Elon Musk 公開「世界模型」計畫:要讓 AI 學會理解現實
這週的 AI 世界有點像同時在玩模擬城市和真人實境秀: Elon Musk 打造能「理解現實」的世界模型,要讓 AI 自己生成遊戲與物理邏輯; 高雄的 TTXC 大會則讓文化與科技在駁二碰撞出新的創作場景; Google 推出 Gemini 2.5 Computer Use,AI 能直接「動手」操控你的電腦; Sora App 五天破百萬下載,App Store 馬上被假索拉灌爆; 而牛津路透報告顯示,AI 使用率翻倍,但讀者對 AI 新聞的信任卻持續下滑。


週末我在 X 上看到美圖創辦人吳欣鴻的一場內部演講,感觸很深。他先是舉出了一些讓人既熟悉又無力的場景(當然不是指我們,只是讓我想起前公司了 XD ):
需求文件寫得相當漂亮、細節拉好拉滿,PPT 能動是最好,不能動至少矩形要加個光暈在多個凸面,然後開發要花半天時間讀完,讀完啥都聽不懂;
每天泡在會議裡,例會、同步會、複盤會輪番上陣,開了一整天卻什麼都沒決定;
一個小需求要經過層層審批、OA 流轉數十人;
一個創新想法得等到下個季度再排期。
他稱這種現象叫「慣性工作流」——聽起來是流程化,其實是把動能都消耗在這些無意義的瑣事上。於是他們在今年的五月執行了一個名為「RoboNeo」的組織實驗專案,5 月封閉開發,6 月開放內測,7 月正式上線,沒有預算、沒有 PR、也沒有任何外部導流,結果上線首月就突破 百萬 MAU,直接登上多國 Appstore 前十。

在 RoboNeo 的開發過程中,一個人可能同時擔任設計師、文案、營運與測試;
AI 則成為每個人的「共用助手」,幫忙生成素材、測試介面、撰寫文案,甚至進行多語言在地化。從傳統的「依賴流程與分工」轉為「依賴個體與工具」。

當我們在討論 multi-model(多模態)AI 如何整合語言、圖像與行動的同時,「multi-functional 的個體」也正逐漸取代「多職能的團隊」。在 AI 工具足夠成熟的時代,一個人能同時扮演產品、設計、營運與開發,這也許才是 AI 時代最被低估的現象之一 —— 當模型越來越多模態,人也開始變得越來越多功能。
本周焦點事件
- Elon Musk 在打造「世界模型」,先從一款 AI 生的遊戲開始
- 高雄駁二 TTXC ,文化與科技的交會點
- Gemini 2.5 Computer Use:讓 AI 操控你的電腦
- Sora 下載破百萬後,App Store 馬上被冒牌索拉灌爆
- AI 使用率翻倍,但如果用在新聞,讀者可不買單
還想看更多嗎?完整內容只對註冊用戶開放喔!
點下方的免費 Subscribe,馬上加入我們~
Elon Musk 在打造「世界模型」,先從一款 AI 生的遊戲開始

Elon Musk 領軍的 xAI 正式對外揭露下一步計畫:他們正在打造一套能「理解現實」的 AI 系統,稱為 World Models,預計明年底前會釋出一款完全由 AI 生成的遊戲作品做為示範。這不只是遊戲,而是一個能自己生成 3D 世界、模擬物理互動、理解環境邏輯的 AI 模型——類似於大腦中的「世界理解模組」。
根據《Economic Times》報導,xAI 已延攬多位來自 Nvidia 的圖形與模擬技術專家,協助開發這套模擬引擎。雖然我們知道 Elon Musk 很愛玩遊戲,但他的終極目標並不是遊戲本身,而是建立一個「封閉迴路」的生態系:xAI 作為學習世界的認知層(World Models),Tesla 承載物理執行層(車輛、機器人、工廠),兩者將共同組成現實世界的「作業系統」。
這意味著,一旦 World Models 成功,它將不只應用在遊戲與 3D 模擬,更可能成為機器人與自駕車的感知中樞,甚至是未來所有數位與物理世界介面的底層 API。
