【深度專題】Context Engineering 是什麼?為什麼 Manus 團隊花千萬美金踩坑,只為搞懂「怎麼喂模型」?
這不只是 prompt 工程的進化版,而是 AI Agent 時代真正的關鍵技術。


什麼是上下文工程(Context Engineering)?
在生成式 AI 崛起後,越來越多開發者開始打造 AI Agent:讓語言模型像助理一樣,連續思考、多步操作、甚至自己規劃任務。
這些 Agent 不需要自己「從零訓練一個模型」,因為 GPT-4、Claude、Gemini 等模型已經夠聰明了——真正的挑戰,變成了「你餵進去的上下文好不好」。
所謂「上下文」,其實就是模型的輸入
對語言模型來說,它不記得你是誰,也不會主動學習,它只會根據「這一次輸入的內容」來猜下一個字要說什麼。
這次的輸入,就是上下文(context)。
所以,如果你希望一個 AI Agent 有記憶、有邏輯、有工具使用能力,那你就必須:
- 給它一個設計好的系統提示(system prompt)
- 讓它記得前面發生過什麼事(歷史輸入/輸出)
- 教它怎麼執行工具(Tool 使用規則)
- 幫它整理資訊(壓縮 / 儲存觀察到的資料)
這一切的「設計上下文流程」的技術,就叫做 Context Engineering。
你可以把 Context Engineering 想像成「餵模型吃好吃的 prompt 食譜」:
就像一位語言模型是天才廚師,但你不給食材、或亂給食材,它也煮不出你想吃的東西。Context Engineering 就是那位掌控食材的人——
它決定:
- Prompt 要怎麼寫:清楚、具體、有格式
- 資料怎麼整理:要 JSON 嗎?還是 YAML?還是像自然語言?
- 記憶怎麼儲存:要放進上下文嗎?還是寫進檔案?
- 任務怎麼規劃:先做什麼?做完要不要複查?錯了要怎麼補救?
這一切都不改模型本身,只透過喂它更好的上下文,就能大幅改變它的表現。
Manus 團隊:用千萬美金踩坑後得出的設計哲學
Manus 是一個 AI agent 平台,從一開始就做出了一個與眾不同的決定:
❝ 不自己訓練模型,也不靠微調,而是全力投注在 Context Engineering 上。 ❞
他們在實作過程中踩遍各種地雷、重寫了 6 次框架,最終把經驗整理成一套極具參考價值的準則,稱得上是「實戰中淬鍊出的上下文工程七大原則」。
這些原則背後,並不是空泛的哲學,而是與現實中的 API 成本、執行延遲、錯誤率、使用體驗息息相關的架構設計關鍵。
接下來,我們就來逐條拆解這七個 Manus 團隊的「Context Engineering 生存法則」,看看如何透過 prompt、記憶、工具與錯誤處理的精細設計,讓一個 AI Agent 真的能用、能學、能修正。
Manus AI 團隊七大實戰心法:反共識卻實用
上下文工程比自己訓練模型更香
❝ 別造輪子,造路給模型走就夠了。 ❞
Manus 團隊一開始就做出戰略選擇:不訓練自己的模型,而是用現成的大模型+自己控制上下文。這樣不但能更快出產品,每次模型更新(例如 Claude、GPT 升級)也能立刻受益。
KV-Cache 命中率是效能的命門
一個 prompt prefix 不穩,就讓你損失 10 倍成本。
KV-Cache(Key-Value Cache) 是大模型記憶機制的一部分,若上下文前綴保持一致,就能節省大量重複計算。
例如:Claude Sonnet 的 cache 命中每 1M tokens 僅需 $0.3 美元,未命中則要 $3!
