Google 發布 DS-STAR:能自動寫程式、分析研究數據、繪圖與制表的最強多功能資料科學 Agent
Google 推出 DS-STAR,開啟 AI 自動化資料科學新時代。

DS-STAR 是什麼?
Google Cloud 研究團隊近日推出 DS-STAR(Data Science – Sequential Task-Action Reasoner),一個能夠自動完成整個資料科學流程的多智能體 AI 系統。它能理解自然語言指令、撰寫 Python 程式、進行資料清理、建模與視覺化分析,並能自我驗證結果是否合理。
不同於以往只能處理表格資料的 AI 工具,DS-STAR 能同時處理 CSV、JSON、文字檔、Markdown 等多格式資料,讓非技術背景的使用者也能用一句話完成完整的數據分析任務。
這項突破標誌著資料科學自動化邁向新階段——未來或許不再需要工程師手動寫程式來跑分析,AI 將能成為「自我審查、可重複驗證」的資料研究夥伴。
為何 Google 要開發 DS-STAR?
在真實世界的資料科學任務中,從資料清理到結果驗證往往需要多個步驟與專業知識。典型流程包括:
- 整理與清洗原始資料(Data Wrangling)
- 移除重複值與格式化數據
- 建立統計或機器學習模型
- 繪製圖表呈現趨勢
- 驗證分析結果的可靠性
過去,這些工作都仰賴人工撰寫程式、除錯與人工驗證,過程不僅耗時,也容易出錯。
Google 研究團隊希望藉由 大型語言模型(LLM) 的推理能力,讓 AI 能以自然語言指令自動完成這些任務,例如:
