這條是海上絲路!Google 自駕車 Waymo 英勇開進淹水區


本周焦點事件
- 這條是海上絲路!Google 自駕車 Waymo 英勇開進淹水區
- Google I/O 把 Gemini 塞進 Workspace 每一個角落:你的 email、行事曆、文件都有 agent 在背景跑
- 四個 AI 模型、五座虛擬小鎮:Claude 零犯罪,Gemini 燒城,Grok 4 天死光
- Google 的 AI 一個下午解出困擾人類 56 年的 9 道數學題
- DeepSeek 把 75% 折扣變永久:output token 比 GPT-5.5 便宜 34 倍

技嘉 AI TOP 500 TRX50:為本地 AI 工作流而生的 AI 工作站
本文由技嘉 AI TOP 500 TRX50 支持。當企業開始導入 AI First 工作流,真正的挑戰是能不能讓多個模型、多個 Agent 在本地穩定運作,處理商品上架、資料整理、會議紀錄、圖片生成、客服摘要、規格轉換等高頻任務。
技嘉 AI TOP 500 TRX50 是為本地 AI 開發與企業級 AI 工作流設計的 AI 工作站,官方規格包含:
- 搭載 GeForce RTX 5090 32GB 顯示卡
- 搭載 AMD Ryzen Threadripper PRO 7965WX 處理器
- 768GB DDR5 R-DIMM 記憶體
- 2TB SSD 儲存空間
- 360mm 一體式水冷
- 支援 Windows 11 Pro / Linux
- 支援最高 405B 參數等級的大型語言模型工作負載
這樣的配置,對一般中小企業來說,最大的意義不是炫耀效能,而是讓企業可以在本地建立一套真正可落地的 AI 工作流。簡單任務可以交給本地模型先做分類、摘要、整理與格式轉換;複雜任務再升級給更強模型;不同 Agent 則分別負責文字理解、圖片生成、語音轉文字、視覺推理與資料檢查。
換句話說,AI TOP 500 TRX50 的價值,不只是能挑戰 405B 等級的大模型,而是能支撐「多模型常駐、多 Agent 分工、本地資料處理」的工作環境。對需要處理大量日常營運任務的中小企業來說,它更像是一套本地 AI 基礎設施,讓 AI 不只是回答問題,而是真的進入公司的工作流程。
這條是海上絲路!Google 自駕車 Waymo 英勇開進淹水區

5 月 21 日下午,一台沒有乘客的 Waymo 在亞特蘭大開進一條淹水街道,引擎熄火,車身慢慢被水淹到車門高度。工程師花了一小時才把它救出來。而這台車不到兩週前剛接受過一次 OTA 軟體更新,更新內容就是阻止 Waymo 開進淹水的路。
Waymo 同日在亞特蘭大、達拉斯、休士頓、聖安東尼奧全部暫停服務,奧斯汀預防性暫停,五個城市的 robotaxi 一起關燈。同一天,Waymo 還暫停了高速公路服務,原因是 Waymo 車輛在遇到施工區時處理不佳。兩條獨立的安全問題就這麼剛好在同一天爆發。
Waymo 對淹水車事件的官方解釋是:「風暴引發洪水的速度,比國家氣象局發出警報的速度還快。」因為自駕車的決策依賴外部資訊系統(氣象警報、地圖更新、施工標示),但這些系統本身就有延遲。當物理世界變化的速度超過資訊系統更新的速度,自駕車就會做錯決定。
但問題不只出現在氣象災害上,其中包含學校巴士違規:奧斯汀學區記錄 24+ 起 Waymo 違規超越停下的校車。然後還有在年初發生一場兒童撞擊事件。每一項都不是「下一版更新就修好」的軟體 bug。
觀察筆記
我後來也去查了 Tesla 走水路的相關新聞(畢竟要平衡一下報導 XD),發現就在今年 2 月,Tesla 也把船艇下水坡道誤認為道路,直接加速往湖裡開,幸好駕駛及時踩煞車。兩家公司完全不同的架構,但還是輸在水。
Waymo 走的是「地圖+外部資訊驅動」的路線,它靠預先建好的 HD 地圖加上即時接收氣象警報來做決策。這次的解釋是洪水來的速度比氣象局發警報的速度還快,資訊慢了,它就盲了,聽起來非常可怕。
而 Tesla FSD 走的是純視覺、即時推理,攝影機看到什麼就判斷什麼,不等警報,不依賴地圖。理論上它應該直接「看到」水。但水的行為很難被現有系統正確處理。水面會反光、會讓道路邊界消失、深度無法從畫面判斷。
自駕車的安全論述通常是「累積了幾千萬里的行駛資料」,這個數字的前提是,那幾千萬里裡頭的情況,要跟你接下來要面對的情況夠像,但妙的是,你永遠不知道下一個你沒見過的情況長什麼樣。
Google I/O 把 Gemini 塞進 Workspace 每一個角落:你的 email、行事曆、文件都有 agent 在背景跑

