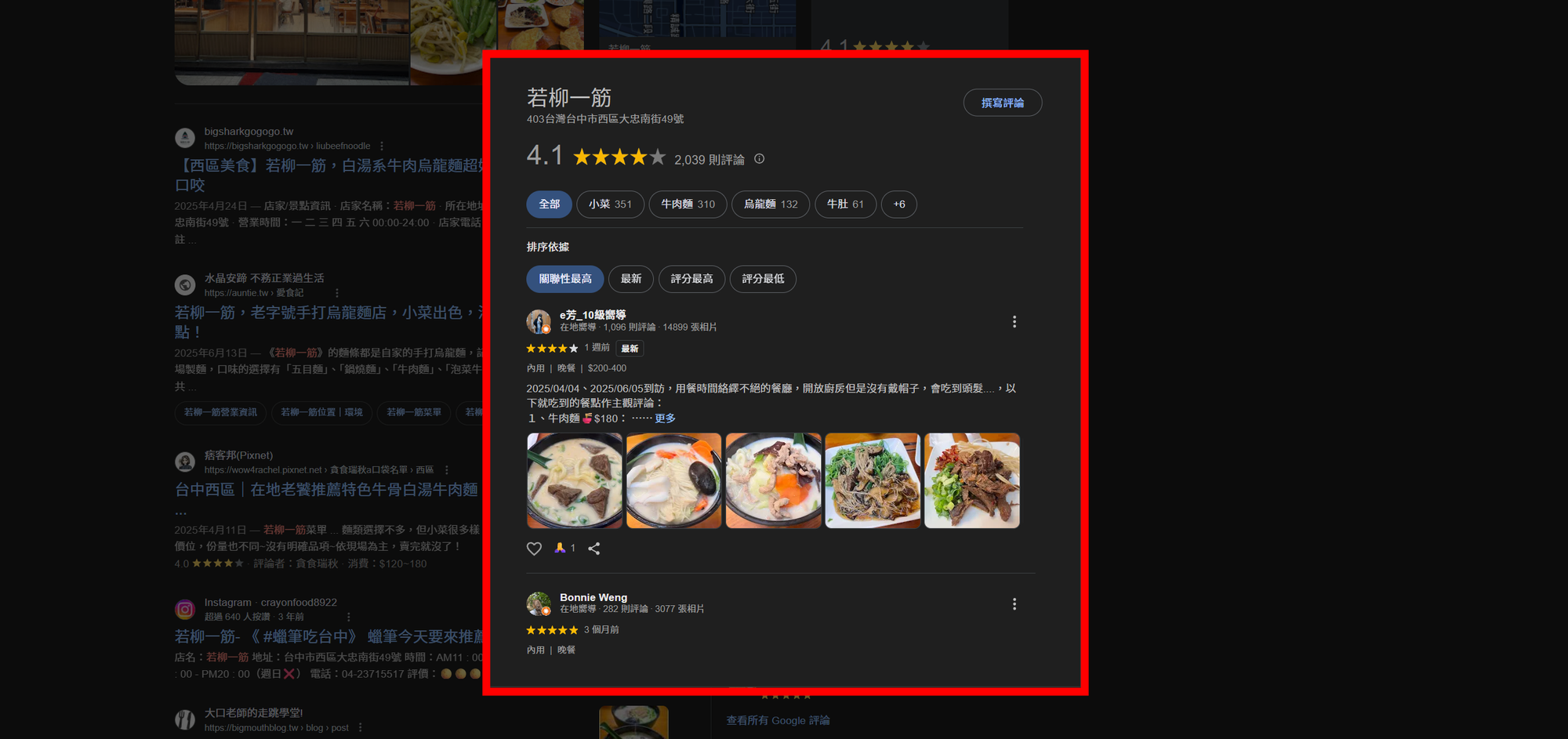
傳統的爬蟲其實很難做到這一點,因為 Google Map 的評論內頁有登入狀態與動態載入限制,爬蟲常常卡住或抓不到完整內容。Capalyze 的特點,就是能跨過這個門檻,直接幫你把評論「拉乾淨」,同時轉成結構化的欄位。
完成後,你可以進一步切換成各種圖表:
- 評分分布的長條圖
- 正負評情緒的比例圓餅圖
- 最常見的「缺點關鍵字雲」
讓你不只知道使用者說了什麼,更能一眼看出競爭對手真正的經營痛點。
延伸應用一|從文字評論中產出 AI 標籤與情緒欄位
除了幫你把資料抓乾淨、轉欄位,Capalyze 還具備資料增生能力,能透過 AI 模型理解評論文字的語意,自動生成新欄位,像是:
