Mistral AI 推出 Voxtral TTS!跟 ElevenLabs 正面對決
Mistral AI 推出 Voxtral TTS,是他們最新一代文字轉語音模型,專為高品質、自然流暢的語音合成設計。在語調、情感與節奏上更接近真人,支援多語言與多說話者,適合即時對話與長文本應用。


Mistral AI 發布 Voxtral TTS,這是該公司首款專注於文字轉語音(Text-to-Speech)的生成式 AI 模型,在語調、情感與節奏上更接近真人,支援多語言與多說話者,適合即時對話與長文本應用。聲音不只是結果,而是變成模型的一部分。
Voxtral TTS
Mistral 正式推出了 Voxtral TTS,這是他們第一款文字轉語音模型,主打多語言語音生成,參數量 40 億,設計目標是輕量、低延遲、可規模化部署。
40 億參數是重點——它不是要跑在超級電腦上的怪物,而是一個在企業實際部署環境中能真正跑起來的工具。
Voxtral TTS 支援 9 種語言:英文、法文、德文、西班牙文、荷蘭文、葡萄牙文、義大利文、印地文和阿拉伯文,同時支援多種方言。API 定價是每千字元 0.016 美元。
自然感
取樣率、參數量、支援語言數量都是可以從規格表上看出來,但用戶真正在意的是完全無法量化的東西:聽起來像不像人。
Mistral 主張不只是「唸出文字」,而是「理解文字的語境」。包括語氣是中性、開心還是諷刺,並且進一步捕捉說話者本身的個性:自然停頓、節奏、語調起伏、情緒彈性。這叫做「聲音適應」,而不只是「語音合成」。
Mistral 讓你覺得在跟人說話。
跟 ElevenLabs 直球對決
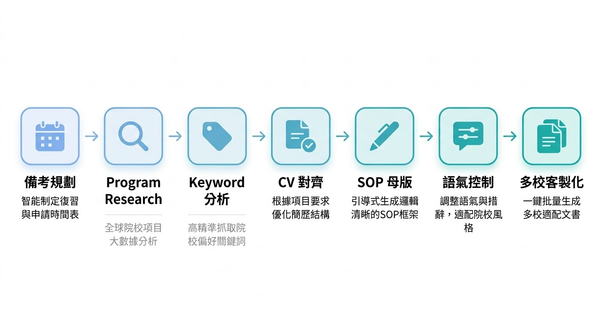
Mistral 做了一項人工評估實驗:在 9 種語言中,分別找兩位以該語言為母語的知名人士作為聲音樣本,由 3 位標注員對 Voxtral TTS 和 ElevenLabs Flash v2.5 進行側對側自然度比較。結果是 Voxtral 在自然度上勝出,同時維持了相近的首字元輸出延遲(TTFA)。他們也指出 Voxtral 的品質達到了 ElevenLabs v3 的同等水準。
沒有用模糊的「業界頂尖」來帶過,直接點名對手、公開測試條件、讓數據說話。
Voxtral TTS 架構
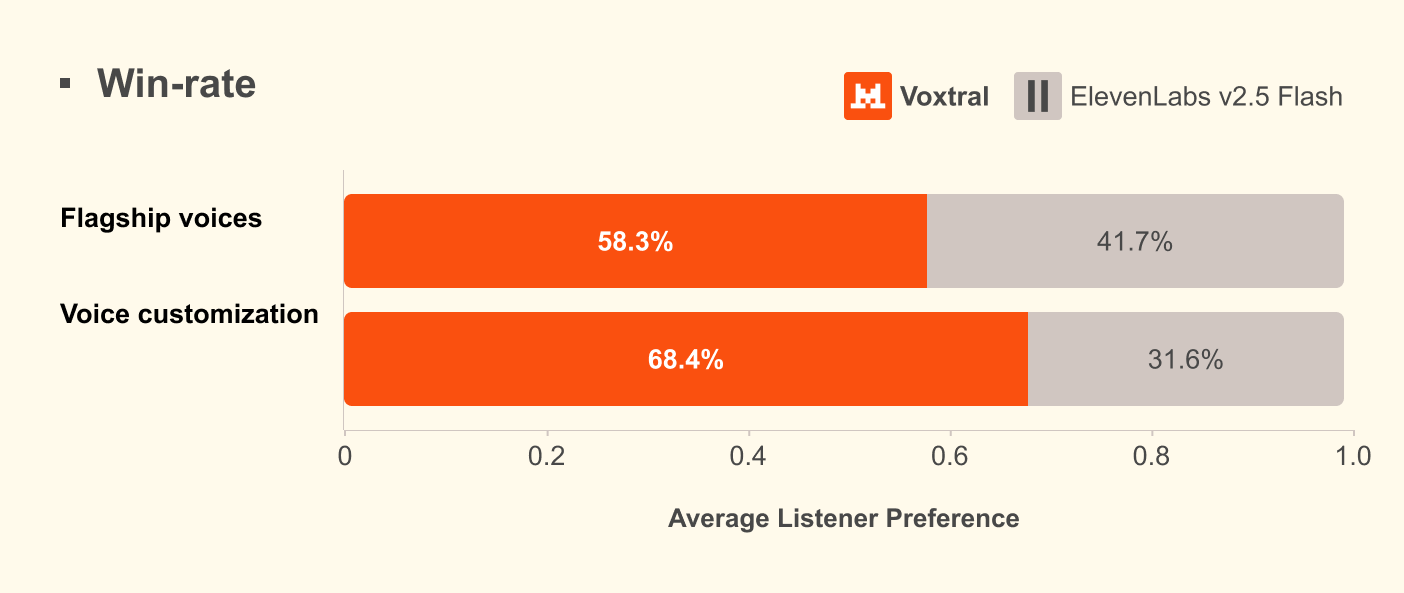
