Meta發布SAM 3與SAM 3D:AI視覺理解跨入文字提示與3D重建新時代
Meta在2025年11月19日正式發布新一代影像分割模型Segment Anything Model 3(SAM 3)與3D重建模型SAM 3D,為電腦視覺領域帶來革命性突破。這兩款全新AI模型不僅延續了SAM系列在影像分割領域的領先地位,更首次實現了自然語言文字提示分割功能,並能從單張2D影像重建完整的3D物件與場景,將AI視覺理解能力推向全新維度。


Meta同步推出Segment Anything Playground互動平台,讓開發者與創作者能直接在瀏覽器中體驗這些前沿技術。SAM 3的模型權重、研究論文與微調程式碼已全面開源,而SAM 3D則釋出模型檢查點與推論程式碼供研究社群使用。
SAM 3核心技術突破:從視覺提示到概念分割
開放詞彙文字提示功能
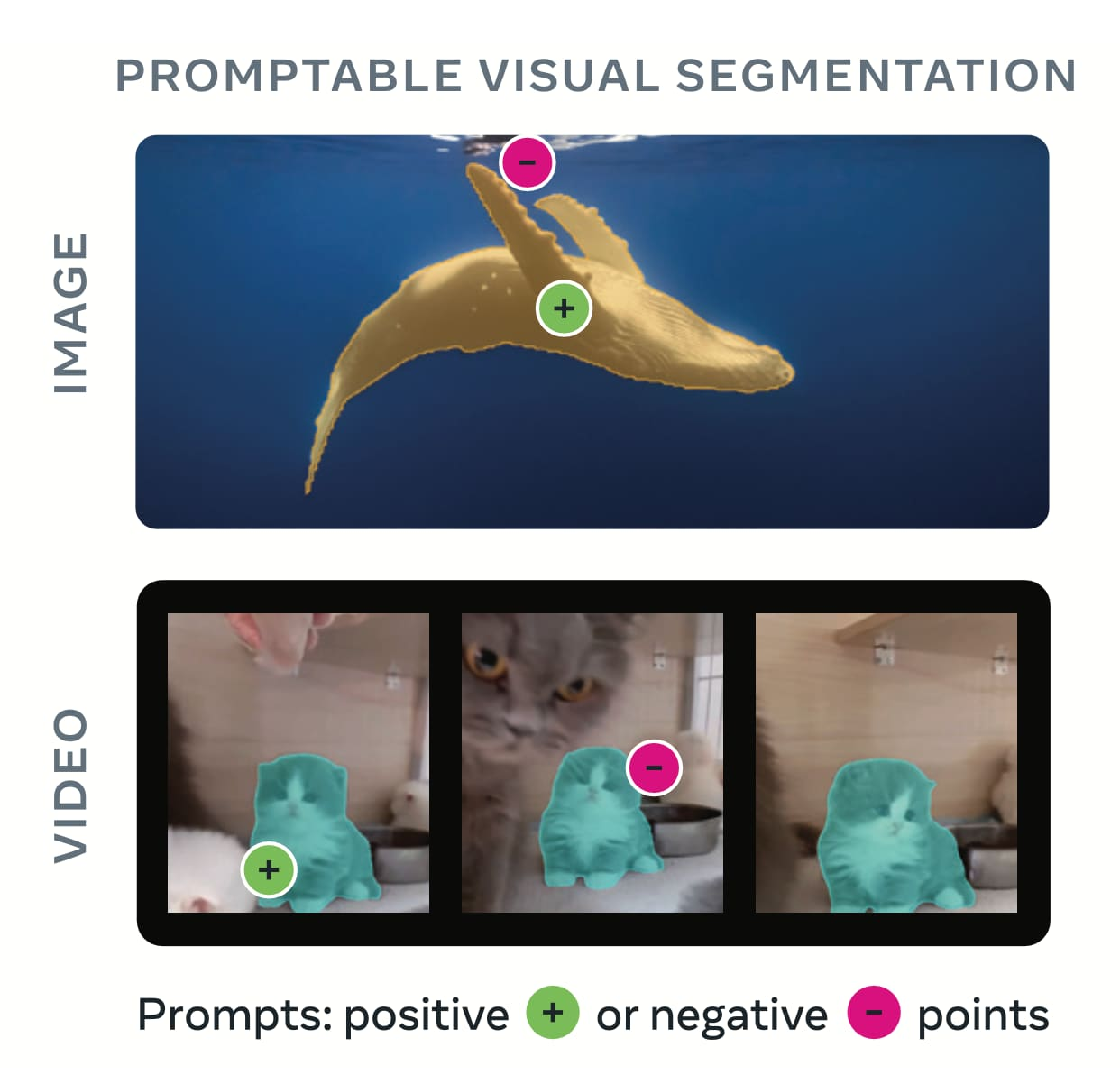
SAM 3最重大的創新在於引入「可提示概念分割」(Promptable Concept Segmentation, PCS)能力,徹底改變了物件分割的互動方式。傳統的SAM 1和SAM 2僅支援點擊、框選等視覺提示,而SAM 3突破性地支援自然語言文字描述,使用者只需輸入如「黃色校車」、「條紋紅色雨傘」等詞彙,系統就能自動識別並分割影像或影片中所有符合條件的物件。
這項技術解決了AI模型長期以來難以將語言與特定視覺元素精確連結的痛點。以往的模型通常只能處理「公車」或「汽車」等固定標籤集合的簡單概念,但SAM 3可以理解更複雜、更細緻的描述,甚至能與多模態大型語言模型結合,處理如「坐著但沒戴紅色棒球帽的人」這類複合條件查詢。
統一的檢測、分割與追蹤架構
SAM 3採用雙編碼器-解碼器Transformer架構,整合了DETR風格的檢測器與SAM 2啟發的追蹤器,兩者共享統一的感知編碼器(Perception Encoder)。這種設計使得SAM 3能在單一模型中同時完成物件檢測、精確分割與跨影格追蹤三大任務。
模型包含約8.48億個參數,能在NVIDIA H200 GPU上以每張影像約30毫秒的速度處理超過100個物件,在包含五個並發目標的影片場景中也能維持接近即時的效能。
雙重提示模式支援
SAM 3不僅支援全新的文字提示(PCS模式),也完全相容SAM 2的視覺提示功能(PVS模式),包括正負點擊、邊界框與遮罩等互動方式。使用者還可以透過影像範例作為提示,讓模型找出所有相似的物件實例,實現更靈活的混合式互動工作流程。
SAM 3性能表現:大幅超越既有基準
零樣本分割準確率創新高
