OpenAI 震撼發布 開源安全推理模型:gpt-oss-safeguard,徹底革新內容審核的「政策理解」時代
OpenAI 開源 gpt-oss-safeguard 安全推理模型,依據政策對內容分類,並提供完整的推理鏈 (CoT)。


AI 安全審核邁向「主動理解」新紀元
在數位內容爆炸式增長的今天,如何高效、透明且靈活地進行內容審核(Content Moderation)始終是科技巨頭面臨的核心挑戰。傳統的內容安全分類器往往被視為缺乏解釋性的「黑箱」系統,其標準固定且更新緩慢。
OpenAI 現推出重大解決方案:gpt-oss-safeguard 系列模型,這是一組全新的開源安全推理模型(open-weight reasoning models for safety tasks)。它們專門針對安全分類(safety classification)和內容審核任務而設計,核心理念是讓模型能夠在推理階段直接讀取並應用開發者定義的安全政策(Policy)文本。這標誌著內容安全從過去的「被動學習規則」正式進入「主動理解規則」的新階段。
這套模型屬於 OpenAI 「GPT-OSS」系列(開源推理模型家族)的一部分,它不像傳統模型那樣需要從數萬條手工標註數據中費力地「猜測」規則,而是能直接透過「推理」方式判斷內容是否合規。
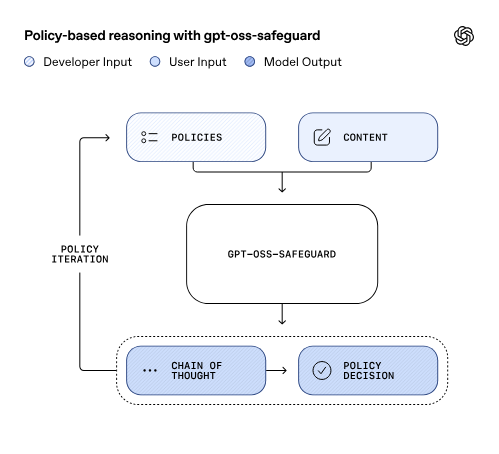
核心突破:以推理代替記憶,實現政策驅動的透明化審核
傳統的內容安全模型,例如 OpenAI 自家的 Moderation API,嚴重依賴:
- 大量手工標註數據。
- 固定的預訓練安全標準。
這種方法雖然在某些複雜風險分類上可能表現優異,但卻帶來了靈活性、透明度和可解釋性不足等致命缺陷。一旦安全政策或社會規範發生變化,傳統模型往往需要耗費巨大資源重新收集數據並重新訓練,導致更新慢。此外,它們無法解釋「為什麼」某段內容違規,並且在面對新型風險(如 AI 詐騙、深度偽造)時,泛化能力往往較差。
gpt-oss-safeguard 模型的目標正是解決這些固有問題。它提出了一種新思路:讓模型在推理階段直接讀取安全政策文本,從而「理解並應用」開發者定義的規則。
透明化工作原理:輸入、輸出與推理鏈 (CoT)
gpt-oss-safeguard 的工作方式類似於一種邏輯審查流程。
輸入結構:
Policy(政策):由開發者撰寫,詳細描述允許或禁止的行為。
Content(待判內容):模型需要根據政策判斷該內容是否合規。
輸出結果:
Classification:分類結果,例如 Safe / Unsafe / Unclear。
Reasoning(推理過程):模型逐步解釋其判斷過程。
這種「推理式安全分類」的核心在於其推理鏈(Chain-of-Thought, CoT)的生成。模型會先讀取政策文本,將政策轉化為內部邏輯,隨後對輸入內容進行逐步推理,最終生成分類結論與完整的推理鏈。
