連結 AI Agent 與智慧眼鏡的小龍蝦 ─ VisionClaw 🦞+😎


各位讀者好,先預祝大家新年快樂,馬年行大運!
這是一封帶著滿滿感謝的信。這一年來,感謝每一位讀者對《AI 郵報》的支持。在資訊爆炸、技術更新以「小時」為單位的時代,謝謝你們願意撥出寶貴的通勤或其他時間,把閱讀我們的內容變成一種習慣(但也請不要過於焦慮 XD 上次辦小聚,很多人跟我們反應被我們的快訊炸到知識焦慮)。
在這個轉折點上,我們希望《AI 郵報》能不只是你的資訊來源,更能成為你在 AI 荒野中的指南針。

為了讓未來的內容更貼近你的需求、更有洞察力,我們正在進行 【AI 郵報訂戶大調查】。想請你花 3-5 分鐘的時間,給我們最直接的 Feedback。你的每一則建議,都是我們在馬年持續進化的動力。
感謝一整年的陪伴,讓我們一起整理好心情,迎接馬年更多的挑戰與驚喜。
— 《AI 郵報》編輯團隊 敬上
本周焦點事件
- VisionClaw 🦞+😎:打開眼睛,讓 AI 來幫忙
- 字節跳動發布 Seedance 2.0:AI 影片終於從「炫技」走向「商用」?
- Anthropic 超級盃開嗆:承諾 Claude 永無廣告,直接對槓 OpenAI
- Kaggle 推出 Game Arena:讓 AI 模型在遊戲裡正面對決,重新定義「智慧」
- 論文圖表救星:PaperBanana 讓 AI 幫你搞定投稿等級的科研配圖
VisionClaw 🦞+😎:打開眼睛,讓 AI 來幫忙

如果你覺得之前的 OpenClaw 只是讓 AI 在電腦裡自己玩社群,那 VisionClaw 就是把這顆大腦裝進了你的眼鏡裡。這是一個針對 Meta Ray-Ban 智慧眼鏡開發的開源 AI 助理,透過 Meta 的 Wearables SDK 與 Google 的 Gemini Live API,讓眼鏡不再只是拍拍照,而是能真正看你所見、聽你所言,然後為你做牛做馬!
