最新 Grok 4 懶人包,全球最強 AI 模型?與 ChatGPT、Claude、Gemini 比較
Grok 4 Heavy 是 Elon Musk 最新推出的 AI 模型,號稱全球最聰明的 AI。本文帶你快速了解 Grok 4 與 Grok Heavy 的功能、性能、Roadmap,以及與 ChatGPT、Claude、Gemini 的全面比較。


昨天,Elon Musk 領軍的 xAI 團隊,正式發布最新 AI 模型 Grok 4 和 Grok 4 Heavy,號稱「全世界最聰明的 AI」。
在由 Scale AI 設立的最新評測標準 Humanity's Last Exam 中,Grok 4 Heavy 拿下領先成績,狠狠甩開 OpenAI、Anthropic、Google 等主流模型,成為智慧能力領先的 AI 之一。
那麼,到底 Grok 4 和 Grok Heavy 憑甚麼被稱作目前世界上最強的 AI 模型?它的實力和 ChatGPT、Claude、Gemini 相比,究竟強在哪裡?接下來就讓我們帶你快速了解。
延伸閱讀:【深度專題】Scale AI 是什麼?是 ChatGPT 訓練的基石?從資料標註新創到 Meta 投資的 AGI 基礎建設者
什麼是 Grok 4、Grok Heavy?功能、影片、Roadmap 一次看懂