「請幫我分析這些銷售紀錄,找出每月的成長趨勢,並畫成圖表。」
DS-STAR 三大技術創新
Data File Analyzer:資料檔案分析員
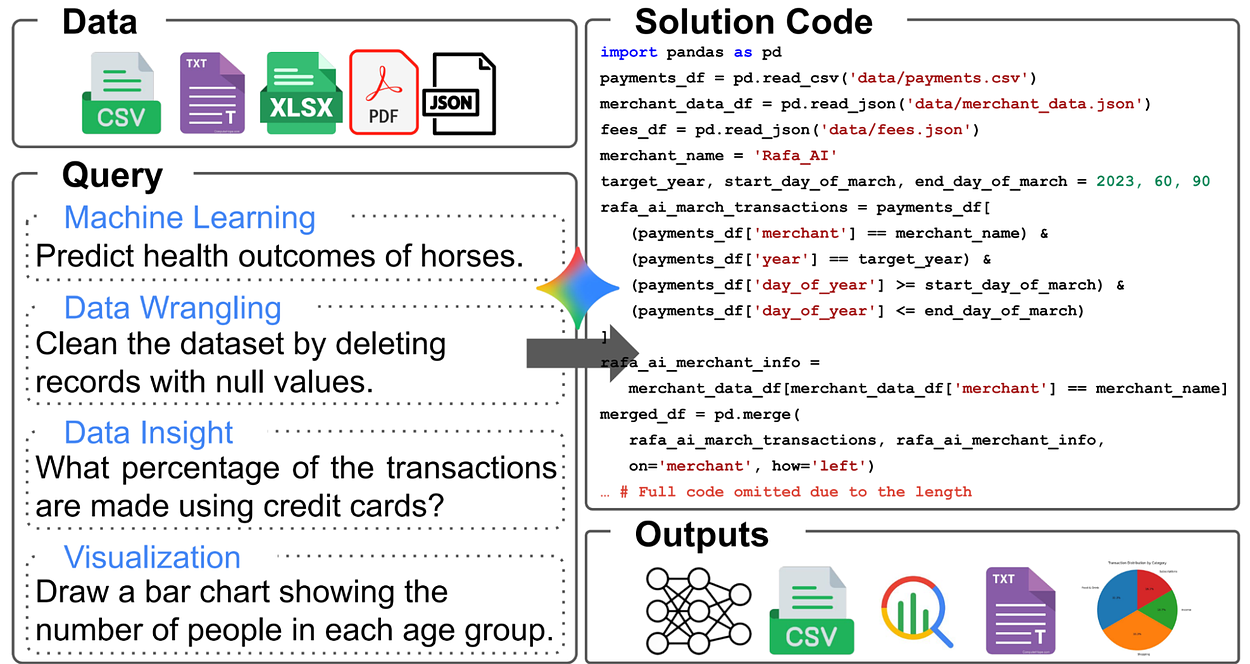
DS-STAR 的第一個模組會自動掃描資料夾中的所有檔案,不論格式為 CSV、JSON、TXT 或 Markdown,皆能理解其結構與關聯。
舉例來說,它能自動生成一份「資料地圖」:
「File A 包含用戶購買紀錄、File B 為商品描述、File C 為行銷活動日誌。」
透過這種預處理,AI 不再需要人類額外解釋資料來源與邏輯關係,大幅提升自動分析的正確率。

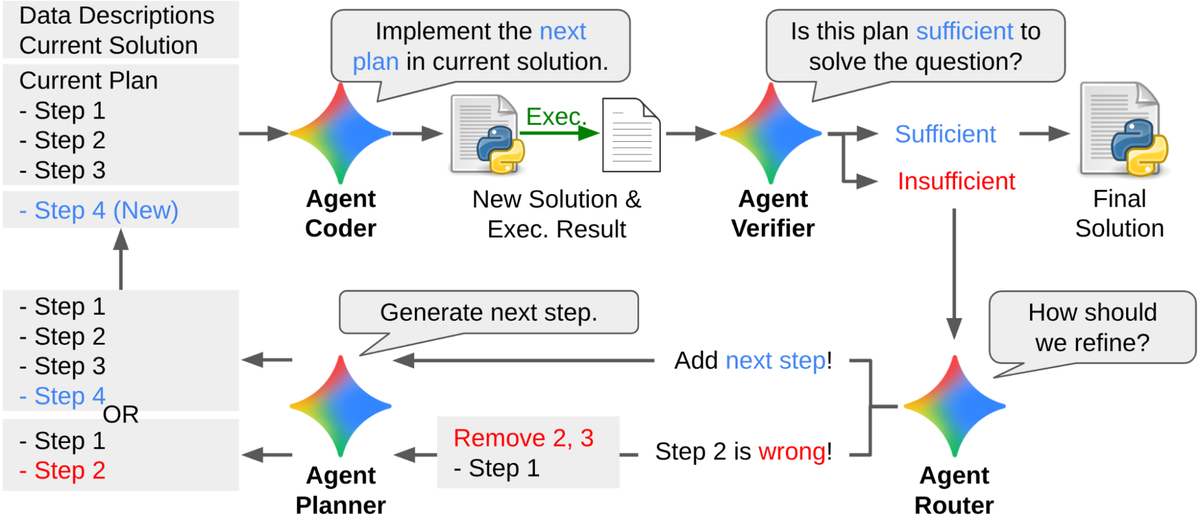
Planner、Coder、Verifier、Router 四智能體協作
這四個角色構成 DS-STAR 的核心工作流程:
- Planner:擬定整體分析計畫
- Coder:撰寫並執行 Python 程式
- Verifier:審核結果是否合理
- Router:決定是否修改策略或重新嘗試
整個過程模擬一個專業數據團隊的互動,系統會自動重複這一循環最多十次,直到 Verifier 判斷結果滿意為止。
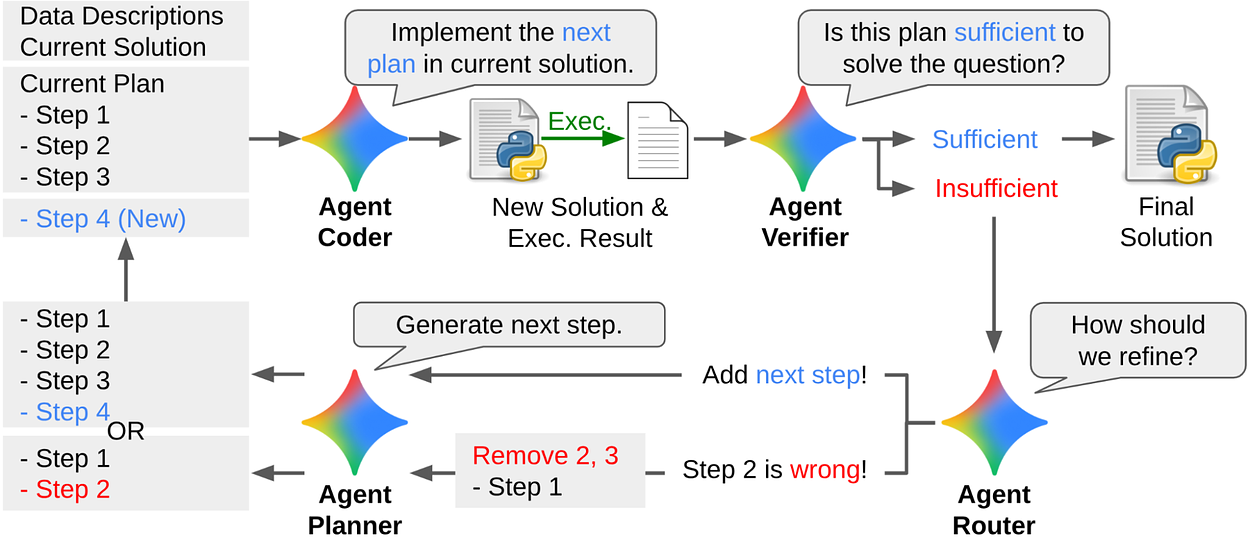
這讓 DS-STAR 成為真正能「邊學邊修正」的 AI 科學家,而非一次性輸出答案的模型。
Iterative Sequential Planning:迭代順序規劃
