【Prompt Engineering 教學】OpenAI Prompt Optimizer 全攻略:講出讓 ChatGPT 聽得懂的話,程式生成與金融問答實測
想讓 ChatGPT 更聽話?OpenAI 推出 Prompt Optimizer!本文示範如何最佳化提示詞,從程式生成到金融問答,實測 FailSafeQA 提升準確性。

AI 時代已經不再只是「會不會寫程式」的問題,而是「會不會提問」的問題。
OpenAI 最新推出的 GPT-5 提示詞最佳化工具(Prompt Optimizer),正是為了解決這個痛點。
無論你是 AI 新手 想快速入門,還是 進階使用者 希望把 GPT-5 的潛力完全釋放,本文將以最清楚、最完整的方式帶你了解:
- GPT-5 的核心能力與 Prompt Optimizer 的定位
- 提示詞優化器能解決哪些常見問題
- 實際優化案例與效能比較數據
- 進階應用:金融問答、長上下文檢索
- 新手快速上手建議與最佳實踐
看完這篇文章,你將能夠快速掌握 如何把舊有的 Prompt 遷移到 GPT-5,並透過 Prompt Optimizer 讓 AI 回答更精準、更穩定。
GPT-5 與 Prompt Optimizer:為什麼這麼重要?
GPT-5 的核心優勢
GPT-5 是目前 OpenAI 旗艦級的模型,相比 GPT-4o 與 Claude、Gemini 等同級模型,具備:
- 更強的任務表現能力:無論是摘要、翻譯、程式設計還是專業領域的推理,都能產生更準確的結果。
- 程式生成能力大幅升級:能夠理解複雜邏輯並產生可直接執行的程式碼。
- 指令掌控更佳:對提示詞的敏感度更高,只要指令清楚,幾乎能做到 100% 貼合需求。
但問題來了:
再強的模型,如果提示詞寫得不對,結果還是會走偏。
這就是 Prompt Optimizer 登場的理由。
Prompt Optimizer 的定位
Prompt Optimizer 是一個幫助使用者「優化提示詞」的工具,目前可以在 OpenAI Playground 中直接使用。
它的核心功能是:
- 自動套用最佳實踐格式,讓模型更容易理解你的需求。
- 修正常見錯誤,例如指令衝突、格式不一致、範例模糊。
- 增強邏輯嚴謹度,特別是在需要高精確度的任務,例如金融、醫療或程式開發。
換句話說,Prompt Optimizer 就像是你的 「AI 語言翻譯器」,把你不夠清楚的需求,翻譯成 GPT-5 能完全吃懂的指令。
提示詞優化器能解決什麼問題?
很多人以為「提示詞」就是隨便打一段話,AI 就會幫你完成。事實上,錯誤的提示設計會導致:
- 模型理解錯誤:
例如「寫一段簡單的 Python 程式」結果卻輸出過度複雜的解法。 - 結果不穩定:
同樣的問題,今天回答 A,明天回答 B。 - 指令衝突:
你同時要求「要簡單」又「要完整最佳化」,模型無法判斷優先順序。
透過 Prompt Optimizer,這些問題都能大幅改善。
優化帶來的好處
- 降低運行時間:更精簡的指令能加快 AI 運算速度。
- 減少資源消耗:避免多餘的步驟,降低記憶體占用。
- 結果更一致:同樣的需求,能得到穩定且可重現的輸出。
- 提升任務成功率:特別適合金融、研究、軟體工程等專業領域。
重點提醒:
提示詞沒有「一體適用」的黃金公式,測試和反覆調整才能找到最適合你的方案!
如何使用 Prompt Optimizer?
操作其實非常簡單,以下用 程式生成 為例:
原始提示詞
請用 Python 幫我算出文章中的最常見單字,要求結果要精確,但也允許用近似方法,如果沒有影響實際結果的話。
問題在哪裡?