- 情緒分類(正向 / 中立 / 負向)
- 評價類型(餐點建議 / 服務抱怨 / 環境問題)
- 回覆建議
prompt (延續 Google map 爬餐廳評論的對話):幫我新增欄位:每一則評論加上情緒分類、評價類型(餐點、服務、環境)、以及幫我產出每一則的回覆建議

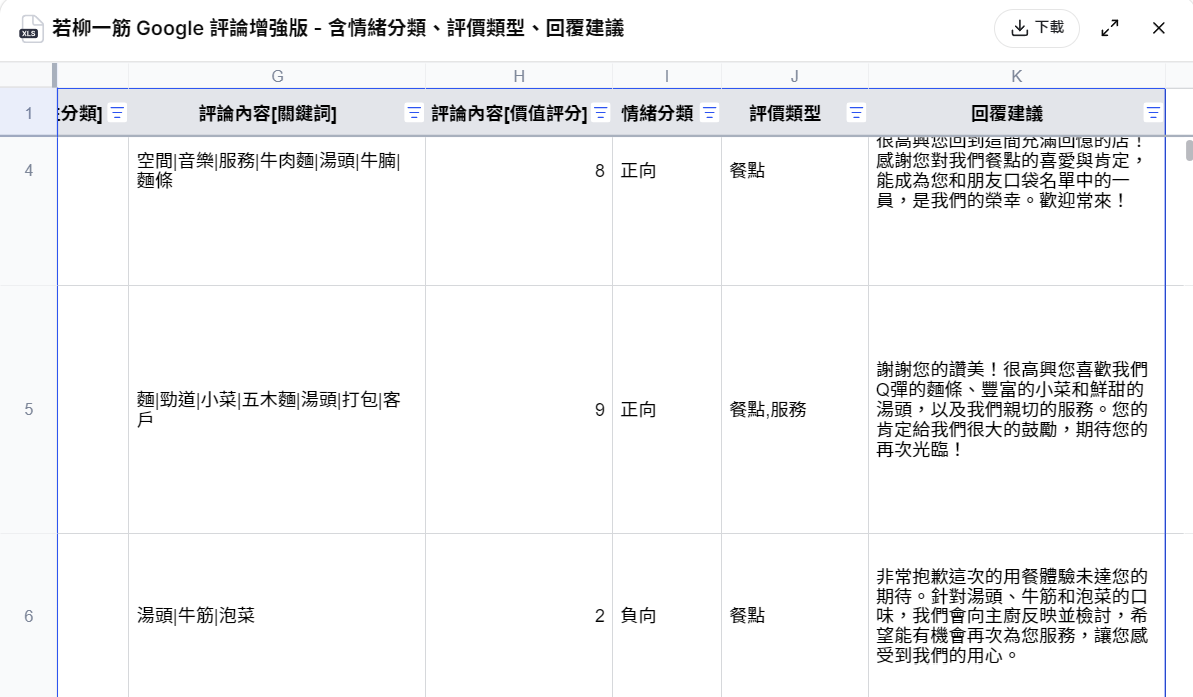
你可以看到 Capalyze 在既有採集的 Google 評論資料上,進一步完成了「結構化關鍵字萃取」、「評論分數與情緒自動分類」、「多面向類型標記(餐點/服務)」,並最終依照情緒與關鍵字,自動生成對應的店家回覆話術,語氣溫暖、貼近品牌風格,不僅節省了人工客服時間,也提升了品牌互動的質感。
延伸應用二|「像人一樣」的網站探索與批量採集