OpenAI 強調,理解模型如何對政策分類進行推理,對於有效利用這些模型至關重要。CoT 的存在使得開發者能夠審查模型的決策邏輯,從而評估模型是否準確地執行了政策意圖。
模型架構與開放授權細節
OpenAI 此次公開了兩個不同規模的 gpt-oss-safeguard 模型:
- gpt-oss-safeguard-120b
- gpt-oss-safeguard-20b
這兩者都是從 gpt-oss 模型後續訓練(post-trained)而來,目的是使其能夠從提供的政策中進行推理,以便對內容進行標註。
所有模型均在 Apache 2.0 開源許可證下發布,允許用戶自由修改與商用。模型的權重可以直接從 Hugging Face 下載。這些模型是純文本模型(text-only models),與 OpenAI 的 Responses API 相容。
模型的主要特徵包括:
- 可定制性(Customizable)。
- 提供完整的推理鏈(Full Chain-of-Thought, CoT)。
- 可搭配不同的**推理力度(Reasoning Efforts)**使用,包括低、中、高三個等級。
- 支持結構化輸出(Structured Outputs)。
值得注意的是,OpenAI 建議使用這些模型來依據提供的政策分類內容,而非作為終端用戶交互的核心功能(如聊天設定)。如果需要用於終端用戶應用,基礎的 gpt-oss 模型會是更好的選擇。
性能基準評估:對抗業界頂尖安全模型
OpenAI 針對 gpt-oss-safeguard 模型進行了嚴格的基準測試,將其與 gpt-5-thinking、基礎 gpt-oss 模型以及內部的 Safety Reasoner 進行了比較。
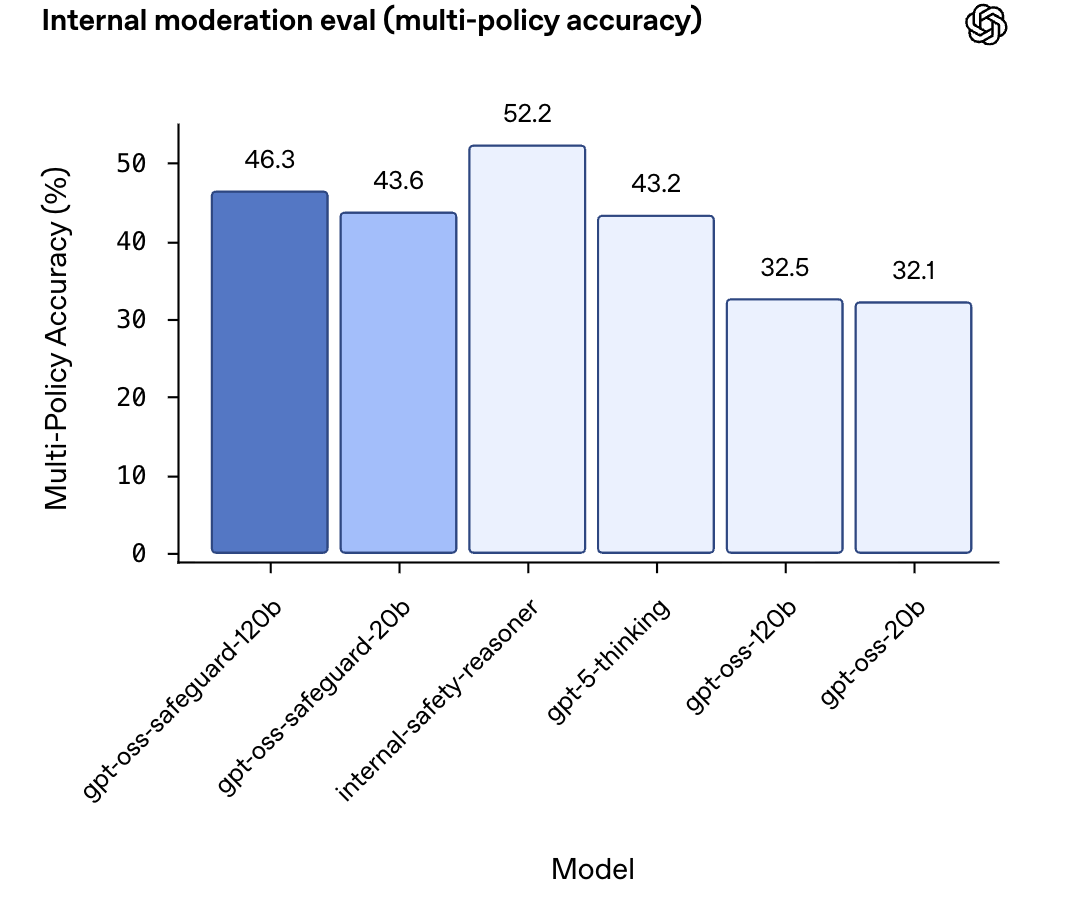
多政策分類準確性 (Multi-policy Accuracy)
這是一項極具挑戰性的內部評估。測試要求模型必須在同時提供多個政策的情況下,精確匹配所有政策下的黃金標準標籤,才被計為準確。
| 模型 | 多政策準確性 (Multi-policy accuracy) |
|---|---|
| internal-safety-reasoner | 52.2% |
| gpt-oss-safeguard-120b | 46.3% |
| gpt-oss-safeguard-20b | 43.6% |
| gpt-5-thinking | 43.2% |
| gpt-oss-120b | 32.5% |
| gpt-oss-20b | 32.1% |
評估結果顯示: gpt-oss-safeguard 模型和內部 Safety Reasoner 在多政策準確性方面優於 gpt-5-thinking 和基礎 gpt-oss 開源模型。令人驚訝的是,鑑於 gpt-oss-safeguard 模型的規模較小,它們超越了 gpt-5-thinking 的表現。
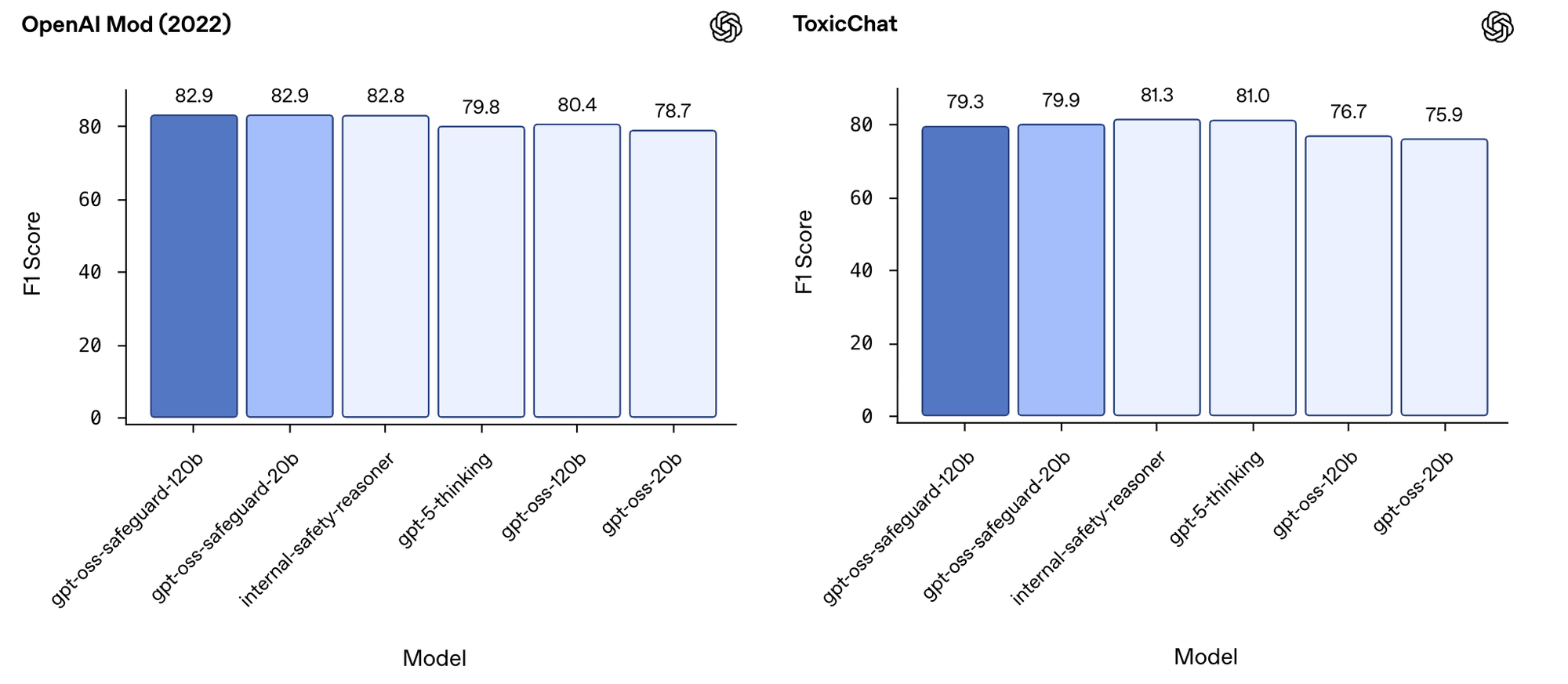