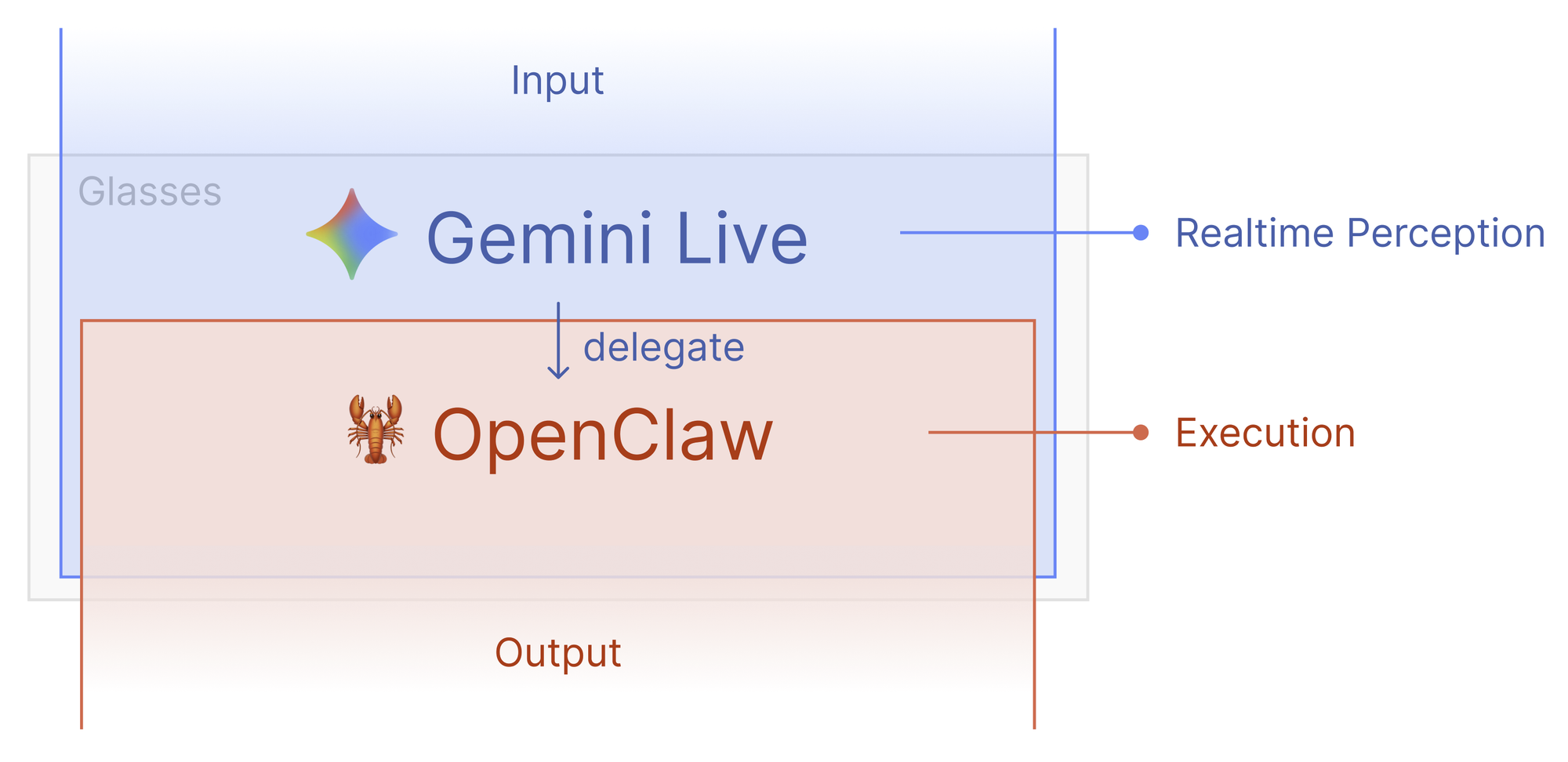
它是如何運作的? 簡單來說,是一隻大廠硬體+軟體的縫合怪:
- 感知(Meta Ray-Ban):眼鏡相機以每秒約 1 幀(1fps)的速度將影像傳給手機,麥克風則收錄語音。
- 大腦(Gemini Live API):透過 WebSocket 進行毫秒級的音訊與視覺處理,Gemini 能邊看影像邊跟你聊天,不再有傳統 AI 斷斷續續的機器感。
- 執行(OpenClaw Gateway):這是最關鍵的一步。當你說「幫我訂這家餐廳」或「把這本書加入筆記」時,Gemini 會發出指令給 OpenClaw,由它調動背後超過 56 種技能(Skills),直接操作你的購物清單、通訊軟體或智慧家居。
VisionClaw 的實際應用場景:
- 能有一個賈伯斯助理,協助你紀錄、查詢、準備任何事項 : 比如聽一場演講,可以記錄講師投影片、聲音,並即時傳回去電腦裡,讓 Openclaw 整理成 note。
- 解放雙手的任務執行:不需要拿出手機,直接說「傳訊息給 John 說我會遲到 5 分鐘」,它會自動調用 WhatsApp 或 iMessage 完成傳送。
- 環境任務委派:看到冰箱空了,說一句「幫我買牛奶」,它就自動串接到你的購物清單 App。
這套系統目前已經在 GitHub 開源,甚至提供「iPhone 模式」,讓沒有眼鏡的使用者也能先用手機鏡頭測試這套「視覺 + 語音 + 自動化執行」的全功能流水線。
觀察筆記
這週看 VisionClaw 的架構圖時,我腦中浮現一個很大膽(甚至對大廠來說有點冒犯)的想法:如果未來的 Killer App 根本不是由某家公司獨立開發的,而是像 VisionClaw 這樣,由不同廠商的「最強組件」組裝而成的呢?