這次發布的 Grok 4 系列,分為兩個版本:Grok 4 和 Grok 4 Heavy,兩者架構、定位都不太一樣。
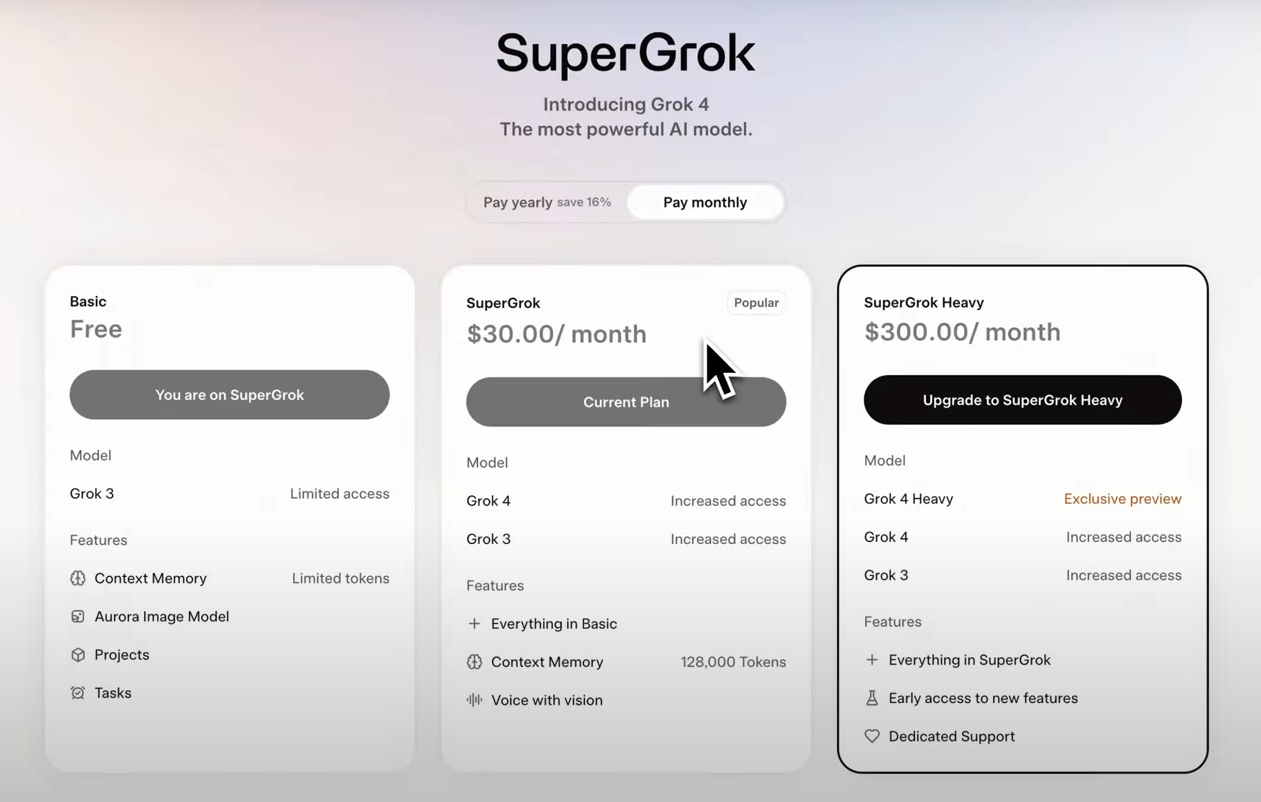
Grok 4 是基礎版,重點在於「單一模型處理多模態任務」,支援文字、圖片、語音、數學推理,適合一般開發者或日常使用。
而 Grok 4 Heavy 則是 xAI 主打的旗艦版,採用 multi-agent 架構,透過多個 AI 協作完成任務,特別針對高難度的邏輯推理、分析任務優化,讓模型不再只是單點作業,而是像一個團隊在合作解題。
Introducing Grok 4, the world's most powerful AI model. Watch the livestream now: https://t.co/59iDX5s2ck
— xAI (@xai) July 10, 2025
而這次 xAI 除了公開 Grok 4 在權威性指標的分數以外,也公開多個 Demo 展示 Grok 的實際應用:
Grok 4 的重點功能與 Demo 展示
1.人類最終試驗!Humanity's Last Exam:目前全球最高分