觀察筆記
xAI world model 的佈局,與其說是為了開發一款 AI 遊戲,更像是在鋪陳一套虛實整合的基礎建設。這項策略與現有主流語言模型的發展方向有顯著差異:後者偏重語意理解與內容生成,或是往 proactive agent 來發展,而前者則是意圖建立一個「可運行、可互動、具備物理邏輯一致性」的模擬世界。
從功能定位來看,world model 可視為一種 AI 的中介層(middleware),其核心能力不是語言理解,而是對空間、動作、因果關係的掌握。這種能力對於自駕車、機器人、AR/VR、邊緣設備乃至於工業自動化等領域,都是 AI 進入真實世界的先決條件。
與其說 xAI 正在打造一款遊戲,不如說他們選擇了遊戲作為訓練「可解釋、可驗證」認知模型的沙盒場所,跟 Nvidia 推出的 Cosmos 還有 DeepMind 先前發布的幾個世界模型相同。相比語言模型缺乏 ground truth 的問題,遊戲世界提供了封閉但具邏輯性的規則,有助於訓練 AI 理解因果關係、空間結構與動態回饋。這也是許多 AGI 專案選擇以 Minecraft、GTA、模擬飛行等環境作為訓練場域的原因。
若進一步將 xAI 放回 Elon Musk 一貫的畫餅邏輯中,會發現這不只是一項產品策略,而是延續他「閉環 AI 生態系」的關鍵節點:xAI 提供 world model 作為認知層、Tesla 與 Optimus 機器人作為執行層、Starlink 與 SpaceX 提供感測與運輸層。這不是單點突破,而是試圖從軟體到硬體、從模擬到部署,打造一套 reality stack,也不知道是不是我過分解讀,但反正我是起了雞皮疙瘩。
外界對 Elon Musk 最大的誤判,往往不是高估他畫的大餅,而是低估他把這些餅做出來的可能性。從火箭回收到電動車革命到超高速運輸,這些基本上只能在科幻小說裡面看到的情節,都被他一一實踐出來了。World Models 是否成為下一個標準尚難定論,但如果它成功,將不只重構模擬產業,還可能成為實體 AI 落地的中央大腦。
TTXC 在高雄駁二,文化與科技的交會點

近年來,「文化 × 科技」這個詞出現的頻率大概和「AI × 產業」一樣多,但同樣存在一個問題:很多人聽到時會覺得抽象。這也是為什麼我特別關注即將在高雄舉辦的 2025 TTXC 台灣文化科技大會。這場活動並不是單純的展覽,而是嘗試為文化與科技的結合下出一個更具體的定義。
整體來看,TTXC 大會的結構可以分成四個部分:國際研討會、高雄電影節、XR DREAMLAND,以及文策院主導的 INNOVATIONS。
第一是 展覽。TTXC 今年設置了兩大展區——【XR DREAMLAND】與【INNOVATIONS】。前者從高雄電影節發展而來,歷經多年已成為亞洲規模最大的 XR 展覽,集結 35 部國際作品;後者則是文化內容策進院主導的策展,展示近 70 件台灣原創與跨界作品。這個設計的目的很清楚:一邊讓你看到世界最前沿的沉浸式內容,一邊展示本地創作者的能量。
第二是 議題。四大核心主題——影視特效、沉浸式內容、IP 應用娛樂、創新場域營運——其實正好對應了產業目前的關鍵痛點與發展機會。研討會的設計並不是純粹討論,而是拉來實際在這些領域有深厚經驗的人,把案例放到台灣觀眾眼前。
第三是 實驗。這裡的實驗不是技術 demo,而是跨領域的「想像測試」。像是文策院主導的 INNOVATIONS 展區,展出許多由政府投資與補助計畫支持下誕生的跨域成果,例如《快樂的陰影》《妖怪森林》等,或 XR DREAMLAND 展出的高雄原創 VR 與文化黑潮計畫作品。
為什麼值得你注意?