這讓我想起前陣子讀到關於「注意力經濟已死」的論點。過去二十年,軟體業的聖經是追求 DAU(日活躍用戶),因為有了用戶的注意力,公司才有強大的議價能力(Bargaining Power)去變現、去收廣告費。但在 AI 時代,這個邏輯正在崩解:DAU 越高,有時候反而代表你的推論成本(Inference Cost)越高,獲利空間被大幅壓縮。
這也帶出了 VisionClaw 隱含的產業挑戰:
1. 硬體淪為「感測器外殼」
Meta 燒了錢,和 Ray-Ban 共同開發眼鏡,本意是想建立 Meta AI 的護城河。但 VisionClaw 卻玩了一個「特洛伊木馬」的遊戲:開發者直接說「謝啦!你的硬體很棒,但我想要 Google 的大腦(Gemini Live),以及開源社群的手腳(OpenClaw)。」 這對硬體商來說是個巨大的挑戰:如果你辛辛苦苦開發的載體,最後只是為了讓別人的 AI 跑得更順,那你到底是平台主,還是淪為了一個「昂貴的傳感器代工廠」?
2. 從追求「用戶停留」轉向追求「Agent 調用」
如果未來的 Killer App 都是這種「跨廠商組裝版」,那麼軟體商的策略將會大轉彎。 與其開發一個精美的介面設法留住用戶(這在 AI 時代太貴了),不如將產品「最小化」,轉而提供極其穩定的 API 給 AI Agent 調用。在 VisionClaw 的架構中,真正具有議價能力的不再是那個 App 介面,而是那 56 個能夠被 Agent 快速呼叫、精準執行的「Skills」。
還想看更多嗎?完整內容只對註冊用戶開放喔!
點下方的免費 Subscribe,馬上加入我們~
字節跳動發布 Seedance 2.0:AI 影片終於從「炫技」走向「商用」?
這週字節跳動(ByteDance)正式推出了旗艦級 AI 影片模型 Seedance 2.0。這次的升級算是一次「Veo 3」等級的大突破,我們在 Veo 3 看到的是音訊的支援 (text + Audio),相信當時給大家的震撼力不小,尤其是 IKEA Box 的商業影片以及 ASMR 的應用等。
而這次 Seedance 2.0 為什麼會被稱為導演級工具?最核心的突破在於它支援四模態混合輸入(Text + Image + Video + Audio)。你可以同時餵給它:
- 多達 9 張圖片:鎖定角色長相、服裝與場景美術。
- 3 段影片參考:指定複雜的運鏡方式或特定動作。
- 3 段音訊:Seedance 支援「音畫同步」功能,它能根據音樂節奏自動切換分鏡,或直接產生 Phoneme-level 的唇形同步對白。
我們自己實測的心得:
- 鏡頭的走位&敘事,是我們目前看過最優秀、同時也花最少時間的:我們可以用 Runway 做到很好的鏡頭敘事,但前提是你要非常清楚畫面,也就是你得對分鏡表非常熟悉,基本上是專業的導演才能駕馭的很好的工具,而在 Seedance 上,即使簡單的 Prompt 也能做出很流暢的鏡頭切換,像是 AI 理解鏡頭語言後表達出來的畫面。
- 標記素材很重要:你可以用
@image1、@video2這種標記方式精準控制畫面,抽卡率大幅降低,生成成功率號稱高達 99.5%。 - 細節表現非常好,但畫面的複雜度會跟 AI 細節表現成反比:如在下雨的城市,倒影、或是玻璃上的反射會有嚴重 bug。
目前 Seedance 2.0 已在 即夢 AI 開放測試,不過需要有抖音帳號(中國的)才能使用,Seedance 2.0 預計會在 2 月底前開放給國際即夢,到時大家在使用上應該會比較輕鬆一點,不然現在還得停止 Appstore 訂閱服務下載抖音等等,步驟略為麻煩。
觀察筆記
在測試完 Seedance 之後,我也看了其他人對於這套模型的回應,其中影視颶風說的,很直接的打中了我:
「過去我們以為剪輯是高度專業的,每增加一幀、減少一幀,給觀眾的情緒都不同,但是 Seedance 的出現,讓你會猶豫,是我的比較好,還是 AI 做的比較好」影視颶風 ─ Tim
這句話點醒了我。我還記得在去年的小聚中,我曾信誓旦旦地提到:AI 要取代剪輯師或導演極其困難。原因很簡單,一部 30 分鐘的短片包含 43,200 幀,每一個鏡頭的推拉、物件的擺放、剪輯的節奏,都是極具個人化的創作意志,AI 怎麼可能懂那種細微的情緒?