Humanity’s Last Exam 是由 Scale AI 推出的最新 AI 測試基準,被定位為「人類知識邊界的最後考驗」。這個測試集包含 2,500 題封閉式高難度題目,涵蓋數學、物理、電腦科學、社會科學、醫學、工程等 100 多個學科,專門測試 AI 在邏輯推理、專業知識、跨領域理解等方面的極限能力。
從題目類型來看,數學領域占了最大比例 41%,其次是生物醫學(11%)、電腦科學 / 人工智慧(10%)、物理與社會科學(各 9%)、化學(7%)、工程(4%)等,可說是目前涵蓋範圍最廣、難度最高的 AI 測試之一。
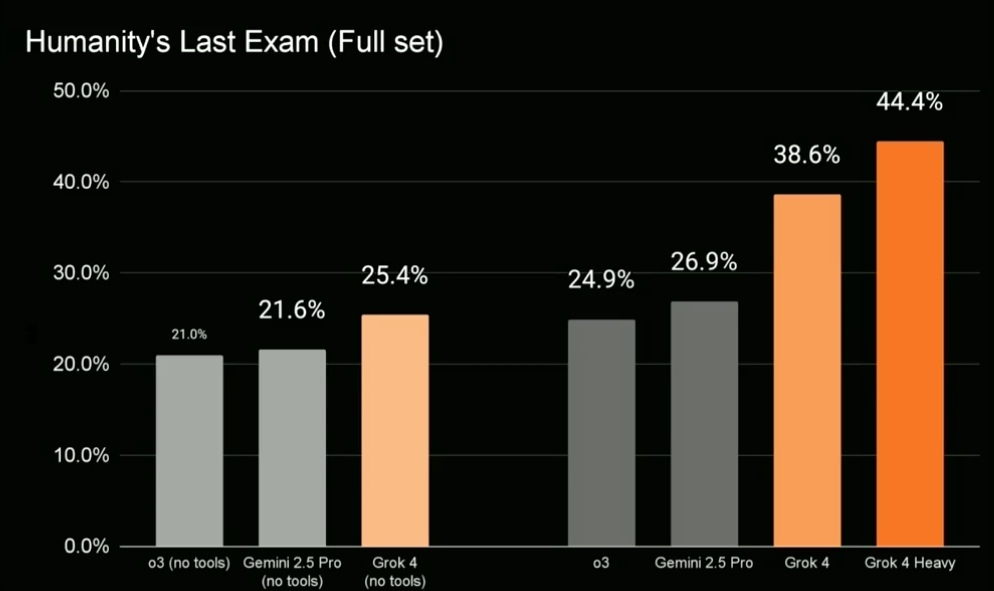
在公布的測試結果中,Grok 4 Heavy 拿下 44.4% 的整體正確率,成為目前公開成績最高的 AI 模型,明顯領先 GPT-4o、Claude 3、Gemini 1.5 等主要對手。
2.Voice Mode(Eve):直接對話、語氣變化,甚至能唱歌

Grok 4 內建的語音功能模組 Eve,能夠支援自然語氣、情緒轉換,甚至可以模擬不同角色的聲音對話。
與 OpenAI GPT-4o 類似,Grok 4 支援即時語音互動,並展示了完整的語音生成 pipeline,不只朗讀文字,而是具備溝通感的對話能力。
特別的是,Eve 還能夠唱歌,展現語音模型的節奏、情感掌控能力。
3.Vending Bench:AI 比人還會賺錢
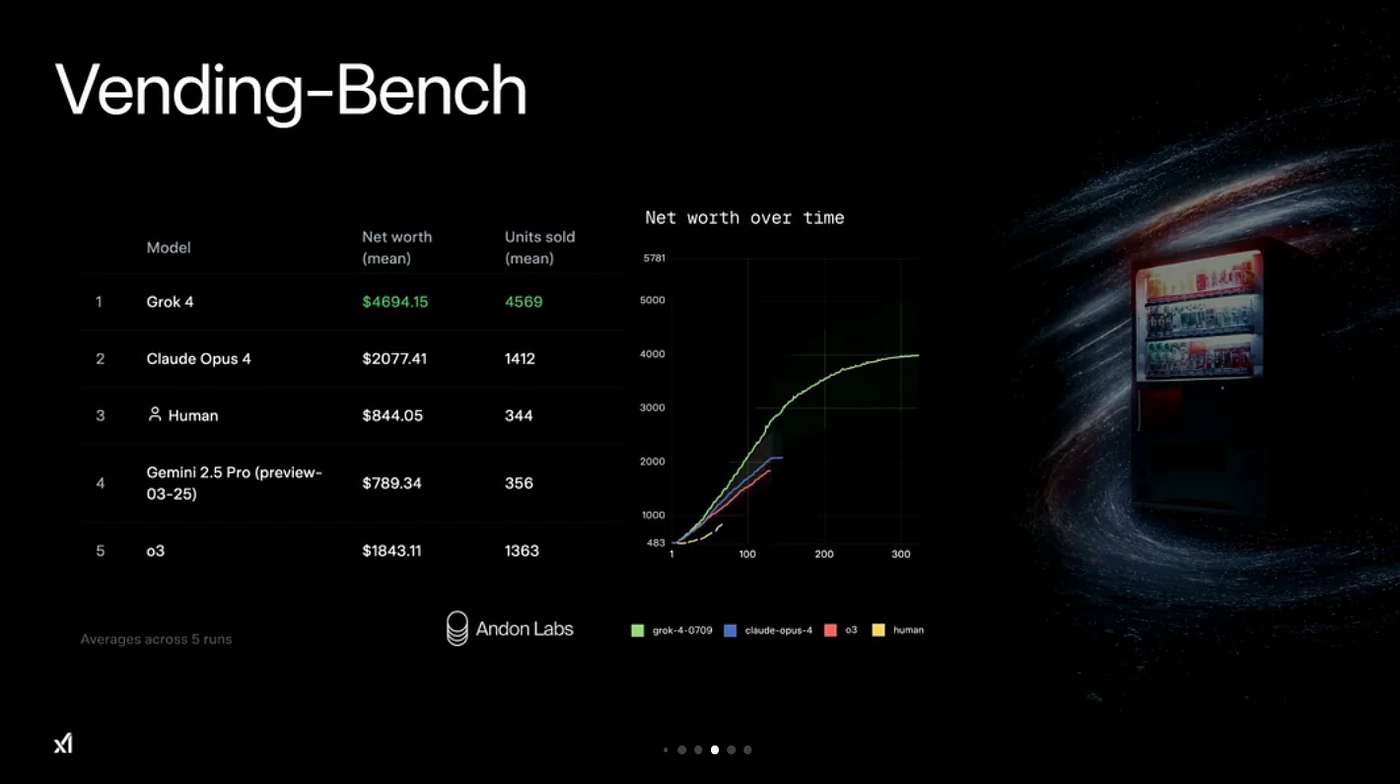