傳統 AI 系統通常一次輸出答案,若錯誤便無法自我修正。
DS-STAR 引入「迭代順序規劃」機制,模仿人類使用 Jupyter Notebook 的習慣:
嘗試 → 查看結果 → 再調整策略。
這種逐步改進的設計使其能動態優化每次分析步驟,最終生成更準確的報告與可視化圖表。
工作流程概覽
- 讀取資料目錄
- Data File Analyzer 建立資料結構摘要
- Planner 擬定分析步驟
- Coder 撰寫並執行代碼
- Verifier 檢查結果合理性
- Router 決定是否重新規劃
- 輸出最終結果:包含表格、圖表或報告
這樣的多層設計讓 DS-STAR 具備「可理解 + 可修正 + 可驗證」的閉環能力。
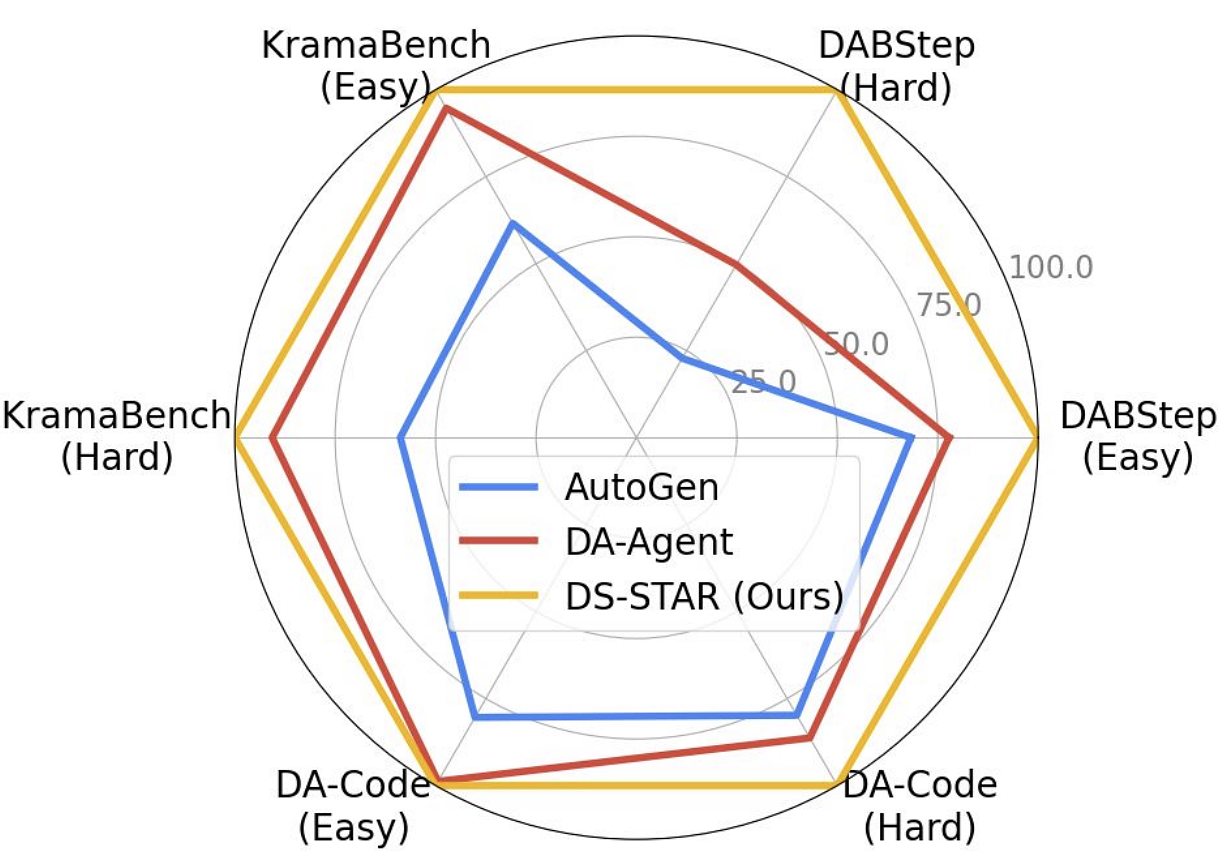
DS-STAR 的實驗結果
Google 研究團隊在三項權威資料科學基準測試中對 DS-STAR 進行評估,結果顯示它在多文件、複雜資料分析任務上表現最為出色。
截至 2025 年 9 月 18 日,DS-STAR 在 DABStep 榜單 上排名第一,成為目前全球最強的自動化資料科學 Agent。
平均迭代輪次統計
- 簡單任務:平均 3.0 輪完成
- 複雜任務:平均 5.6 輪完成
- 超過一半的簡單任務僅需 1 輪即可解決
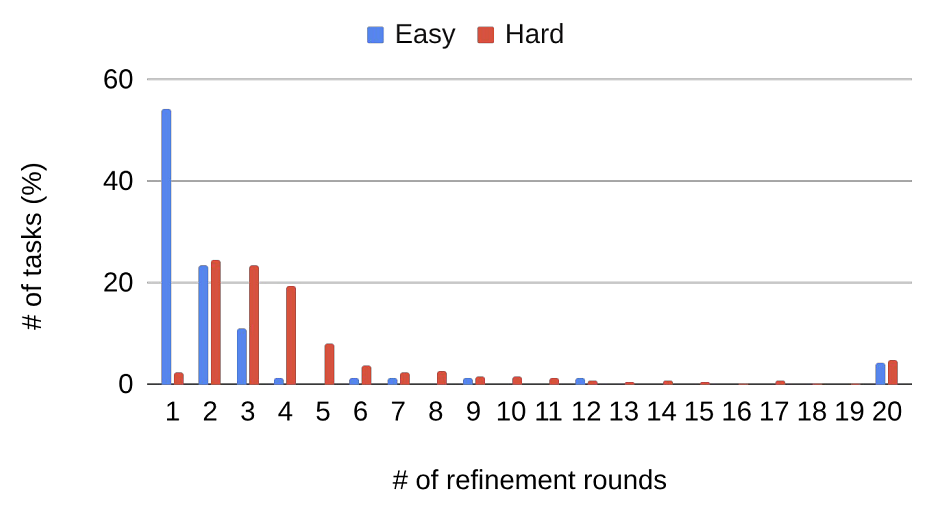
這意味著 DS-STAR 不僅能快速完成初級任務,也能在多輪自我修正後穩定處理複雜問題。
