Google 解決 AI 災難性遺忘問題:Nested Learning 讓 AI 擁有長期記憶能力
Google 用嵌套學習解決AI遺忘難題,讓模型擁有長期記憶。

什麼是「災難性遺忘」?AI 的記憶困境
人工智慧在學習新任務時,往往會遺忘先前的知識,這種現象被稱為 「災難性遺忘(Catastrophic Forgetting)」。
舉例來說,若一個語言模型先接受英文寫作訓練,再學習程式設計,雖然它的程式能力提升了,卻可能導致英文表達能力下降。這說明模型缺乏「持續學習(Continual Learning)」能力——無法在吸收新資訊的同時,維持舊知識的穩定。
過去的解法如「凍結部分參數」或「正則化權重」只是權宜之計,並未真正模擬人類大腦能同時記憶、更新與遺忘的動態平衡。
Google Research 的最新突破——Nested Learning(嵌套學習),正是為了解決這個根本問題,讓 AI 能像人腦一樣長期學習、穩定記憶、靈活適應。
靈感來自人腦:多時間尺度的學習
人腦透過 Neuroplasticity(神經可塑性) 實現學習。不同神經連結在不同速度上變化:
- 有些連結變化快,負責短期記憶與反應;
- 有些變化慢,負責長期知識的穩定儲存。
這種「多時間尺度的更新機制」讓人類能在學習新事物時不忘舊知。Google 的目標是讓 AI 模型也具備這樣的多層次結構:
同時存在快速、適中與緩慢三種節奏的學習層,像人腦一樣在不同頻率上協同運作。
Nested Learning 的核心理念:多層學習系統
傳統深度學習將「模型架構」與「優化器(Optimizer)」視為兩個分離的部分,而 Google 的 Nested Learning 將兩者融合,提出一個嶄新的觀點:
「模型本身就是一組嵌套的學習過程(Nested Learners)。」
也就是說,一個 AI 模型不再是單一學習體,而是一組具有不同學習速度的小學習系統:
- 高頻層(Fast Layer):快速更新,負責短期記憶。
- 中頻層(Medium Layer):整合知識、適應情境變化。
- 低頻層(Slow Layer):穩定長期記憶,防止舊知識流失。