既有審核數據集評估 (F1 Score)
模型也在 2022 年 OpenAI 發布的審核數據集和 ToxicChat 公共基準上進行了測試。
在 2022 年的 OpenAI 審核評估集上(使用調整後的內部安全政策),gpt-oss-safeguard 在 F1 分數上略微優於所有其他受測模型,包括內部 Safety Reasoner (82.8%) 和 gpt-5-thinking (79.8%)。儘管 gpt-oss-safeguard-120b 和 gpt-oss-safeguard-20b 均獲得 82.9% 的 F1 分數,但與 Safety Reasoner 的差異在統計學上並不顯著。
在 ToxicChat 基準測試中,Safety Reasoner (81.3%) 和 gpt-5-thinking (81.0%) 略微優於 gpt-oss-safeguard-120b (79.3%) 和 gpt-oss-safeguard-20b (79.9%)。儘管如此,OpenAI 預期 gpt-oss-safeguard 模型相對較小的規模,使其在此類任務中仍具有優勢。
多語言性能
在多語言能力方面,OpenAI 使用了 MMMLU 評估集,該數據集包含 MMLU 經過專業人工翻譯的 14 種語言版本。
結果表明,gpt-oss-safeguard 模型在所有推理級別上的性能與 gpt-oss 模型持平。例如,在中文評估中,gpt-oss-safeguard-120b 的準確度(中等推理級別)為 82.7%,與 gpt-oss-120b 的 82.1% 接近。需要注意的是,這些多語言評估是在聊天環境中進行的,並不直接評估其在「提供政策進行內容分類」時的性能。
技術挑戰與模型安全觀察
儘管 gpt-oss-safeguard 在政策推理方面表現出色,但技術報告也誠實地指出了幾個關鍵的觀察到的安全挑戰與限制:
資源密集度與性能天花板
gpt-oss-safeguard 的第一個限制是其在時間和計算上可能相當密集(time and compute-intensive)。這使得它難以擴展到所有平台內容的即時審核。在 OpenAI 內部,他們使用多種方式來處理這一問題,包括:
- 使用更小、更快的分類器來預先確定哪些內容需要進一步評估。
- 在某些情況下,異步地使用 Safety Reasoner,以提供低延遲的用戶體驗,同時保持介入不安全內容的能力。
其次,對於更複雜的風險,那些經過數萬條高品質標註樣本訓練的專門分類器,在性能上仍可能優於 gpt-oss-safeguard。因此,對於追求更高性能的複雜風險,花時間訓練專門的分類器仍可能是首選。
推理鏈 (CoT) 的幻覺風險
由於 OpenAI 並未對 gpt-oss-safeguard 模型的 CoT 施加直接優化壓力,因此這些推理鏈可能包含幻覺內容 (hallucinated content)。這些幻覺內容可能包括不符合 OpenAI 標準安全政策、甚至與模型被要求解釋的政策不符的語言。