在LVIS零樣本實例分割任務中,SAM 3達到47.0的平均精確度(AP),相較於先前最佳成績38.5提升了22%。在Meta自建的SA-Co基準測試中,SAM 3的概念分割效能更是現有系統的兩倍。
用戶偏好測試結果顯示,SAM 3的輸出品質約為最強基準模型OWLv2的三倍,並且在與Gemini 2.5 Pro等基礎模型的比較中也展現優勢。在影片物件分割任務中,SAM 3在MOSEv2基準上達到60.1的J&F分數,相較SAM 2.1的47.9提升了25.5%。
接近人類水準的標註品質
在具備三重人工標註的SA-Co/Gold基準測試中,SAM 3達到65.0的CGF1分數,相當於人類最保守標註者下界(74.2)的88%,展現出極高的標註可靠性。
創新數據引擎:人機協作加速標註效率
SAM 3的卓越表現來自於Meta開發的創新數據引擎,這套系統結合了人工標註者、SAM 3模型本身與基於Llama 3.2v的AI標註助手,實現了前所未有的標註規模與速度。
AI驅動的標註流程
AI標註者能提出多樣化的名詞片語(包括困難的負面範例),而AI驗證器則負責確認遮罩品質與標註的完整性,其表現接近人類水準。主動挖掘機制將人力集中在AI難以處理的挑戰性案例上,並透過以Wikidata為基礎的大型本體論確保概念覆蓋的廣度。
這套數據引擎使得負提示標註速度比純人工快約5倍,正提示標註速度提升約36%,最終創建了包含超過400萬個獨特概念的大規模訓練集。訓練與基準測試數據集SA-Co涵蓋214,000個獨特概念,橫跨126,000張影像與影片,概念數量是現有基準(如LVIS的約4,000個概念)的50倍以上。
SAM 3D:從2D影像到3D世界的完整重建
雙模型架構滿足不同需求
Meta同步推出的SAM 3D包含兩個專門化模型:SAM 3D Objects用於物件與場景重建,SAM 3D Body則專注於人體姿態與形狀估計。
SAM 3D Objects能從單張自然影像重建出包含詳細3D形狀、紋理與物件布局的完整場景。該模型在頭對頭人類偏好測試中,勝率達到至少5比1,大幅超越現有方法。系統不僅能處理被遮擋的物件,還能推斷出合理的背面幾何結構,展現強大的場景理解能力。
Today we’re excited to unveil a new generation of Segment Anything Models:
— AI at Meta (@AIatMeta) November 19, 2025
1️⃣ SAM 3 enables detecting, segmenting and tracking of objects across images and videos, now with short text phrases and exemplar prompts.