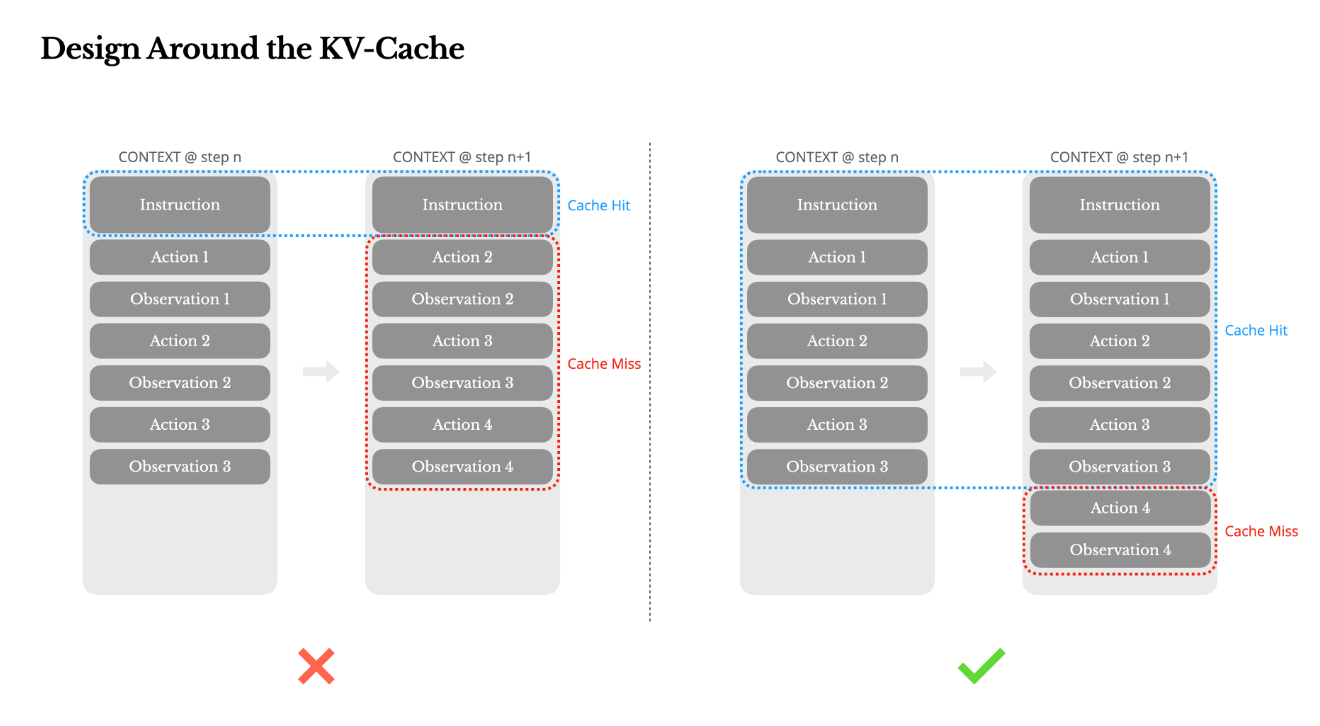
避免 cache 失效的技巧包括:
- Prompt 前綴不能動(不能加 timestamp)
- JSON 序列要穩定(key 順序一致)
- 不動舊內容,只 append 新訊息
上下文只能「加」,不能「改」
就像寫日記,不能刪昨天的內容。
這是為了維持上下文一致性與 cache 命中率。哪怕只改了一行錯字或換了格式,都可能導致重新編碼整個上下文。最好的做法是:永遠追加、永不修改。
工具多,不代表要亂加減
❝ 遮蔽程式碼比刪除更聰明。 ❞
當 Agent 能使用的工具越來越多(例如 plugin、生成功能等),你會想根據任務刪掉無用工具。但這會讓上下文改變,導致 cache 崩潰+模型混亂。
Manus 的做法是「不刪除工具,只在解碼時用 token 掩碼遮住它們」,讓模型看不到不該選的選項。
例如:
browser_開頭的是網頁工具shell_是終端工具