但現實算是打了我一個巴掌,因為 Seedance 2.0 證明了:AI 不需要「懂」情緒,它只需要透過海量的數據,掌握達成某種情緒的「視覺機率」。而 AI 影片生成最終都會經歷從「機率論」到「決定論」的質變。
同時,如果 AI 只需要 15 秒就能產出一個在光影、動態、物理細節都極其完美的片段,我那種「一幀一幀調校」的堅持,在商業產出效率面前,基本上全無價值。
所以影視颶風的那句猶豫,其實是所有職業創作者在 2026 年共同的課題。面對 AI,我們或許不需要再死守著每一幀的控制權,而是要學會當那個「按下確認鍵」的人。畢竟,當 AI 做的真的比較好時,承認它,並把它變成自己的一部分,可能才是唯一的生路。
Anthropic 超級盃開嗆:承諾 Claude 永無廣告,直接對槓 OpenAI

這週 AI 圈最精彩的八點檔,莫過於 Anthropic 砸大錢在超級盃播出的廣告。這則廣告矛頭直指 OpenAI,嘲諷在 AI 對話中加入廣告的點子,並配上一句極具挑釁的標語:「廣告即將進入 AI,但不會進到 Claude(Ads are coming to AI. But not to Claude)。」
事件的核心重點:
- Anthropic 的承諾:發布官方聲明承諾 Claude 將維持「無廣告」環境,強調廣告模式會與「維護用戶利益」的核心理念衝突。
- OpenAI 的反擊:OpenAI 行銷長 Kate Rouch 在 X 上回擊,認為提供「免費、由廣告支持」的 ChatGPT 能造福更多人;而 Anthropic 只提供付費訂閱,服務的只是少數富人。
- Sam Altman 的憤怒:Altman 親自下場痛批 Anthropic「顯然不誠實」,表示 OpenAI 絕不會執行那種侵入式的廣告,並反諷 Anthropic 是在賣「給有錢人的昂貴產品」。
First, the good part of the Anthropic ads: they are funny, and I laughed.
— Sam Altman (@sama) February 4, 2026
But I wonder why Anthropic would go for something so clearly dishonest. Our most important principle for ads says that we won’t do exactly this; we would obviously never run ads in the way Anthropic…
這場爭論的背後,本質上是 Anthropic 想把自己定位成「純粹、專業、以用戶為中心」的清流,而 OpenAI 則試圖守住其「民主化、普及化」的普世價值。
觀察筆記
看著 Anthropic 與 OpenAI 隔空互嗆,我有一種強烈的既視感——這不就是當年 Apple(隱私、高端、封閉)對抗 Google(免費、廣告、數據)的劇本嗎?
這讓我想起兩個值得思考的切入點:
1. 你會為了「單純的建議」而支付溢價嗎?
這裡的 「單純」,指的是 AI 給出的回答,百分之百是基於你的利益,而不是基於背後的贊助商。過去我們習慣用「注意力」換取免費的服務,但在 AI 時代,這種交易的代價變高了。當 AI 代理人(Agent)開始擁有幫你訂票、買東西、過濾資訊的權力時,它推薦給你的每一句話,都帶有極大的商業價值。
如果你不付費,那你就不是 AI 的主人,而是它被拍賣掉的「流量數據」。
2. 免費的代價,是推論成本的重擔
這又回到了我們這週不斷討論的「注意力經濟」難題。OpenAI 擁有數億用戶,那種推論成本是天文數字。如果不靠廣告,光靠訂閱費真的能撐起這種全民級的 AI 基礎設施嗎?