Voxtral TTS 是 Transformer 自回歸 + Flow Matching 混合架構,建立在 Ministral 3B 之上,分為三個部分:
- 34 億參數的 Transformer 解碼器骨幹
- 3.9 億參數的 Flow Matching 聲學轉換器
- 3 億參數的神經音訊編解碼器。
只需要 3 到 25 秒的聲音樣本,就能適應一個全新的聲音,捕捉的不只是音色,還有那個人說話的細微口音、語調甚至不流暢的停頓習慣。
這對企業端的聲音庫建立來說是一個很大的門檻降低。
同時展現了零樣本跨語言聲音適應能力,即使沒有特別針對此訓練,它也可以用法語聲音說出帶法語口音的英文,被用來建立串聯式的語音翻譯系統。
企業最在意
在典型輸入條件下——10 秒語音樣本、500 個字元文字——Voxtral TTS 的模型延遲是 70 毫秒,即時處理倍率(RTF)約為 9.7 倍。
模型原生支援最長兩分鐘的音訊生成,API 層則透過智慧交錯處理支援任意長度。 對一個要跑在客服電話系統、語音 Agent、即時翻譯場景的模型來說,70 秒是需要認真看待的。
Voxtral TTS 可以在 Mistral Studio 的 Playground 直接試用,也可以透過 API 接入。一個帶有多個參考聲音的版本已在 Hugging Face 以 CC BY NC 4.0 授權開放下載。
非商業用途開放,商業用途走 API。這個分層策略讓使用者可以自由實驗,企業付費用生產級服務,邏輯清楚。
不只是一個 TTS 模型
Mistral 語音是 AI Agent 最後一塊還沒被完全整合的 UX 介面。有了語音輸入(Voxtral Transcribe),現在有了語音輸出(Voxtral TTS),加上中間的語言模型推理,一個完整的語音 Agent 循環就關起來了。
Mistral 定位清楚了:Voxtral TTS 與 Voxtral Transcribe 搭配,構成完整的語音到語音管線,也可以單獨接入現有的語音辨識和語言模型堆疊。
對企業端來說,他們可以在一個供應商的生態裡完成整個語音 AI 的建構,不用再東拼西湊。
這是 Mistral 真正在搶的位置。
Source
Mistral releases a new open source model for speech generation