除了分析既有評論資料,Capalyze 也支援「主動下探採集」的功能 —— 讓 AI 像一個助手一樣,幫你一個個點開網站、搜尋頁、貼文內容,自動擷取評論或留言,並整理成結構化的資料表。
以星巴克來說,我可以從 Googlemap 搜尋某區域內的所有星巴克分店,接著讓 Capalyze 自動進入每間分店的 Google Maps,爬取評論與星等資訊,統一輸出成一份「分店聲量總表」。
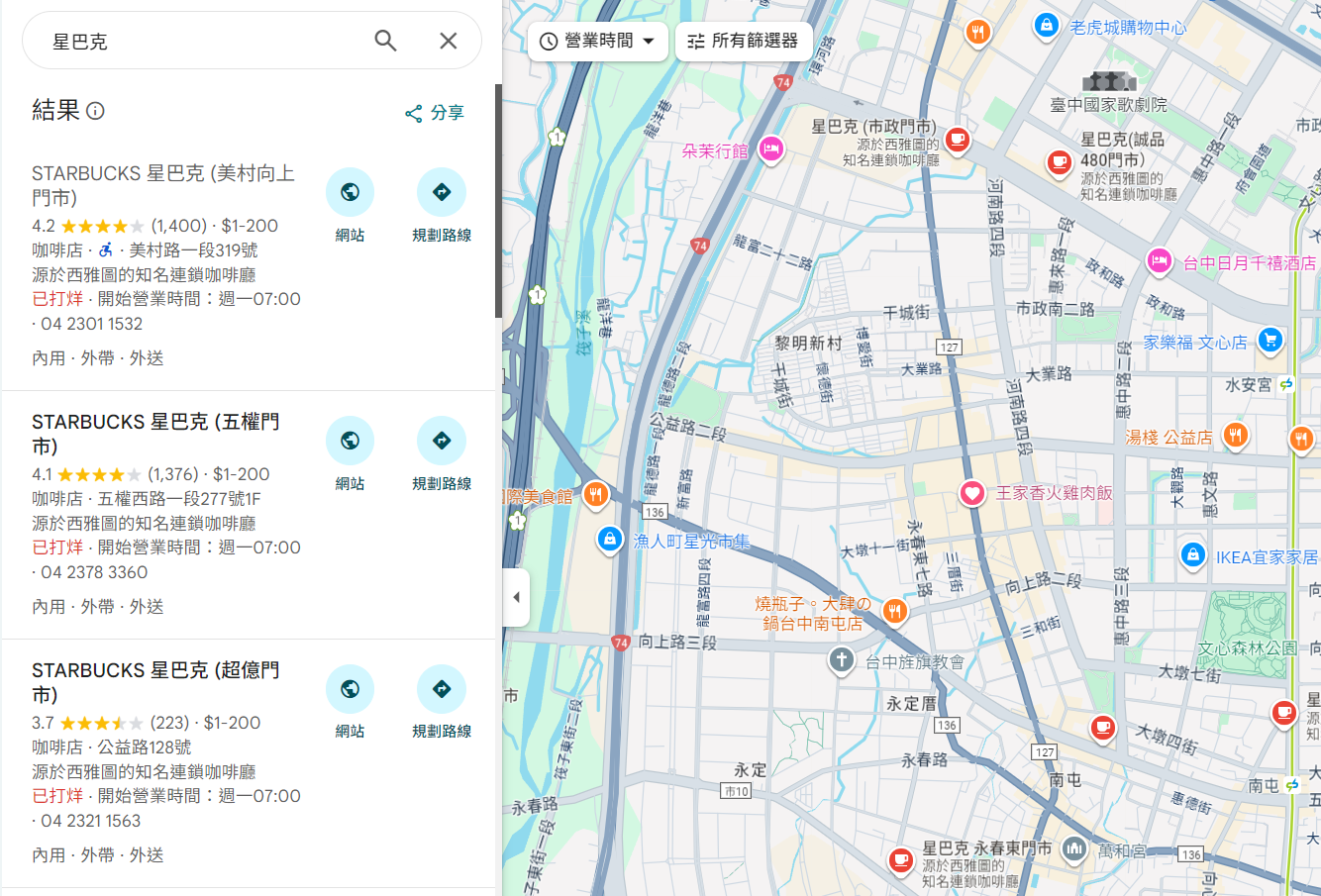
prompt:請幫我採集這個list下所有星巴克的評論
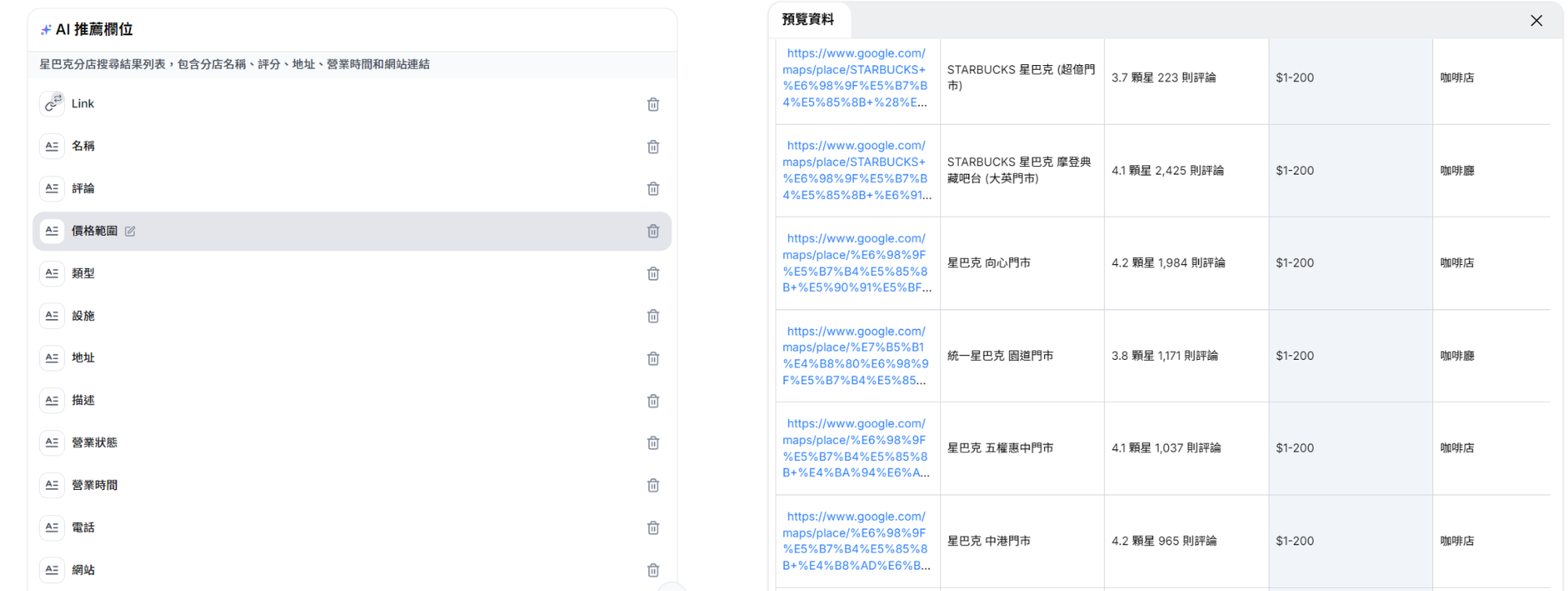
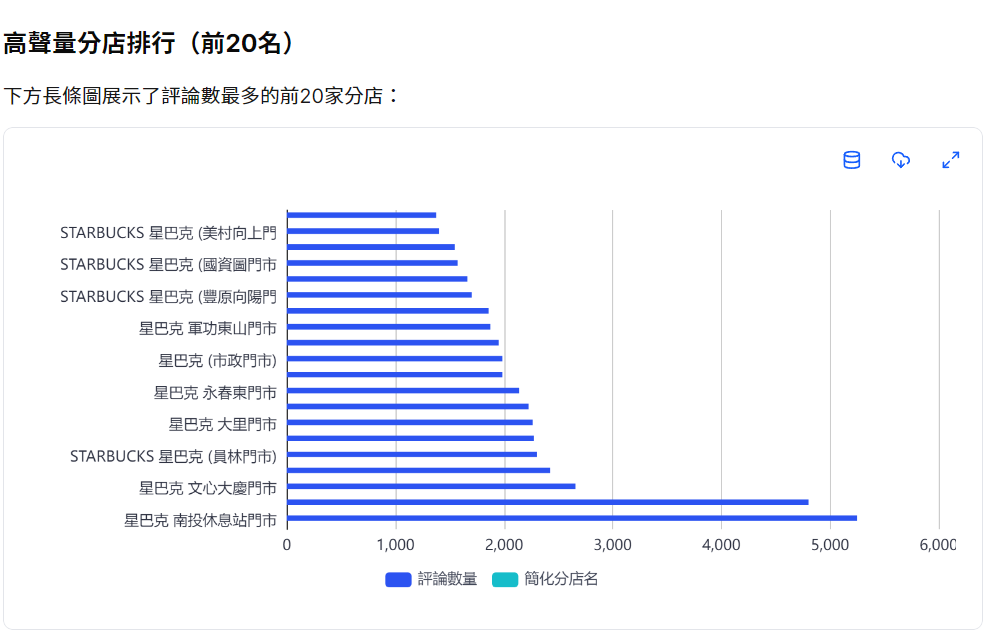