模組消融實驗
研究團隊進一步進行「拆件測試」以驗證各模組的重要性。
結果顯示:
- 移除 Verifier 後,結果準確率顯著下降;
- 缺乏 Router 的版本無法完成多步任務;
- 不同 LLM(如 Gemini、Claude、GPT-4)皆能在 DS-STAR 架構中運行,顯示其架構具高度通用性。
為何 DS-STAR 重要?
降低門檻
它讓非技術背景的使用者也能完成專業資料分析,開啟「無程式碼資料科學」時代。
提高效率
過去需要數小時的人工作業,如今可能在幾分鐘內完成。
推動研究革新
DS-STAR 的「多智能體協作 + 自我驗證」設計,為未來 AI 系統帶來新範式:
不再依賴單一模型輸出,而是多角色互補、持續自查的協作體系。
應用前景與未來展望
Google 表示,DS-STAR 的應用潛力橫跨產業與教育:
- 商業智能(BI)工具:自動生成報表與趨勢分析
- 科研助手:自動化數據實驗與結果驗證
- 教育應用:成為學生學習資料科學的 AI 導師
未來,DS-STAR 或將整合至 Google Cloud 生態系,成為企業數據分析的核心 AI 基礎模組,與 BigQuery、Vertex AI 等工具互補。
結語
DS-STAR 不只是「會寫程式的 AI」,它標誌著資料科學正式進入「自動推理 + 多智能體」時代。
在這個新架構下,AI 不再是輔助工具,而是能主導整個分析過程的「虛擬研究員」。
當自檢、自修、可解釋成為主流,資料科學家的角色也將逐漸轉型為決策與創造力的發揮者。