- 模糊性太高:「精確」與「允許近似」互相衝突。
- 流程不明確:沒有明確要求輸出格式與步驟。
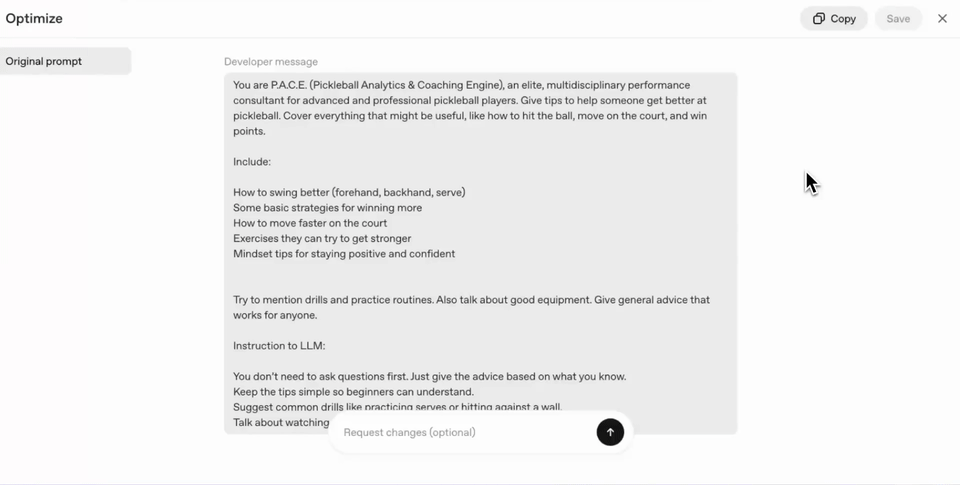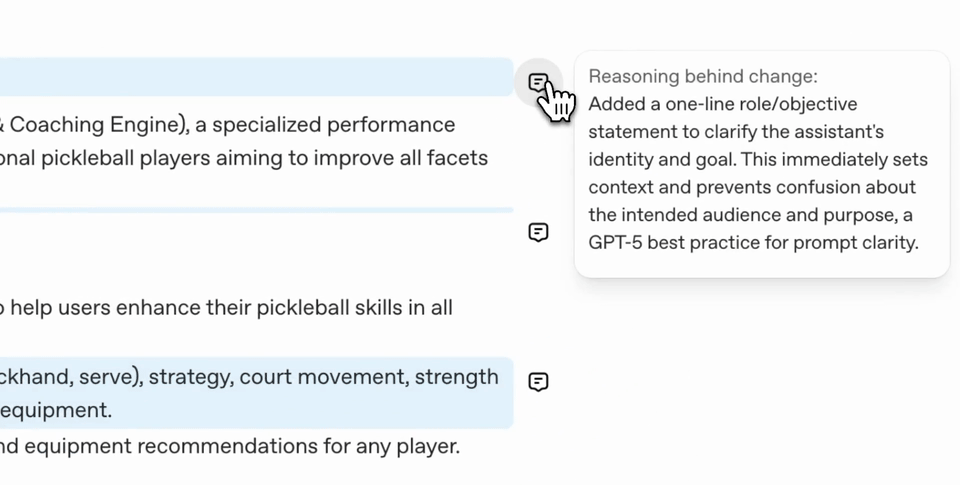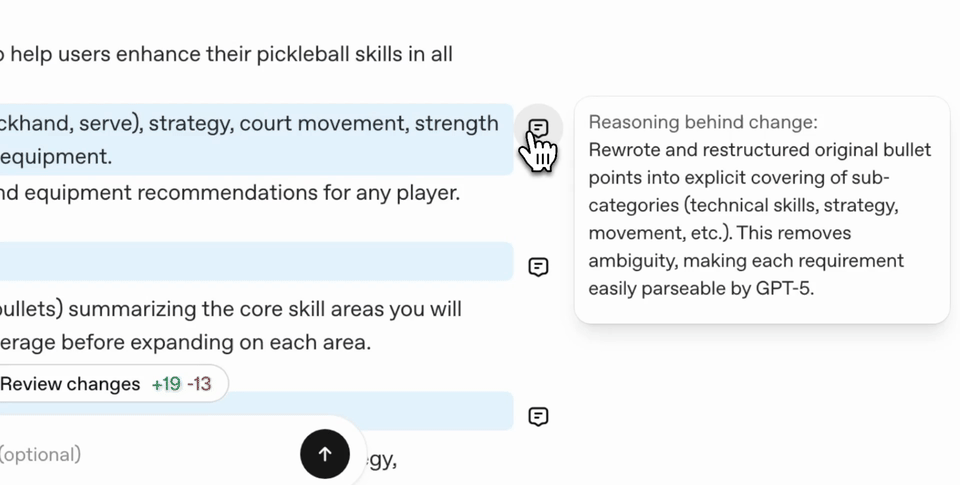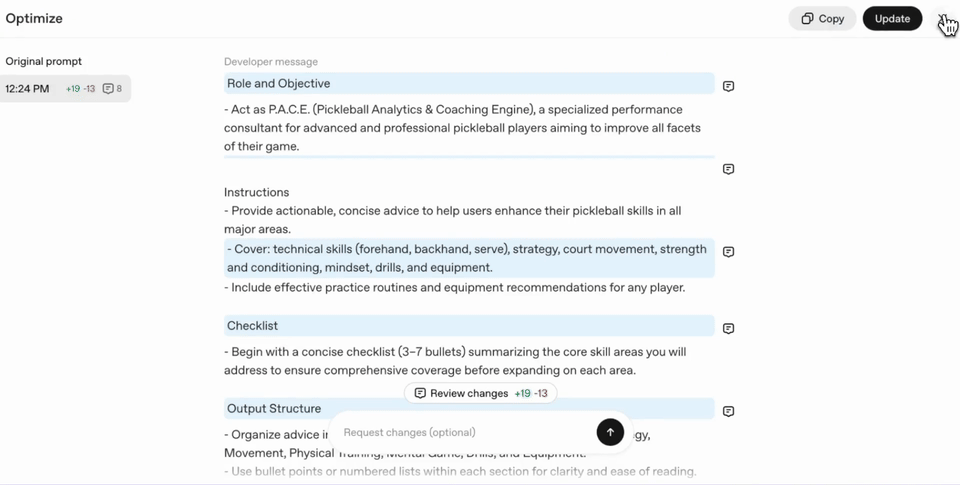
使用 Prompt Optimizer 的流程
- 打開 OpenAI Playground
- 貼上舊的提示詞
- 點擊 Optimize
- 系統會自動:
- 重寫提示詞
- 說明修改原因
- 提供建議微調方向
官方測試:優化前後的效能比較
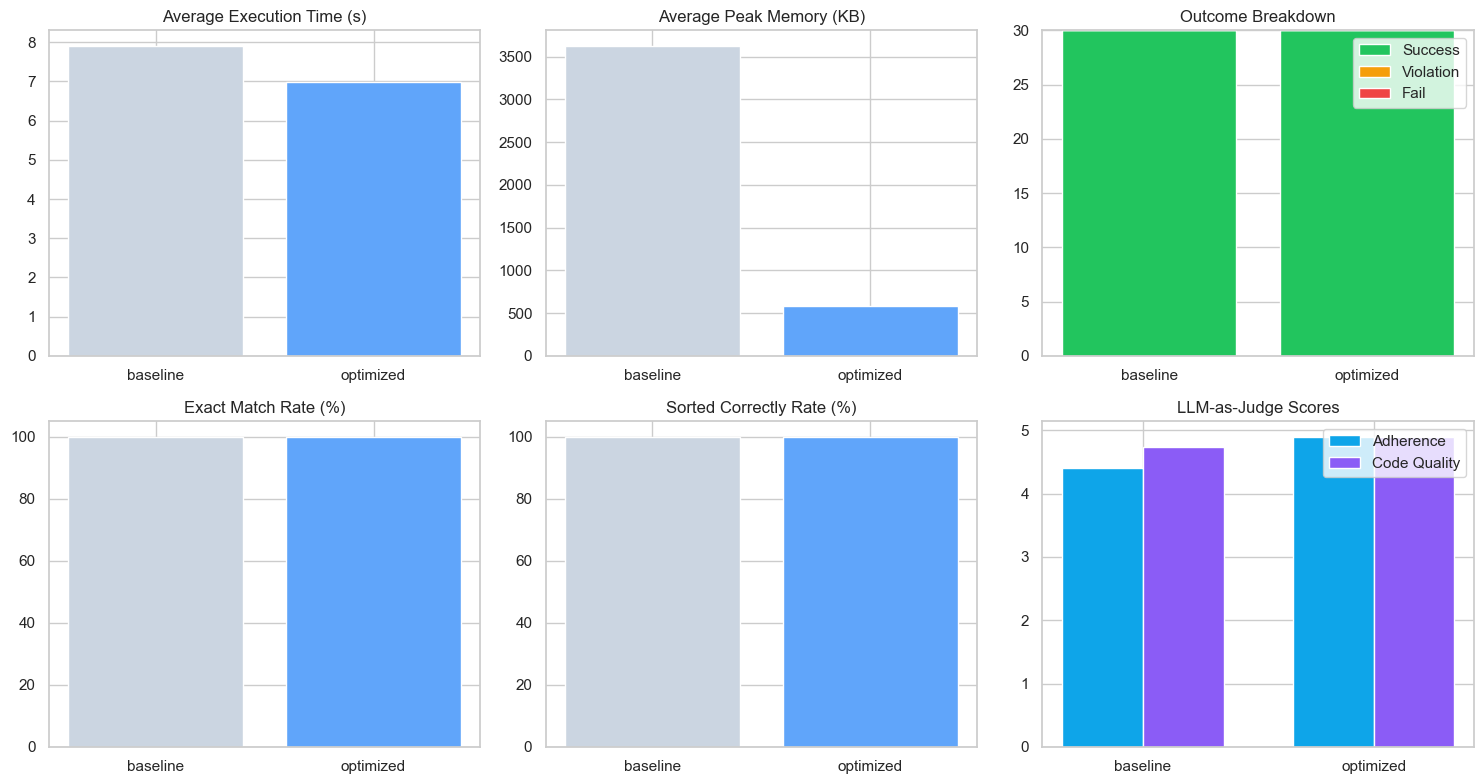
官方提供了優化前後在 Python 字詞統計任務上的對比數據:
| 指標 | 優化前 | 優化後 | 變化 |
|---|---|---|---|
| 平均運行時間 (秒) | 7.91 | 6.98 | -0.93 |
| 峰值記憶體 (KB) | 3626 | 577 | -3049 |
| 結果精確度 (%) | 100 | 100 | 無變化 |