🔗 Learn more about SAM 3: https://t.co/tIwymSSD89
2️⃣ SAM 3D… pic.twitter.com/kSQuEmwH33
SAM 3D Body採用全新的Momentum Human Rig(MHR)參數化網格表示法,將骨骼結構與表面形狀解耦,提升了準確度與可解釋性。模型支援身體、腳部與手部的完整姿態估計,即使在複雜多人場景中也能維持高精確度。訓練數據涵蓋約800萬張高品質影像,包含罕見姿勢與多樣化服裝,確保模型在真實世界條件下的泛化能力。
大規模3D標註資料集
SAM 3D Objects的訓練基於創新的數據標註引擎,該引擎結合3D設計與多階段訓練方案,成功標註了近100萬張不同影像,生成約314萬個網格模型。Meta也將釋出SAM 3D Artist Objects評估資料集,這是首個由藝術家協作建立、配對影像與物件網格的基準,為3D重建研究設立了新標準。
實際應用場景:從創作工具到科學研究
整合至Meta產品生態
SAM 3與SAM 3D的技術突破將直接賦能Meta旗下多款產品。Instagram的影片創作應用Edits即將推出由SAM 3驅動的特效功能,讓創作者能將特定效果精準套用在影片中的特定人物或物件上。Meta AI應用程式的Vibes功能也將整合SAM 3,提供更進階的視覺編輯體驗。
Facebook Marketplace的「View in Room」購物功能將運用SAM 3D技術,讓消費者能在購買前將商品的3D模型投放到自家環境中預覽。
科研與生態保育應用
SAM 3已應用於多個科學研究領域。Meta與Conservation X Labs及Osa Conservation合作建立的SA-FARI資料集,包含超過1萬個相機陷阱影片,標註了100多種物種,為野生動物保育提供強大的AI分析工具。
FathomNet專案則為水下影像分割提供基準與遮罩數據,協助海洋生物研究。此外,SAM 3與Roboflow的合作讓使用者能微調、標註並部署模型以滿足特定需求,擴展了AI在各垂直領域的應用可能性。
AR/VR與遊戲開發
SAM 3D在擴增實境(AR)、虛擬實境(VR)與遊戲資產創建方面具有巨大潛力。開發者能快速從照片生成高品質3D模型,大幅降低3D內容製作的時間與成本門檻。開源的模型檢查點與推論程式碼也鼓勵社群進行創新與商業應用。
技術演進脈絡:從SAM到SAM 3的躍進
SAM系列自2023年4月推出首代模型以來,持續引領影像分割技術發展。SAM 1奠定了可提示分割的基礎,配合包含數百萬影像與11億個遮罩的SA-1B資料集,開創了零樣本影像分割的新典範。
SAM 2在2024年將能力延伸至影片領域,引入記憶注意力機制與跨影格傳播技術,實現了即時的影片物件追蹤。SAM 3則在此基礎上整合了文字提示功能,並將分割任務從「每次提示一個物件」進化為「找出所有符合概念的實例」,加上內建的開放詞彙檢測器,使其成為真正的概念層級視覺基礎模型。
開源策略與社群生態
Meta採取積極的開源策略推動SAM 3與SAM 3D的發展。SAM 3在SAM授權條款下釋出,允許研究與商業使用。開發者可透過GitHub取得完整的模型權重、訓練程式碼與微調工具。
SAM 3D Objects與SAM 3D Body的模型檢查點與推論程式碼也已在GitHub上發布,並提供詳細的安裝與使用文件。Segment Anything Playground提供無需技術背景的互動式體驗環境,降低了技術採用門檻。
Hugging Face平台上也已提供SAM 3與SAM 3D的模型權重,方便研究人員與開發者快速整合。Roboflow等第三方平台的整合則進一步擴大了SAM 3的應用生態,支援標註、微調與邊緣部署等完整工作流程。
技術挑戰與未來展望
儘管SAM 3與SAM 3D展現了卓越的性能,但仍存在一些局限性。SAM 3在細粒度專業概念與多目標複雜影片追蹤場景中還有改進空間。模型參數規模達8.48億,需要高階GPU才能達到最佳效能,在邊緣裝置上的部署仍具挑戰。
對於需要即時應用的場景,開發者可利用SAM 3標註資料後,訓練更小型、更快速的監督式偵測模型,雖然會失去文字提示能力,但能滿足特定物件的即時檢測需求。
未來發展方向包括進一步縮小模型尺寸、提升推論速度、擴展支援的概念類別,以及加強在極端環境與邊緣案例下的穩健性。Meta也持續與學術界、產業夥伴合作,推動SAM技術在醫療影像、自動駕駛、機器人等領域的創新應用。
結論
Meta發布的SAM 3與SAM 3D代表了電腦視覺與3D理解領域的重大里程碑。SAM 3透過整合自然語言文字提示,將影像分割從幾何工具提升為概念層級的視覺基礎模型,在零樣本分割任務中達到業界領先水準。SAM 3D則突破了從單張影像進行3D重建的技術瓶頸,為AR/VR、遊戲開發與科學研究開啟全新可能性。
創新的人機協作數據引擎、大規模的訓練資料集,以及積極的開源策略,共同構築了SAM生態系統的競爭優勢。隨著這些技術逐步整合至Instagram、Facebook等數億用戶使用的平台,以及在科研、生態保育等領域的深度應用,SAM 3與SAM 3D正在將先進的AI視覺理解能力從實驗室帶入真實世界,改變人們與視覺內容互動的方式。


![[AI郵報新年特輯] 2025 - 26 Top 5 AI 工具 & 大事件回顧](/content/images/size/w600/2026/02/image-33-1.png)