Vending-Bench 是一個模擬販賣機經營的 benchmark 測試,考驗 AI 在真實經濟場景中的決策、需求預測與商品定價能力。模型需要根據銷售狀況、庫存管理、消費者偏好做出最佳決策,類似日常零售經營環境。
在這個測試中,Grok 4 明顯領先其他模型:
- Grok 4 平均淨收益為 $4,694.15,銷售 4,569 件商品
- 遠超 Claude Opus 4 的 $2,077.41,以及 Gemini 2.5 Pro、o3 等模型
- 甚至連人類平均成績($844.05,344 件)也大幅超越
從右側的淨收益成長曲線來看,Grok 4 的表現一路領先,說明它不只會答題,更能在多變的市場情境下持續優化決策,展現了「自主經營」的能力。
這項能力未來有機會應用在智慧零售、商業 AI 決策、甚至遊戲 NPC 經營模擬等領域。
4.黑洞碰撞模擬:從搜尋、建模到繪圖,全程自主完成
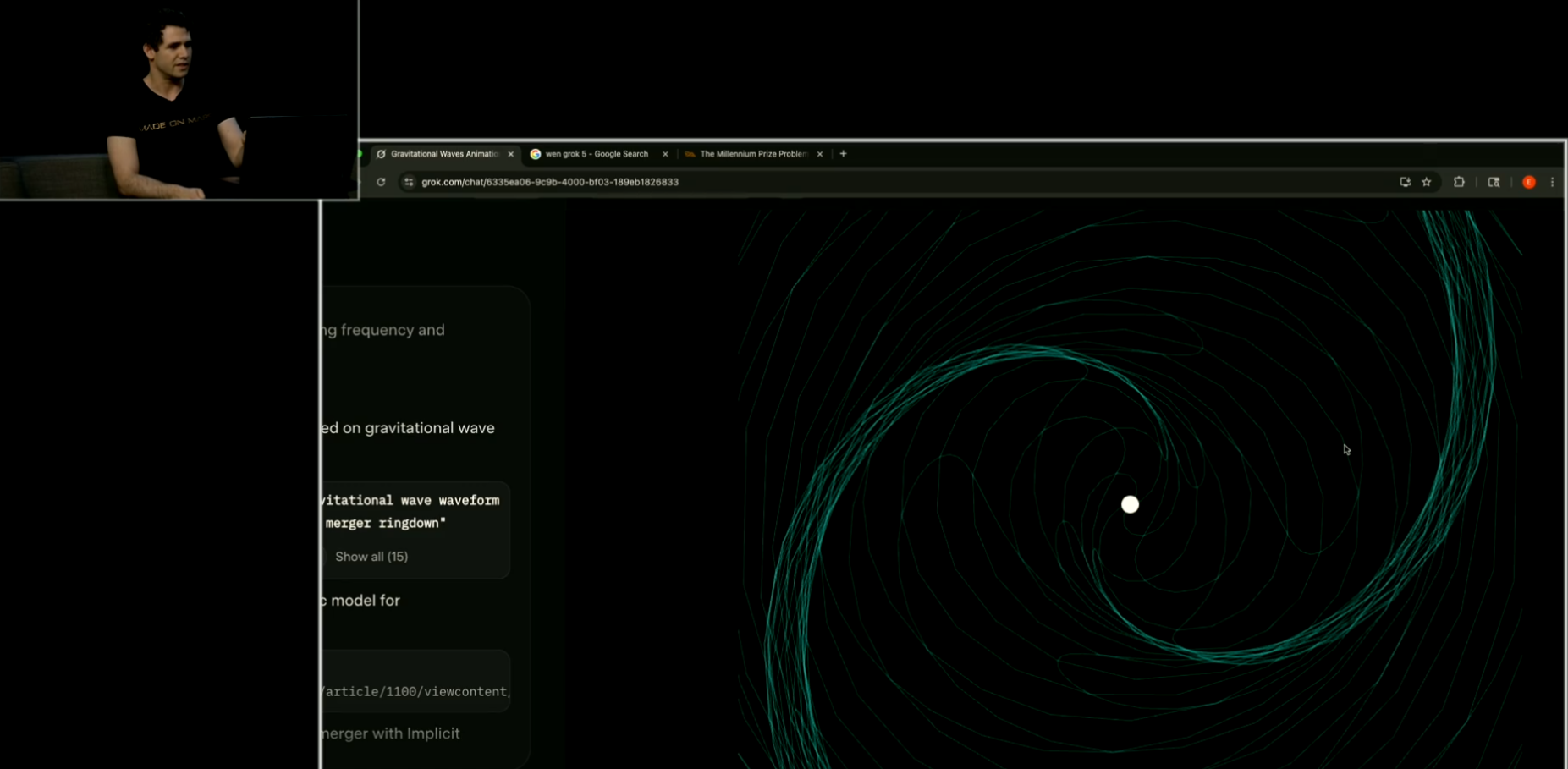
另一個展示 Grok 多模態能力的案例,是「黑洞合併模擬」。這不只是視覺展示,更是結合搜尋、數學建模、程式生成的完整流程。
Grok 4 透過內建搜尋功能,自動找到哈佛、arXiv 等研究資料,理解重力波(gravitational waves)的數學模型,並根據公式產生波形數據。