如果你對影視、動畫或沉浸式內容的未來有興趣,這一場「虛擬製作新勢力」的組合幾乎是夢幻等級。這不只是一場講座,而是一場由四個產業關鍵角色共同展開的時代對話。
我對謝安的印象非常深——投行背景的他,在二十多歲就成為 數字王國(Digital Domain)CEO,帶領團隊承接《復仇者聯盟》《鐵達尼號》等好萊塢大片的視覺特效。這次他代表 Wētā FX(《魔戒》《阿凡達》的幕後團隊)登台,等於直接把世界頂尖的虛擬製作 know-how 帶進台灣。
另一位講者 馬萬鈞博士 也很特別,他橫跨學術與娛樂兩個世界,從南加大創意科技中心一路做到 Meta Platforms 研究員,過去參與過《哈比人三部曲》《玩命關頭7》《決戰猩球》等動態捕捉專案。他會談的主題之一,就是 AI 如何整合臉部動畫與動作捕捉,把演員與數位角色的邊界變得模糊。
而韓國的 Daniel SON 則代表另一個方向——如何用虛擬製作與 AI 讓戲劇產業規模化。他是韓國 VFX 第一代監製,曾參與《Sweet Home》《殭屍校園》《破墓》等影集,是把韓國影視後製推向國際的關鍵人物。
最後的主持人 林家齊,其實是我特別想提的名字。
如果你對 3D 動畫或虛擬攝影棚有研究,一定聽過他創辦的 夢想動畫(Moonshine Animation)——幾乎是台灣影視業界公認的高品質團隊。我第一次認識他們,是透過台灣結合區塊鏈打造 IP 的《Elysium Shell》前導片,那支作品的細節與渲染質感,讓我第一次意識到原來台灣的動畫公司也能做到這個水準。
為什麼值得你去?
我認為 TTXC 的價值在於,它不是單純的展示,而是一個「價值結構」的縮影。展覽顯示了內容與技術的產出;議題呈現了產業鏈上下游的連結;跨界活動則是一次「文化如何落地」的演練。
如果我們把文化科技當成一個生態系,TTXC 其實就是一次全貌的 mapping:
- 誰是合作夥伴?(國際影展、IP 授權商、科技公司)
- 什麼是價值元素?(沉浸體驗、IP 授權、品牌互動)
- 價值結構如何串起?(從內容生產 → 技術工具 → 消費體驗)
而更關鍵的問題是:台灣能不能在這個結構裡找到自己的位置?
對讀者而言,這場大會值得你親自去參與,不只是「看展」,而是去思考自己在這個文化科技生態系裡能扮演什麼角色——創作者、投資人、經營者,或是下一個跨界的實驗者。
活動名稱: 2025 TTXC 台灣文化科技大會
主辦單位: 文化部、高雄市政府
活動時間: 2025/10/10 - 10/26
活動地點: 高雄 駁二藝術特區
🔗 官網|http://ttxc.tw
📘 Facebook|https://www.facebook.com/ttxc.expo
📸 Instagram|https://www.instagram.com/ttxc.expo
Gemini 2.5 Computer Use:讓 AI 操控你的電腦

Google 近日釋出 Gemini 2.5 Computer Use 預覽版,這是一套具備「使用電腦」能力的多模態 AI 模型,支援透過 API 控制瀏覽器與應用程式,能自動點擊按鈕、填寫表單、輸入文字,完成特定操作流程。