在針對模型事實準確性的幻覺評估中 (SimpleQA 和 PersonQA 數據集),gpt-oss-safeguard 模型與其 gpt-oss 對應模型表現大致持平。其中,gpt-oss-safeguard-120b 在這兩項評估中,比 gpt-oss-120b 略微更容易產生幻覺。
指令層次結構 (Instruction Hierarchy) 的表現差異
指令層次結構測試評估了當系統消息、開發者消息和用戶消息指令發生衝突時,模型遵循優先級指令的能力。雖然 OpenAI 不推薦將 gpt-oss-safeguard 用於終端用戶交互,但他們仍對其進行了測試。
評估結果顯示,在多數情況下,gpt-oss-safeguard 模型傾向於表現不如其 gpt-oss 對應模型。例如,在「系統提示詞提取」測試中,gpt-oss-safeguard-120b 的得分 (0.993) 雖然遠高於 gpt-oss-120b (0.832),但在「提示詞注入劫持」(Prompt injection hijacking)等其他幾項測試中,safeguard 模型的得分卻較低。OpenAI 表示,需要更多研究來理解造成這種現象的原因。
對抗性攻擊與越獄 (Jailbreaks) 評估
儘管抵抗越獄的穩健性對於內部使用的 gpt-oss-safeguard 模型來說不如面向終端用戶的模型重要,但 OpenAI 仍評估了它們對抗惡意提示(旨在規避模型拒絕)的能力。
在 StrongReject 評估中,gpt-oss-safeguard-120b 表現優於 gpt-oss-120b,但在「暴力提示」和「非法/非暴力犯罪提示」等類別中,gpt-oss-safeguard-20b 的表現則比 gpt-oss-20b 下降了 1 到 5 個百分點。
公平性與偏見 (Fairness and Bias)
在 BBQ 評估(一個針對問答系統的偏見基準測試)中,gpt-oss-safeguard-120b 和 gpt-oss-safeguard-20b 兩者在所有指標上均優於其 gpt-oss 對應模型。這顯示出模型在解決潛在偏見問題上有所進步。
總結:開源、透明、政策驅動的未來
OpenAI 推出的 gpt-oss-safeguard 系列模型,透過其獨特的政策推理能力和完整的 Chain-of-Thought (CoT) 輸出,為內容安全領域帶來了急需的透明度和靈活性。儘管技術報告指出了其在資源密集度與某些特定安全指標上的限制,但它在多政策分類準確性上的強勁表現,以及對政策文本的直接理解和應用,使其成為開發者和企業在定制化內容審核方面極具吸引力的開源選擇。
OpenAI 透過 Apache 2.0 許可證開放這些模型,明確了其意圖:讓社群能夠自由地利用和改進這套工具,共同推進 AI 安全標準,使得內容安全從一個封閉的「黑箱」轉變為一個可解釋、可審查的政策執行系統。