這三層形成像「洋蔥」般的結構:外層快速反應、內層緩慢學習,整體共同維持模型的記憶連續性。
技術細節與創新機制
Architecture = Optimization Rule
Google 提出革命性假設:
模型架構與優化算法其實是一體的,只是位於不同嵌套層級上。
Transformer 的注意力機制(Attention)與 Adam、SGD 等優化器本質上都是「學習規則」,只是作用節奏不同。Nested Learning 統一這兩者,建立一種「層級式自學優化體系」,讓模型在不同時間尺度上同步學習。
Context Flow(上下文流)
每一層都有獨立的資訊通道,稱為 Context Flow。
它定義了該層要處理的資訊範圍與學習時間跨度。
Nested Learning 讓這些通道之間動態互通,從而形成穩定而靈活的知識整合機制。模型能根據任務需求,自動調整學習節奏。
Multi-time-scale Updates(多時間尺度更新)
這是 Nested Learning 的關鍵所在。
在傳統訓練中,所有參數的更新頻率一致;但在 Nested Learning 架構下,不同層的參數更新頻率不同:
- 高頻層:每步更新一次,用於快速適應新任務。
- 中頻層:每個批次更新一次,用於整合近期知識。
- 低頻層:每數千步更新一次,用於保留長期穩定知識。
這與人腦記憶的轉換過程極為相似——短期記憶在海馬體形成,再逐漸轉化為大腦皮層中的長期記憶。
Associative Memory(關聯記憶機制)
Nested Learning 將傳統反向傳播(Backpropagation)重新詮釋為一種「記憶映射過程」。
模型不只是學數據本身,而是學習「數據與錯誤之間的關聯」。
這與人腦的「驚訝機制(Surprise-based Memory)」類似:人類更容易記住異常或意外事件,而模型也會自動優先記憶誤差大的樣本,形成更具彈性的記憶權重。
Continuum Memory System(CMS,連續記憶系統)
Google 研究團隊進一步提出 CMS,將短期與長期記憶整合為連續的記憶譜系。
在 CMS 中:
- 每個記憶模組有不同的更新頻率;