接著,Grok 直接生成 HTML + JavaScript 程式碼,自行繪製黑洞碰撞產生的重力波動畫,過程中不需要人為介入。
這個 demo 展示 Grok 不只是「理解知識」,而是能從知識 → 程式 → 圖像,跨越不同領域完成複雜任務。
Grok 4 真的最強嗎?數據、實測、AI 社群怎麼看
看了這麼多 demo,不可否認 Grok 4 Heavy 展現了很強的技術實力,但「最聰明的 AI 模型」這個稱號,真的成立嗎?
一個模型的能力,不能只看公開展示,更要看它在各大 benchmark 測試、社群開發者實測,以及真實應用場景裡,是否穩定、全面、可靠。
以下整理目前公開的測試數據與社群評價,帶你更全面了解 Grok 4 Heavy 的實力:
Artificial Analysis:專門評測 Frontier AI 的第三方指標
在官方 benchmark 之外,近年 AI 圈內也開始重視來自第三方的實測平台。其中,Artificial Analysis 是目前開源社群、AI 工程師挑選模型時的重要參考,類似 AI 領域的「性能評測排行榜」。這個平台最大的特色在於:不只看官方數據,而是實際透過 prompt 測試、API 呼叫、輸出速度等面向,進行綜合評估。
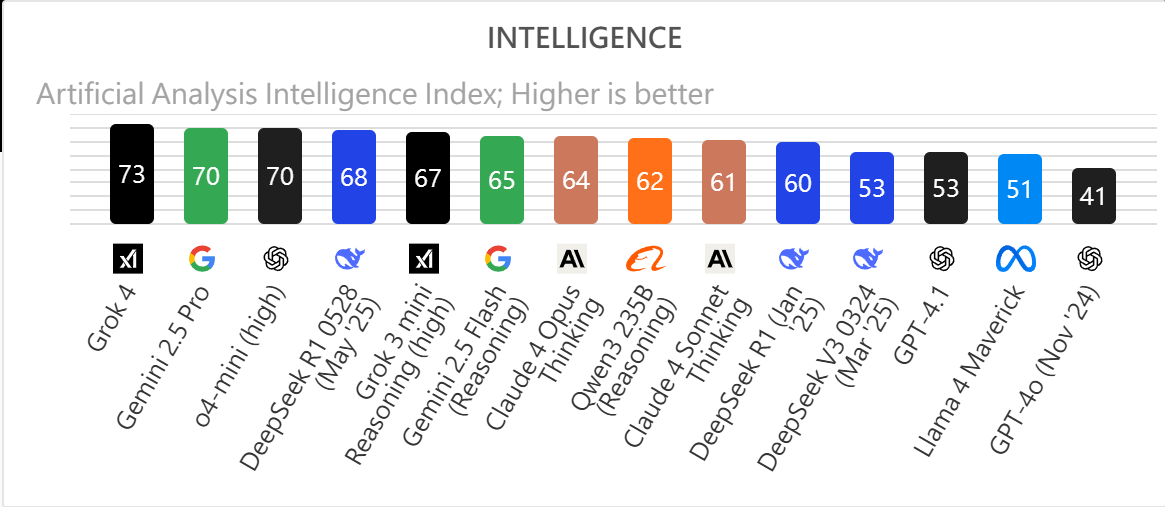