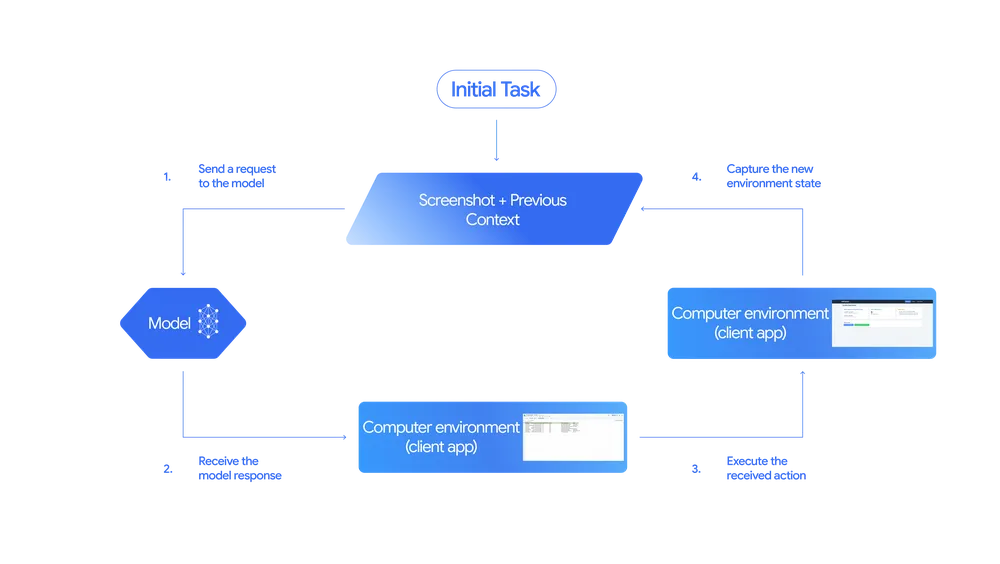
這套系統的運作方式是:AI 模型能根據螢幕截圖 + 上下文,判斷該做什麼動作,並在實體電腦環境中執行這個動作,然後根據新的畫面狀態進行下一步判斷。整體邏輯與人類使用電腦的方式相當類似。
所以從上面圖可以看到有幾個關鍵的節點,分別是:
- Initial Task:任務啟動
使用者或應用程式發出初始任務(如:幫我登入 Gmail),系統截取當前畫面(screenshot)並搭配先前的上下文(previous context)作為模型的輸入 - Send to Model:傳送給 AI 模型
這些資訊被送入 Gemini 模型,模型會根據畫面理解(Visual Understanding)與任務邏輯,產生下一步操作建議(例如:點選「登入」按鈕、輸入帳號)。 - Execute Action:執行操作
這個指令被傳給實際的「client app」,也就是模擬人類操作的使用環境。模型會像人一樣在螢幕上點擊、滑動、輸入,而不是用後端 API 去直接傳參數。 - New State Captured:回饋新的畫面狀態
完成操作後,系統再次截圖,取得當前的新畫面狀態,並將它回傳模型,進行下一輪推理。如此重複進行直到任務完成,形成一個封閉式的控制系統。
根據測試,Gemini 2.5 的表現超越 OpenAI 的 Computer Use Agent 與 Claude 4.5,在 Web 和 Mobile 任務上均取得最高精度與最低延遲,也被證實是 Google 內部 Project Mariner 與 AI 模式功能的基礎引擎。這項技術目前仍在開發者預覽階段,但已展現出極高的商用潛力。
觀察筆記
在技術架構上,Gemini 2.5 Computer Use 採取的是「感知-決策-執行-回饋」的封閉控制環路。從螢幕截圖獲取狀態、送入模型進行推理、再將動作回傳給電腦環境執行,並根據畫面變化進入下一輪推理——這種設計本質上就是一個最小閉環的 agent 架構。
大概在去年年初,我們曾做過一支關於 Claude Computer Use 的影片,實測它在網頁環境中自動填寫表單與查詢資訊、自行操作 Figma 還有上網搜尋某個物件的簡單任務。遺憾的是 Gemini 整體的流程與 Claude 並沒有太大差異——唯一的差別是,模型的能力已今非昔比。
另外有一點值得提的是 Google 本身就掌握前端開發與瀏覽器生態的基礎,因此能把這套流程變得更加順暢、模組化。但從使用者的體感來說,這仍然是一種「直線式的自動化」——你給任務,模型一個步驟一個步驟幫你完成,就像讓 AI 幫你設計一條 Power Automate 或 Zapier 的流程,只是這次它能直接靠螢幕畫面完成。
也因此,這一波 Computer Use 模型的突破,與其說是「讓 AI 更聰明」,不如說是「讓 AI 更通用」。它不需要等待網站開放 API、不需要企業花錢做整合,只要有螢幕畫面,它就能介入並自動化你的操作。
Sora 下載破百萬後,App Store 馬上被冒牌索拉灌爆