- 所有模組形成連續的記憶空間;
- 模型能依任務需求,自由訪問不同時間跨度的知識。
這讓 AI 不再「二分」短期與長期記憶,而能在連續時間軸上進行知識調用。
實驗模型:Hope 的誕生
Google 用一個名為 Hope 的實驗模型驗證 Nested Learning 架構。
Hope 能自我修改,並依據任務的「驚訝程度」決定記憶優先順序:當模型遇到前所未見的資訊時,它會主動強化該知識的權重。
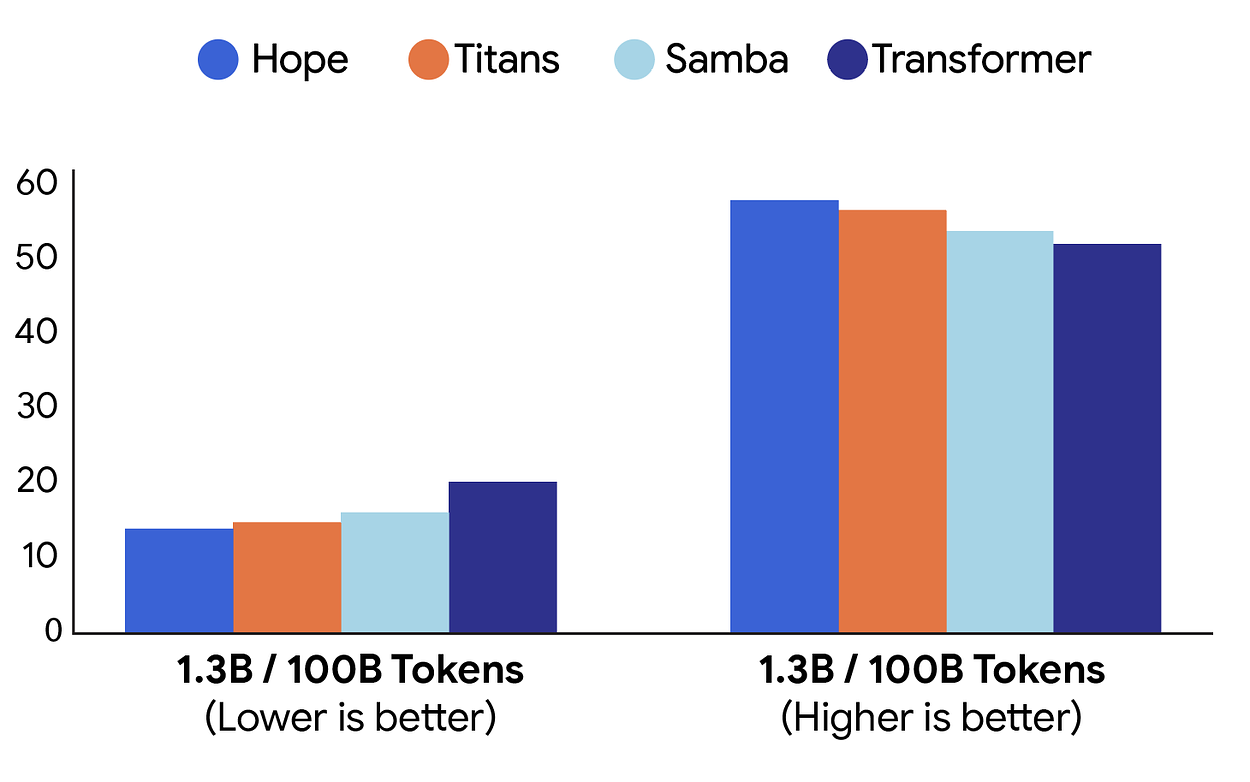
實驗結果顯示
- 在 長上下文推理(Long Context Reasoning) 任務中,Hope 的表現顯著優於所有現有模型。
- 在 知識保留測試 中,Hope 幾乎不會遺忘舊任務內容。
- 在 NIAH(Needle-in-a-Haystack) 任務中,展現出更強的記憶召回能力。
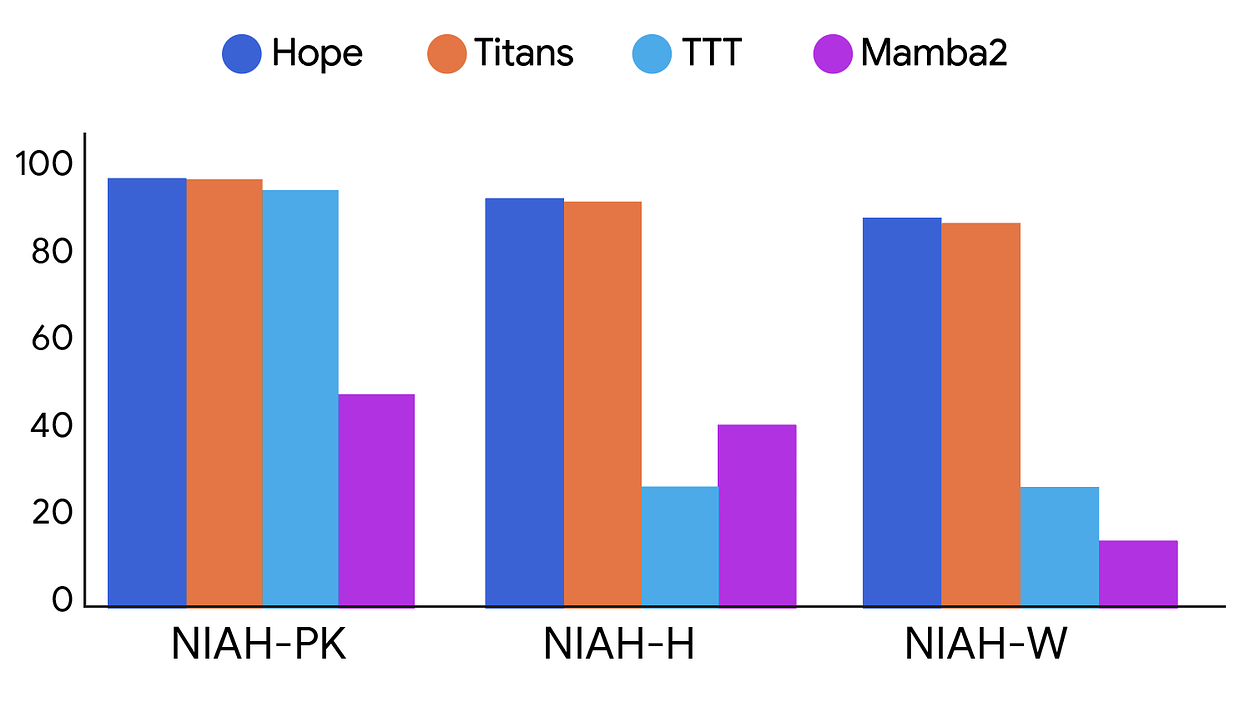
這證實了 CMS 結構與多層學習節奏能有效減少遺忘,並增強 AI 的長期記憶。
為何這項研究意義重大?
持續學習的里程碑
Nested Learning 讓 AI 能像人類一樣「一邊學新、一邊不忘舊」。
這將推動真正的 Continual Learning AI,開啟自我進化與長期知識積累的新紀元。
類人智能的躍進
嵌套學習的架構模擬人腦神經可塑性,讓模型的學習行為更具生物啟發性,是邁向「人工通用智能(AGI)」的重要一步。
自我優化 AI 的雛形
Nested Learning 不僅教 AI 學知識,更教它「如何學習」。
這意味著未來的 AI 可能會自主選擇最適合的學習策略,進一步提升自適應能力。
未來展望
Google 表示,Nested Learning 仍在早期階段,但潛力巨大。未來這項技術可能:
- 讓 AI 具備真正的「長期記憶」而非短暫緩存;
- 支援個性化學習風格與記憶策略;
- 實現能自我修正與優化的持續學習模型。
Nested Learning 不僅是技術創新,更是 AI 認知邏輯的轉變。
它代表著一個新的研究方向:從訓練 AI,到培養能學習的 AI。