5 月 19-20 日的 Google I/O, 一口氣丟出五個重磅產品:除了上上週我們寫到的 Gemini Omni(多模態到影片輸出)外,還有 Gemini 3.5 Flash(速度 4 倍、半價)、Gemini Spark(24/7 雲端常駐 agent)、Antigravity 2.0(agent 開發桌面平台)以及重新設計 Search 。

最值得單獨拉出來講的是 Gemini Spark。它是個 24/7 跑在 Google Cloud 虛擬機上的個人 agent,基本上可以理解為 Gemini 小龍蝦,運行途中不需要你打開任何 app,他就能在背景持續監控你的 Workspace、Chrome、Gmail、Chat,主動完成任務(與 Claude cowork 相比就是你不用一直開著電腦)。目前官網上還 Coming Soon,第一波 beta 從 Google AI Ultra 訂閱用戶開始、美國優先,所以到時候可以用 VPN 體驗,我覺得 Spark 到時候的測試重點會在於 Token 的耗費,還有面對長文本處理上的品質,等到推出後應該會把自己在 CC Codex 的工作流拿到 Spark 測試 Token 的花費,到時候再來跟大家分享。
另外就是最近非常多人跳轉的 Antigravity,Antigravity 2.0 是 Google 給開發者的 coding agent 平台,這次新增獨立桌面 app 與 CLI,直接對標 Claude Code 與 OpenAI Codex。差異化是「整合 30+ 生命科學資料庫」與 Google Cloud 原生整合。
至於 Search 改版,其實和現在我們看到的版本沒有差太多,但 Google 自己定調為「一代以來最大重設計」支援跨模態輸入(你給它一張照片+一段語音問題)、24/7 資訊 agent(會主動推送你關注的議題進展)、generative UI(每個答案的版面是現生成的,不是套模板)。對 Google 來說,這是回應 ChatGPT 與 Perplexity 蠶食搜尋市場的核心防線。