可以看到 Capalyze 不僅幫我採集了各分店的評論,還將這些數據整理成一份高聲量分店排行,這讓品牌經營者可以快速掌握:
- 哪些門市擁有最多評論、聲量最高。
- 哪些地區的門市聲量與評價落差較大(高評論量但分數偏低)
- 哪些門市值得作為 行銷活動首選地點 或 品牌指標據點
這樣的排行資料不僅可以用來做內部評鑑、門市表現追蹤,還能結合進一步的回覆建議、常見抱怨整理、地區熱度分析等模組,真正把評論轉換成行動指標。
資料分析的第一步,Capalyze 幫你打開
無論是 Threads 的品牌輿情、TikTok 的爆款選品,還是 Google Map 的評論洞察,其實都在提醒我們同一件事:資料分析最難的地方,不是分析,而是 能不能抓到乾淨、完整的資料。
過去你可能得自己寫爬蟲、處理 API 限制、面對一堆雜亂無章的格式,常常還沒開始分析,人就先被搞崩潰。 Capalyze 的價值,就是把這道門檻拆掉。
它不是要取代分析師,而是讓更多人都能「像分析師一樣啟動思考」,把策略建立在可追溯的數據基礎上。當資料能被快速收集、結構化,你的每一個決策才真正有機會 Based on Data,而不是憑直覺瞎猜。
🚀 下一步,讓 Capalyze 幫你啟動資料分析
如果你曾經在資料分析的路上卡關,現在就是最佳時機:
- 想定期追蹤品牌聲量、競品評論、區域門市表現?
- 想一次抓下 Threads、TikTok、Google Map 的評論,馬上生成乾淨報表?
👉 立即了解 Capalyze,讓資料為你說話