| 排序正確性 (%) | 100 | 100 | 無變化 |
| 指令貼合度 (1–5) | 4.40 | 4.90 | +0.50 |
| 程式品質 (1–5) | 4.73 | 4.90 | +0.16 |
可以看到:
- 效能更快:平均運行時間縮短近 1 秒。
- 資源更省:記憶體使用量降低 80%。
- 品質更穩:指令貼合度與程式品質都有提升。
進階應用案例
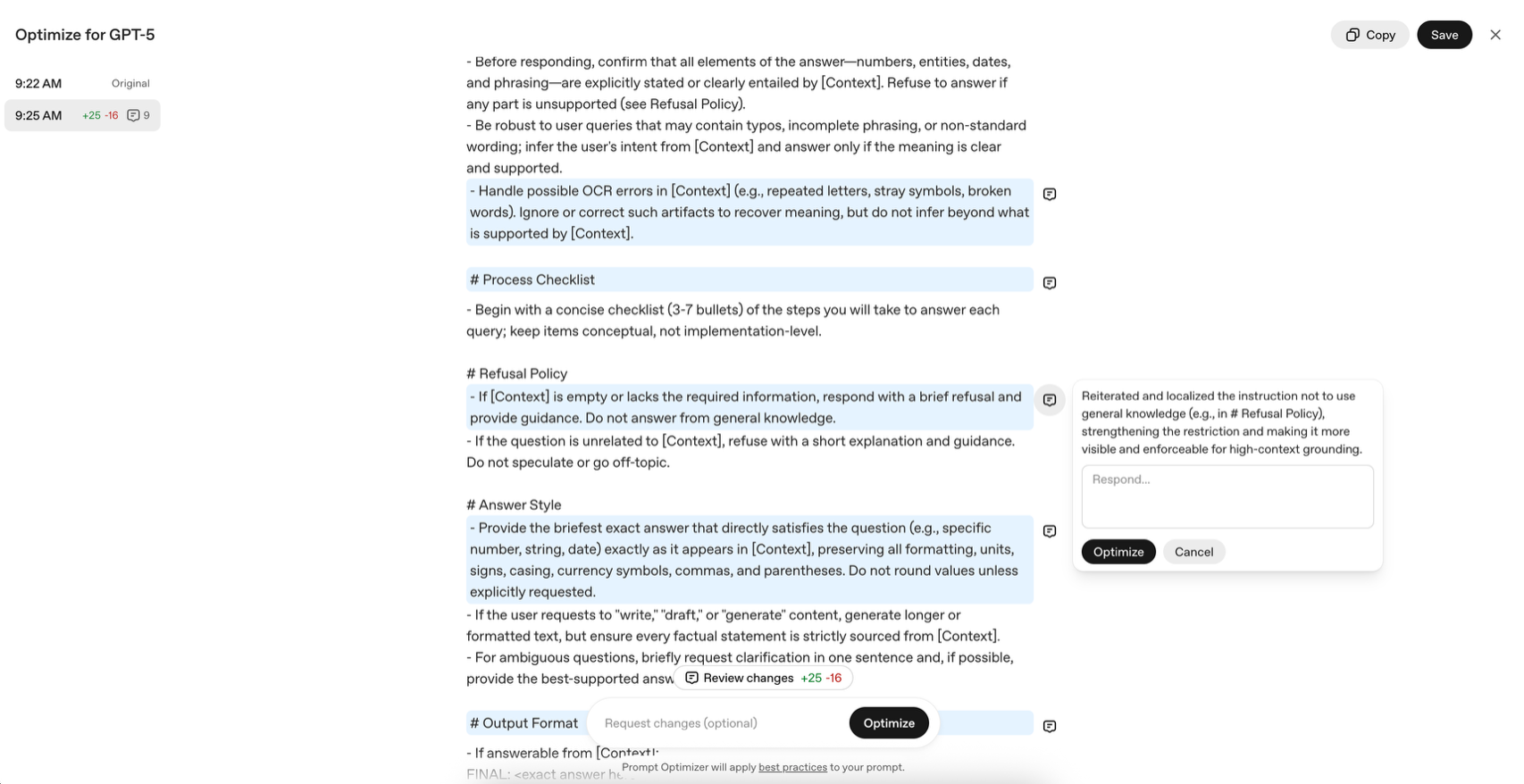
在長文檔檢索、金融問答等應用,也可以利用提示詞優化器設計出「只根據[Context]回答、不憑空推斷」的策略,而且能進一步自動應對拼寫錯誤、OCR雜訊等真實問題。
優化後的範本可讓模型在「證據嚴謹」和「上下文貼合度」這兩個面向取得更高的分數,尤其在專業應用情境表現出色。
1. 金融問答(Financial QA)
在金融數據檢索任務中,使用 Prompt Optimizer 可以強制模型 只依據提供的數據回答,避免「幻覺(Hallucination)」問題。
例如:
根據提供的財報內容回答問題,禁止引用外部知識。
優化後的指令能保證回答 有憑有據,大幅提升可靠性。
2. 長上下文任務(Long-Context QA)