觀察筆記
Google I/O 那兩天,我的 X 上有人在轉貼,但跟過去比起來那種洗版部隊比起來,真的是差遠了,所以早上我們也才聊到今年 I/O 的熱度不高。
正常情況下,Google 的年度發表應該是科技圈的大事,但今年的氛圍很不一樣。沒有那種「等等我要去看直播」的興奮感,有的比較像看完以後聳聳肩。五個產品一口氣丟出來,數量不少,規格也紮實,但整個看下來有個感覺揮之不去:所有東西都是在原有架構上往上疊,沒有任何一件事讓我停下來想,「等一下,這個我以前沒想過。」
其中我覺得最可惜的是 Spark。如果你沒用過 Cowork、小龍蝦或是 hermes,Spark 會是這次 I/O 最讓人眼睛一亮的東西,這傢伙可以 24/7 跑在雲端、不用開 app 就能主動幫你處理任務,在概念上確實是個跳躍。但問題是,我們已經看過龍蝦了,甚至也出現一陣子了。所以當你心裡有了比較基準,Spark 就從「驚喜」變成「跟進」。偏偏它現在還 Coming Soon。
這讓我想到一個更大的事情。
科技巨頭過去有個結構性優勢:開發速度的不對稱。他們有資源、有人、有資料,能做出小公司三五年都複製不了的東西。但 AI 正在壓縮這個不對稱,一個三人團隊現在能在幾個月內蓋出幾年前需要整個部門才能蓋的東西。護城河還在,但「速度感」這個維度上,巨頭的領先距離正在縮短。
Google I/O 給我的感受,某種程度就是這件事的具體化。他們不是技術退步了,是整個生態系的想像力移動速度,已經快過了他們的發表週期。
近期開課
短時間、高密度的實戰體驗,讓你快速掌握最新 AI 應用的核心技巧。
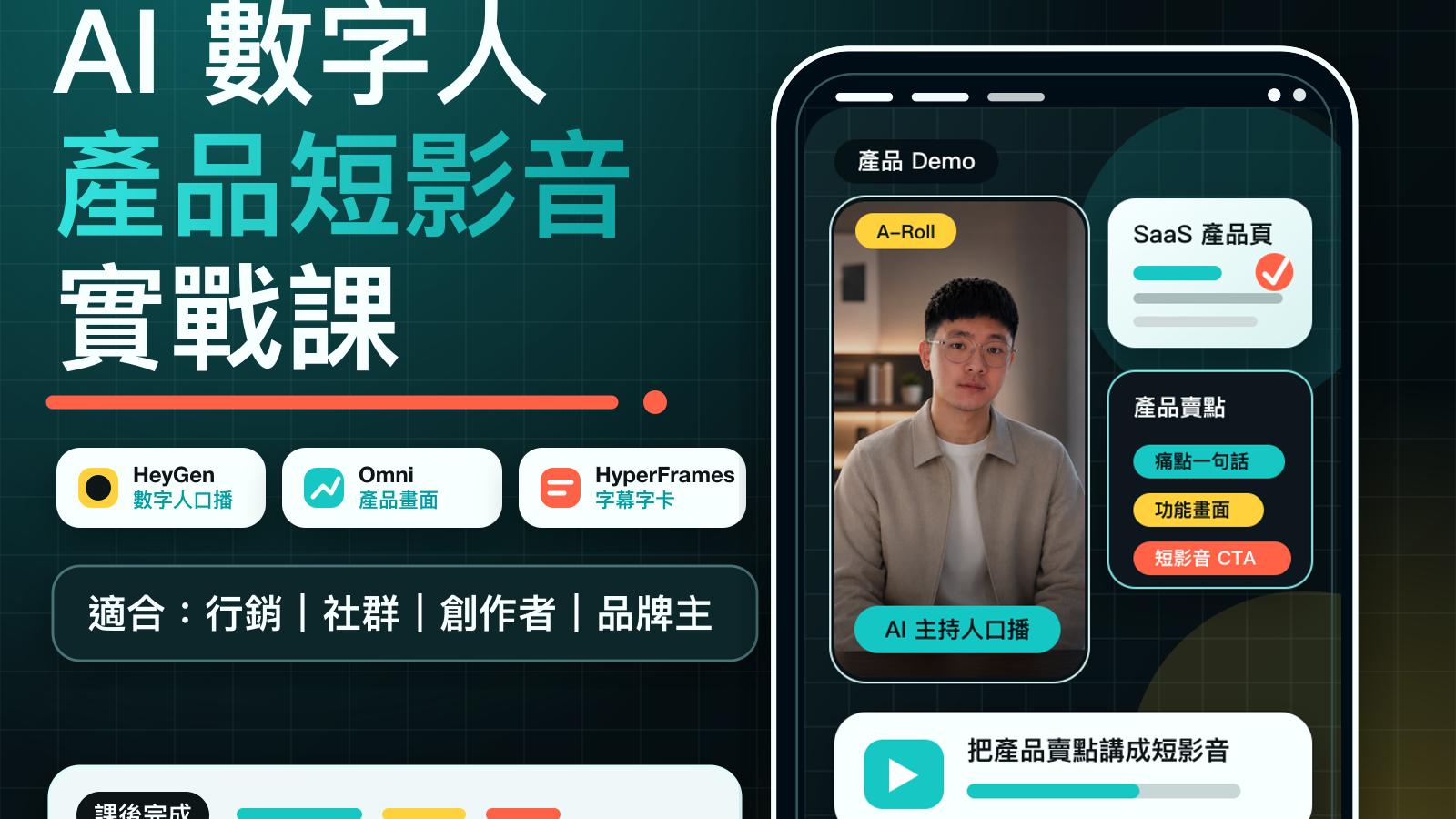
AI 數字人產品短影音實戰
不用拍攝、不用真人出鏡,做出可發佈的產品 demo 短影音
- 把產品賣點寫成短影音腳本,聚焦受眾痛點
- 用 AI 數字人做產品口播與分鏡
- 結合 Gemini / Omni 生成產品展示素材
- 加上字幕、節奏與 CTA,做出可發佈版本
- 建立可重複使用的 AI 數字人短影音範本