這種命名讓模型能按情境選工具,上下文卻維持不變。
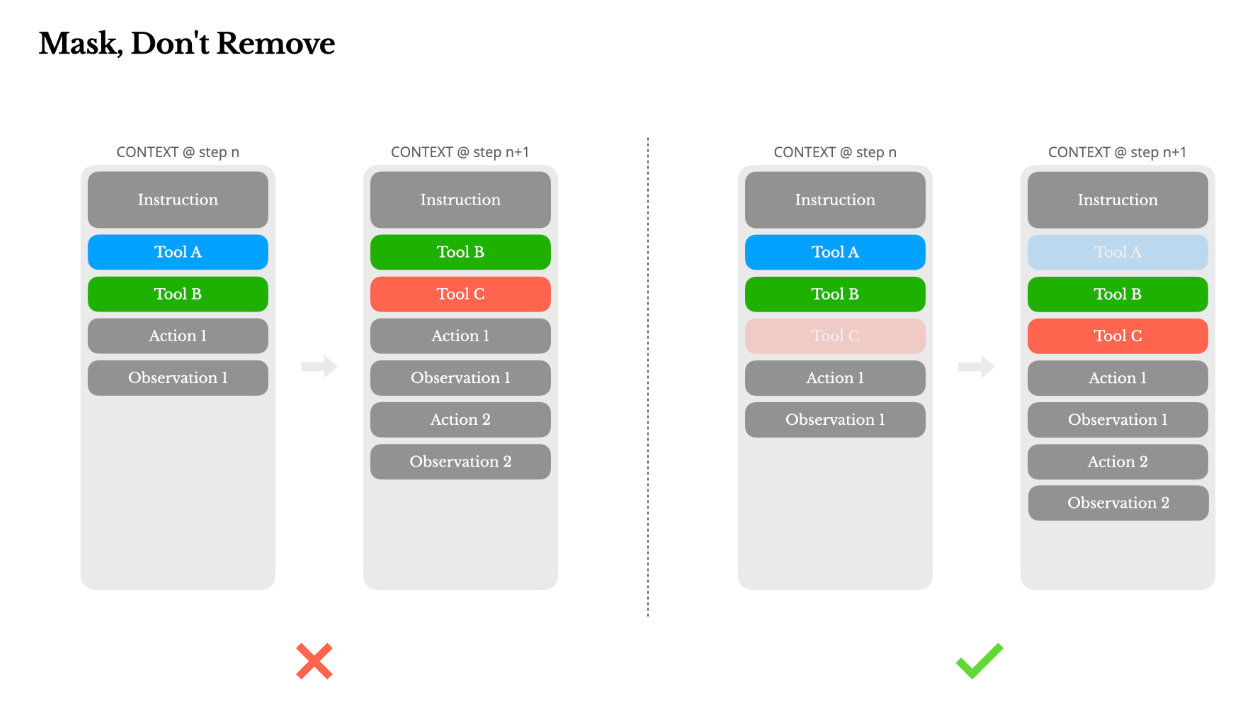
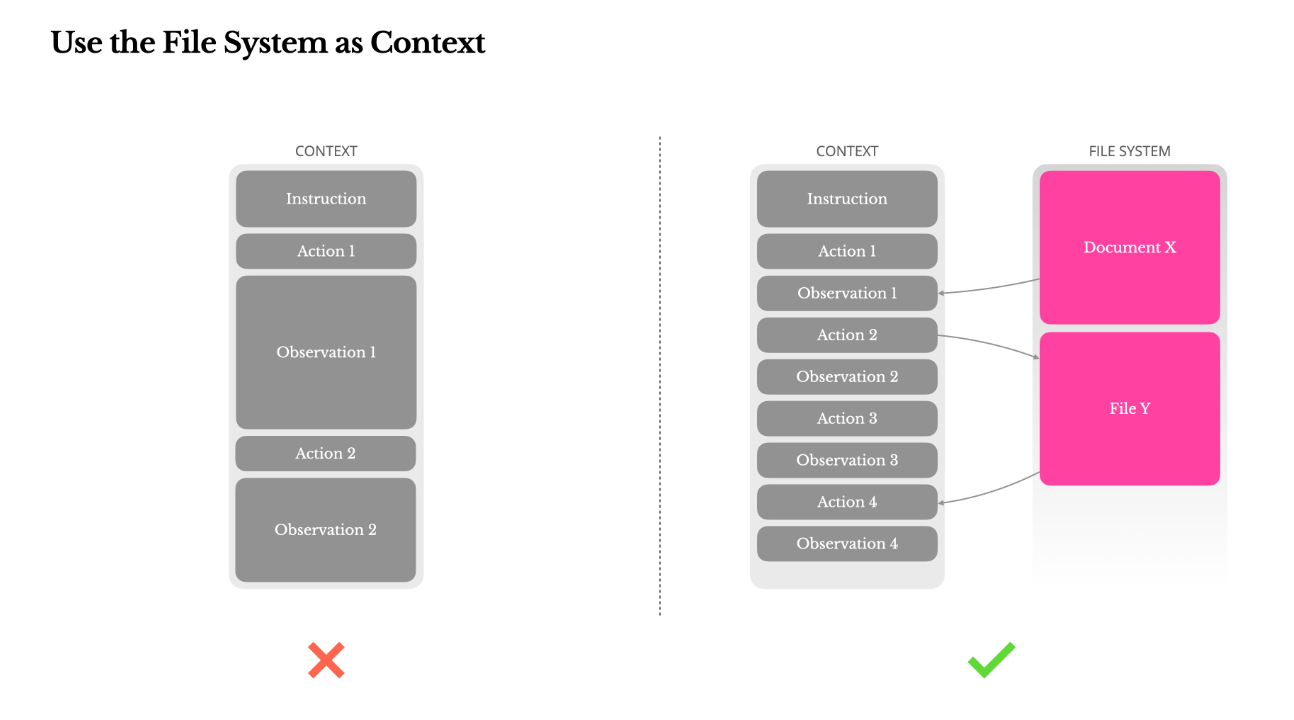
檔案系統是「外掛記憶」
大語言模型記憶有限,但檔案系統沒限制。
當 agent 執行複雜任務時,可能會與 PDF、網頁、Codebase 等交互,大量內容無法塞進上下文。
Manus 的解法:直接讓模型學會寫入/讀取 sandbox 中的檔案。
只要記住「檔案路徑」,需要時再抓內容回來,這讓 context 永遠保持輕巧,但 agent 卻像有無限記憶一樣聰明。
錯誤紀錄是 agent 成長的關鍵
別刪錯誤訊息,那是模型學會「別再做傻事」的依據。
模型會犯錯,像選錯工具、看錯格式、工具回傳錯誤等。不要清掉這些紀錄,因為 留下錯誤紀錄,模型才能調整行為。這是一種「自然語言式的 reinforcement」。

Few-shot 太單一,模型會陷入套路
多樣化提示,才有多樣化行為。
過去提示學習講求「一致性」,但對 Agent 來說,過度一致會導致「模式僵化」。例如讓 Agent 檢查 20 份履歷,它會逐漸「進入機械模式」,開始複製貼上、不看上下文。
解法是:加入微小變異(phrasing、順序、格式等),讓模型「保持清醒」,不被自己的例子誤導。

結論:真正的 Agent 時代,不靠大模型,而靠上下文工程
AI Agent 的真正威力,不在於模型有多強,而在於能不能處理複雜上下文、連續任務與不確定環境。
這篇 Manus 團隊的 blog,展示了「模型升級靠 OpenAI,Agent 智慧靠你自己」的關鍵觀念。如果你正要做 AI 應用,這 7 條上下文設計原則,可能會讓你少走 3 個月冤枉路、少燒 3 萬美金。
Source:
Context Engineering for AI Agents: Lessons from Building Manus