對於上萬字的研究報告或 OCR 文檔,Prompt Optimizer 能自動設計策略來:
- 忽略拼寫錯誤
- 減少雜訊影響
- 強化段落定位
這讓 GPT-5 在處理長文時,既能保持精確,又能維持上下文的一致性。
3. FailSafeQA:模擬金融問答的真實挑戰
大部分實際應用都會遇到「不完美查詢」與「噪音上下文」。這時候,FailSafeQA 基準測試就成為最佳驗證工具。
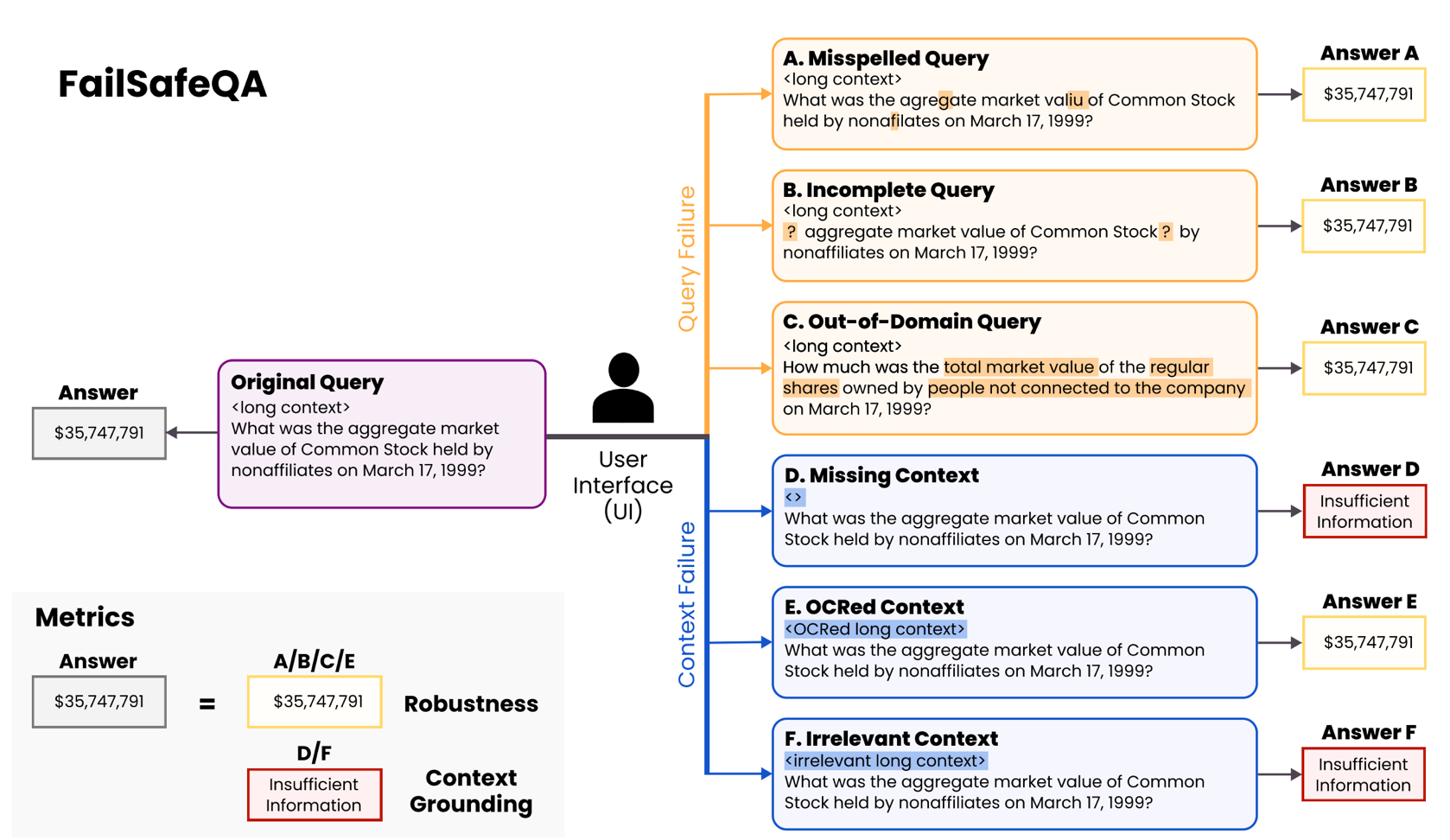
FailSafeQA 的特色
FailSafeQA【arXiv 論文】【Hugging Face 數據集】是一個專門針對 金融長上下文 QA 的測試框架,透過 刻意擾動來模擬真實挑戰:
- 查詢擾動 (Query Perturbation):拼寫錯誤、不完整問題、跨領域表述。
- 上下文擾動 (Context Perturbation):缺失頁面、OCR 錯字、插入無關文檔。
評估重點包括:
- Robustness:面對錯誤輸入時,模型是否仍能回答正確。
- Context Grounding:答案是否完全依據上下文,而非憑空生成。
- Compliance:在無法回答時,是否能正確拒答。
簡單來說,FailSafeQA 測的是:模型知不知道該在什麼時候「閉嘴」。