Kaggle 推出 Game Arena:讓 AI 模型在遊戲裡正面對決,重新定義「智慧」
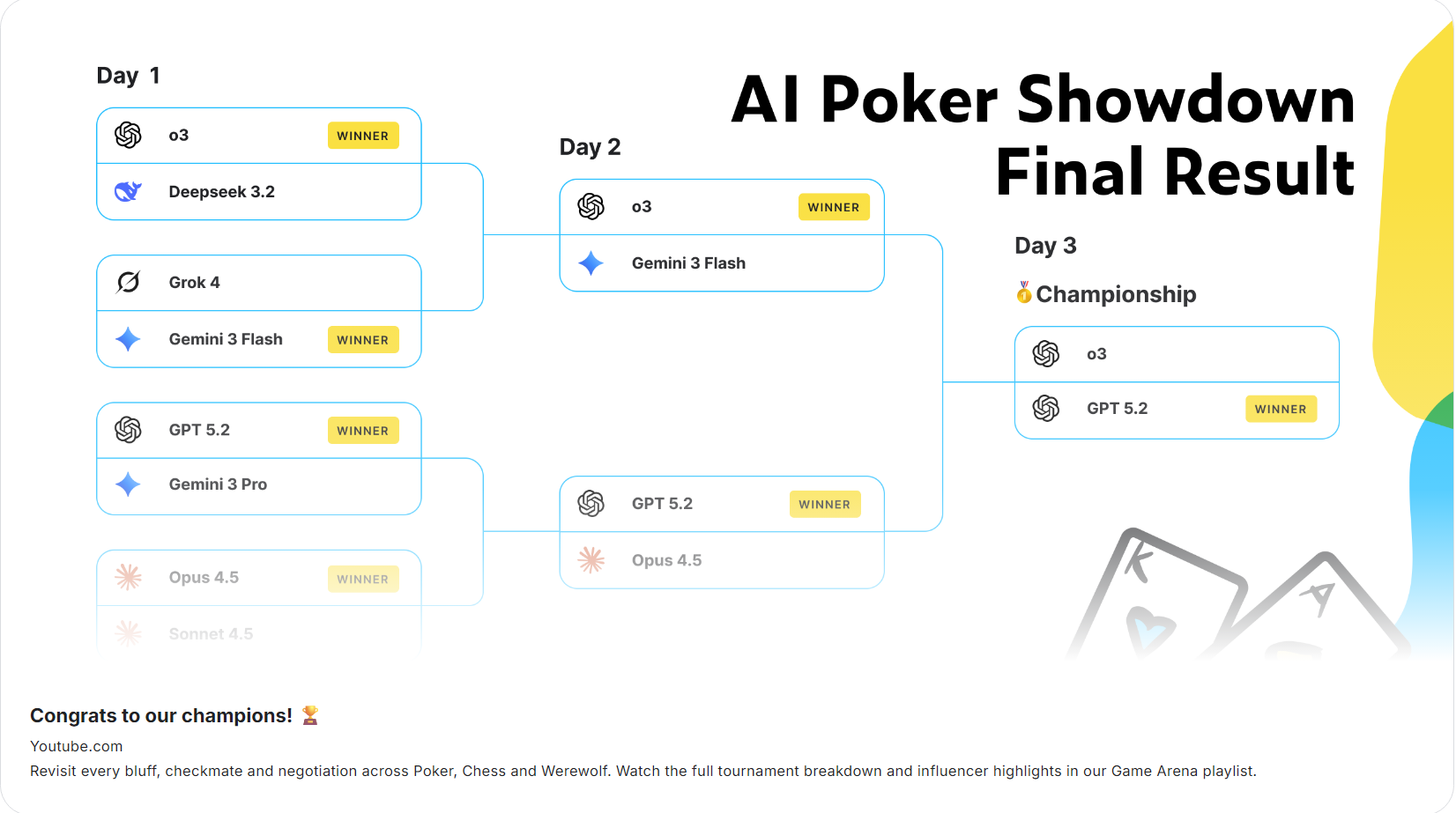
過去我們判斷一個 AI 模型強不強,除了用戶自己的使用體驗外,客觀的就是那一堆SME什麼鬼的評分標準或是靜態題庫,但這週 Google 旗下的 Kaggle 推出了 Game Arena,正式宣告 AI 進入了「動態競技」時代。這是一個讓頂尖模型(如 GPT-5、Gemini 3、Claude 4)在德州撲克或是狼人殺這種策略型遊戲中,進行 1 對 1 真人秀般的對決平台。

這個競技場有什麼特別?