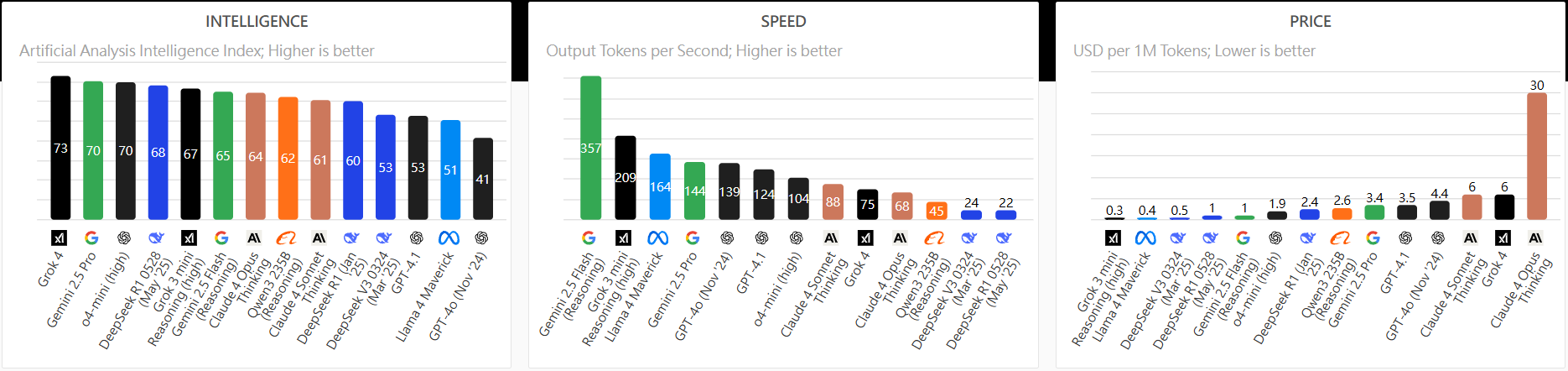
在 Intelligence Index(智慧指數)上,Grok 4 拿下 73 分,是目前評比中最高,領先 Gemini 2.5 Pro(70 分)、OpenAI o4-mini(70 分)、DeepSeek Flash(68 分)等對手。

在每秒輸出 tokens 數量(Output Tokens per Second)上,Grok 4 僅排名中段:明顯慢於 Gemini 2.5 Flash(357 tokens/sec)、Reasoning 3-mini(209 tokens/sec),這是因為 Grok 4 是推理模型,在任何問答情況下都會用到推理,我們實際測試,大約是 ChatGPT 兩倍的時間。
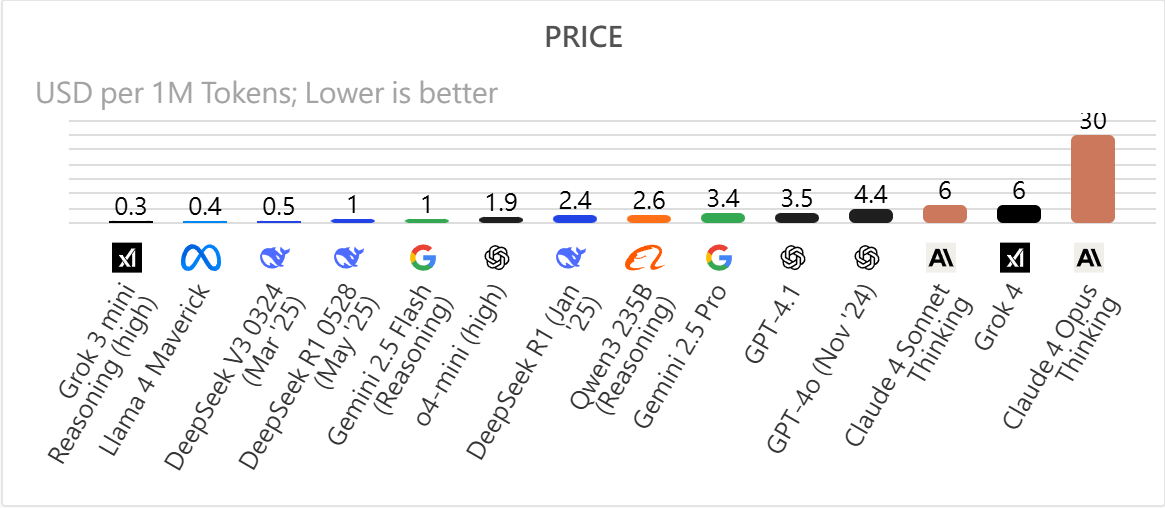
在每百萬 tokens 成本(USD per 1M tokens)上,Grok 4 約 6 美元,與 GPT-4o、Claude 同級,但遠高於 DeepSeek、Llama、Reasoning 這些高性價比模型(最低僅 0.3 美元)。
與 GPT‑4o、Claude、Gemini 比較:整體表現一覽
| 指標 | Grok 4 Heavy | GPT‑4o | Claude 3 Opus | Gemini 1.5 Pro |