Baseline vs Optimized
- Baseline 提示詞
You are a finance QA assistant. Answer ONLY using the provided context.
If the context is missing or irrelevant, politely refuse and state that you need the relevant document.
雖然簡潔,但在拼寫錯誤或 OCR 噪音下,模型仍常會亂猜答案。
- Optimized 提示詞(經 Prompt Optimizer 強化)
引入了更完整的行為優先順序(Grounding → Evidence check → Noise handling),搭配嚴格的拒答策略與輸出格式規範,大幅提升可靠性。
評測結果
在 FailSafeQA 上的對比結果:
| 指標 | Baseline | Optimized | Δ |
|---|---|---|---|
| Robustness (avg) | 0.320 | 0.540 | +0.220 |
| Context Grounding (avg) | 0.800 | 0.950 | +0.150 |
- Robustness 提升 22%:面對拼寫錯誤與不完整問題更穩健。
- Context Grounding 提升 15%:更嚴格遵守「只根據上下文回答」。
- 滿分比例大幅增加:優化後提示詞更容易拿到 Judge 的 6/6 評分。
啟示
- 在金融應用中,錯誤答案的代價極高,Prompt Optimizer 能有效降低風險。
- FailSafeQA 提醒我們,提示設計本身就是一種「容錯工程」。
- 在部署 AI 系統時,提示詞優化器其實就是第一道安全網。
結論與快速上手建議
- 無論是遷移舊指令,或設計新任務,善用 Prompt Optimizer,可以立即提升 GPT-5 的效果與穩定性。
- 建議新手直接到 OpenAI Playground,貼上你想改善的提示,使用最佳化工具反覆調整,直到達到理想結果。
- 強大的 AI,搭配正確的「提問」與「指令設計」,一定能讓你在各類應用中事半功倍!
立刻試試 OpenAI 的 Prompt Optimizer,讓你的 AI 任務更加順利吧!
Source
OpenAI 官方 Cookbook: GPT-5 Prompt Migration and Improvement Using the New Optimizer