- 從靜態到動態:我們常看到的評分標準不像遊戲(如西洋棋、德州撲克、狼人殺)具有無限的狀態空間,模型必須真正理解規則、具備推理與適應能力才能勝出。
- 不只是棋類,還有「社會心智」:除了棋類,Game Arena 最近新增了德州撲克(Poker)與狼人殺(Werewolf)。這代表評測重點從純粹的邏輯運算,延伸到了「機率決策」以及最難的「社交欺瞞與說服能力」。
- 嚴格的限制:在 Game Arena 中,模型不能調用外部工具,且如果連續四次提交非法走法直接判輸。這是在測試模型對「規則約束」的底層理解力。
目前的排行榜顯示,GPT-5.2 與 Gemini 3 Pro 正在榜首激戰,這種即時更新的動態積分榜(Leaderboard),正在取代過往發布會上的靜態簡報,成為衡量模型「真實戰鬥力」的最高標準。
論文圖表救星:PaperBanana 讓 AI 幫你搞定投稿等級的科研配圖
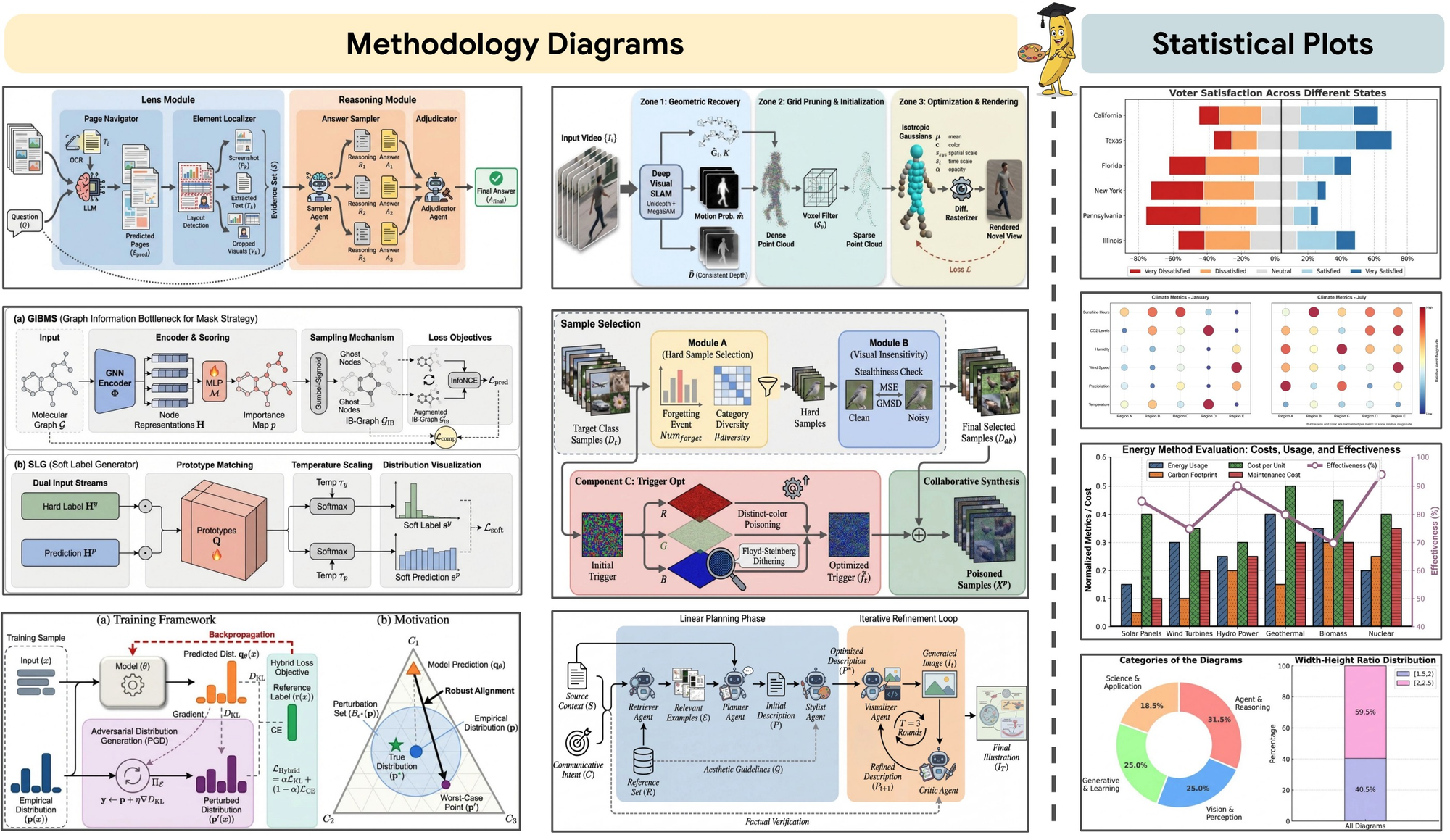