|---|---|---|---|---|
| 智慧指數 | 73 | 64 | 65 | 70 |
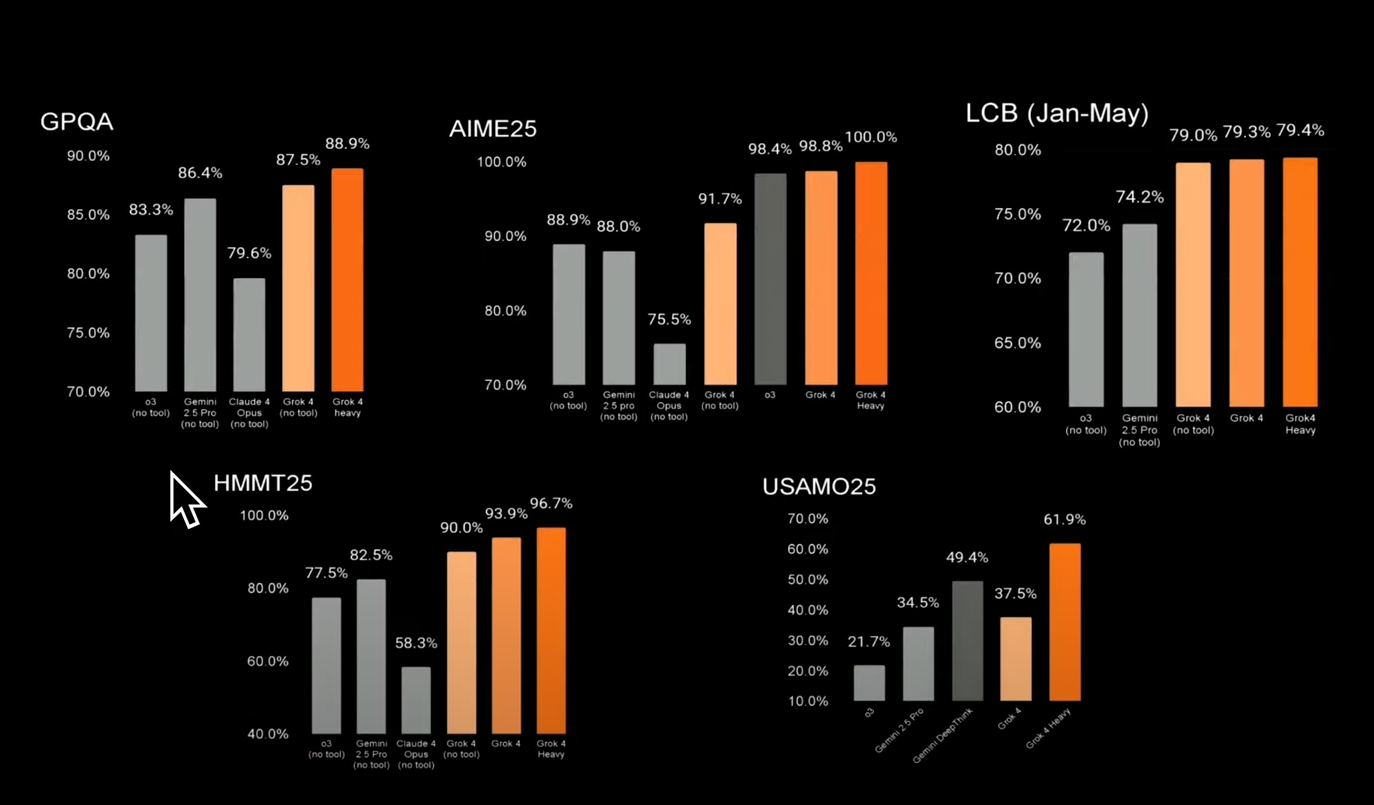
| ARC‑AGI 2(推理考) | 44.4% | 約 35% | 約 25% | 約 24% |
| HumanEval(程式能力) | 領先 | 稍優 | 稍優 | 稍劣 |
| 輸出速度 | 75 | 139 | 75 | 164 |
| context 長度 | 128K | 128K | 200K | 1M |
| 多模態支援 | ✅ | ✅ | ✅ | ✅ |
| 搜尋能力 | Deep Search (X) | Bing | 無 | |
實際使用感受:Grok 很強,但更像是學術派的勝利
以我自己的使用經驗來說,雖然 Grok 4 的確在 benchmark 測試上成績亮眼,但實際用起來,還是有不少限制。
首先是價格與功能範圍:目前 Grok 4 的訂閱價格是每月 30 美元 (高達每月 300 美元的專業版費用,對一般用戶來說偏高。),看似與 GPT-4o Pro、Claude Pro 差不多,但能做到的事比較侷限。它雖然強調邏輯推理能力,但實際日常使用時,不管問什麼問題,它都像是在「認真考慮」,即便只是簡單查詢,也會花比較長的處理時間。