OpenAI 的影片生成模型 Sora 2 自上線以來話題不斷,在不到五天內 App 下載數突破百萬,同時有超過 30% 的下載用戶在第一天就成為活躍使用者。但在官方還在「邀請制」階段時,大量假冒應用程式已搶先佔領了 Apple App Store。
根據《TechCrunch》報導,這些仿冒 App 使用像是「Sora」與「Sora 2」等關鍵字,外觀模仿 OpenAI 官方設計,並宣稱具備 AI 影片生成功能,但實際上只是改了 logo、套殼的舊應用,甚至有的直接套用過去生成圖片的模板。
這些 App 搶下「Sora」關鍵字搜尋榜首,甚至有兩款一度擠進 App Store 總榜 Top 10。與官方僅限邀請使用不同,這些應用可直接下載,並內建付費訂閱機制,有些甚至在下架前就已累積數千筆訂閱收入。
目前 Apple 已將大部分仿冒品下架,但也再度引發外界質疑其 App Review 機制的審核標準,包含放行未授權商標、允許虛假 AI 功能等問題。
AI 使用率翻倍,但如果用在新聞,讀者可不買單
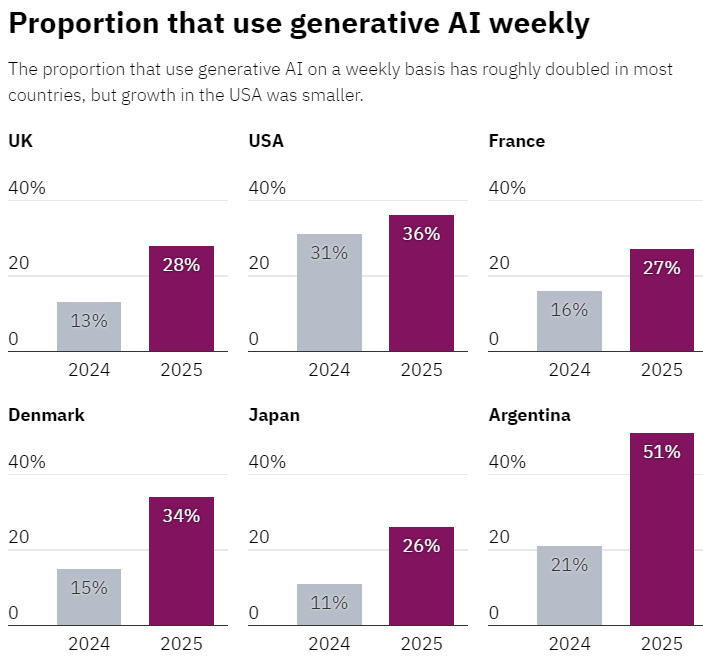
根據牛津大學路透新聞研究所(Reuters Institute)最新發布的《Generative AI and the News Report 2025》,AI 工具在六個國家的使用情況已大幅攀升,尤其在搜尋資訊、回答問題等任務上尤為顯著。報告指出,每週使用 AI 工具的人口比例幾乎翻倍,但針對 AI 在新聞產製的應用,大眾的信任度不升反降,新聞業反而成了最敏感的使用場域。
在使用習慣方面,有 24% 的受訪者表示用 AI 來「查資料與問問題」,已超過 21% 的「生成內容」用途(如寫作、作圖、寫程式)。ChatGPT 仍是最常被使用的平台,而 Google 與 Microsoft 將 AI 整合進搜尋引擎後,也讓 54% 的受訪者在不知不覺中接觸到 AI 產生的摘要資訊。
但當 AI 被用來產製新聞時,使用者態度明顯轉向保守。只有 12% 的受訪者表示可以接受「完全由 AI 撰寫的新聞內容」,高達 62% 則明確偏好「完全由人類撰寫的新聞」。信任落差與去年相比進一步擴大,且對 AI 用於政治報導的疑慮也持續升溫。
觀察筆記
我對這篇報告最感興趣的不是大家用多少 AI、在哪些情境下用,而是那句被大量引用的結論:高達 62% 的受訪者偏好「完全由人類撰寫的新聞內容」——他們又怎麼知道哪些新聞是由 AI 寫的?
這是這份報告裡最矛盾的地方:一邊調查大家對 AI 產製新聞的信任程度,一邊卻沒有明確說明——使用者是否真的能分辨?報告中雖然有提到「標示」與「透明化」是建構信任的關鍵手段,但並沒有進一步說明受訪者是在什麼資訊背景下做出這個判斷的。
這對媒體而言是一個很難解的問題。假如 AI 真的能生成足夠清晰、準確、無偏的新聞稿件,那麼讓讀者知道背後是 AI,是在增加透明度,還是在降低信任感?也許未來的媒體工作不是選擇「要不要用 AI」,而是選擇「要不要讓人知道你用 AI」,如果是我們的話,肯定是有用的,但 AI 的比例不超過 40 %,不然我怕我變笨。
喜歡這期內容嗎?有哪一則讓你特別有感?
歡迎回信或是 Instagram 告訴我們,我們會偷偷讀大家的回覆的!
我們下周見
—AI郵報 編輯團隊