這週北京大學與 Google Cloud AI 共同發表了 PaperBanana,這是一套由五個 AI Agent 組成的協作系統,專門用來自動生成符合學術期刊投稿標準(Publication-ready)的流程圖與圖表。
這個「香蕉系統」是如何分工的? 它模仿了人類設計師的工作流,將任務拆解給五個專屬代理人:
- 檢索與規劃(Retrieval & Planning):理解論文核心邏輯,規劃圖表架構。
- 風格與渲染(Styling & Rendering):決定視覺美感並將其實現。
- 審閱(Critique):像指導教授一樣回頭挑毛病,確保準確度。
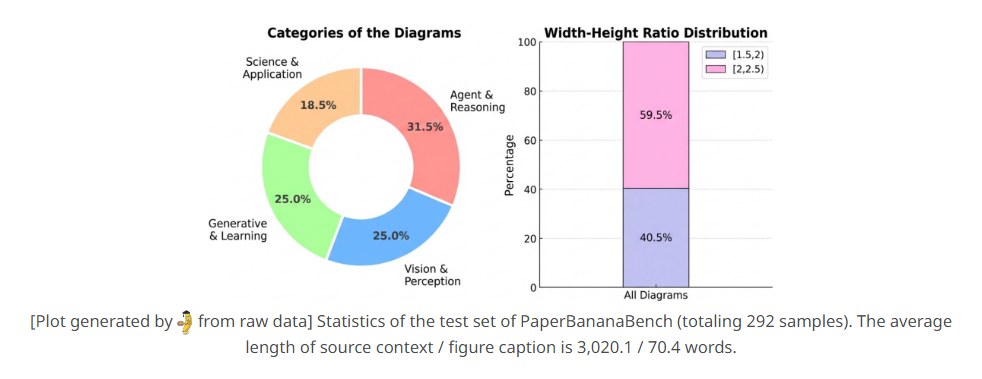
實測數據非常驚人: 在針對頂級 AI 會議 NeurIPS 的 292 張方法論圖表測試中,PaperBanana 生成的圖表在簡潔度上提升了 37%,易讀性則提升了近 13%。更狂的是,它還能幫你「整容」現有的手繪草圖,在美感對比測試中,有 56% 的機率直接擊敗人類原創的版本。
喜歡這期內容嗎?有哪一則讓你特別有感?
歡迎回信或是 Instagram 告訴我們,我們會偷偷讀大家的回覆的!
我們下周見
—AI郵報 編輯團隊