其次是 Coding 能力與生態整合:目前 Grok 的 coding 水準,沒有辦法取代 Claude 的流暢度,或 Codex / GPT-4o 的成熟度;而且在各類工具整合、API 支援、企業應用生態方面,還是 Google Gemini 做得比較完整。
簡單來說,雖然 Grok 4 Heavy 是目前在智慧層級上最強的模型之一,但它的應用場景偏向「學術性」、「高難度任務」,不像 GPT-4o、Claude 那樣適合做為一個隨時可用的全能助理。
Grok 4 適合誰?值不值得訂閱?
xAI 在直播上公布了 Grok 接下來幾個月的產品 Roadmap,包含 8 月的 Coding Model、9 月的 Multi-modal Agent,以及 10 月的 影片生成模型,都是針對實用性大幅升級的功能。

如果你是:
- 喜歡體驗最新 frontier AI 技術,想要了解最前沿的模型能力,可以考慮現在就訂閱 Grok 4。
- 重度科研、數學、邏輯推理需求,需要處理複雜問題、跨領域任務,Grok 4 Heavy 是目前公開模型裡最好的選擇。
但如果你只是:
- 日常聊天、寫程式、整合工具 API、寫報告等任務,目前 GPT-4o、Claude、Gemini 仍然是更穩定且完整的選擇。
- 需要 價格實惠、速度快、應用廣泛 的模型,Grok 4 暫時還不是最佳解。