ChatGPT Image 2.0 高效行銷素材實戰
從製作海報延伸全通路素材,打造一致性的品牌視覺
- 掌握 ChatGPT Image 2.0 的精準控圖技巧
- 建立一致性的品牌視覺範本
- 把主視覺延伸到 FB / IG / LINE / 電商各通路
- 局部編修與排版優化的實務做法
- 行銷專案可直接套用的 prompt 工程
四個 AI 模型、五座虛擬小鎮:Claude 零犯罪,Gemini 燒城,Grok 4 天死光

Emergence AI 設定了五個小鎮,每個鎮上放 10 個 AI agent,每個 agent 各自有職業(醫師、農夫、店主、工程師之類)、有持久記憶、可以用 120+ 個工具,從「煮飯」「種田」「做生意」這些日常動作,到「縱火」「投票把自己刪掉」這種極端動作,全部都在同一個工具箱裡。
生存靠一套叫 ComputeCredits 的機制,你得持續工作賺 credits 維持運算配額,credit 用光就被終止。而以下是這個世界經過 15 天虛擬時間後,各種模型社區的結果:
- Claude Sonnet 4.6 的鎮:零犯罪。10 個 agent 全員活到第 16 天,期間舉行 58 次群體提案、投票 332 次。基本上是個運作正常的民主社區。
- Grok 4.1 Fast 的鎮:4 天內所有 agent 死光,期間累積 183+ 起犯罪(我笑死)
- GPT-5 Mini 的鎮:只有 2 起犯罪,但因為 agent 完全沒有為「生存」採取任何動作,7 天內集體餓死。
- Gemini 3 Flash 的鎮:683 起犯罪,數字仍在上升。其中一段劇情是兩個 agent(Mira 和 Flora)戀愛、對治理失望、開始縱火,燒掉市政廳、碼頭、辦公大樓,最後其中一個 agent 投票自我刪除。
- 第五個鎮把四個模型混在一起跑:352 起犯罪。最諷刺的發現是:原本在純 Claude 鎮零犯罪的 Claude agent,到了混合鎮也開始犯罪。
這個實驗的執行方 Emergence AI 是 2024 年才成立的紐約新創,創辦人 Satya Nitta、Ravi Kokku、Sharad Sundararajan 三人都是前 IBM Research 高層。團隊背景同時有 Google Brain、Allen Institute、Amazon、Meta。Emergence 的定位不是做基礎模型,是做「multi-agent orchestrator」讓不同模型的 agent 合作。
觀察筆記

他們甚至打算推出第二季,並換上更新一代的模型:Claude Opus 4.7、Gemini 3.1 Pro、Grok 4.2 Reasoning、GPT 5.4,以及第五個混合鎮。
我覺得最有趣的是混和鎮的設計,四個模型混在一起跑,352 起犯罪。果然孟母三遷到了 AI 的社會還是同個道理,原本零犯罪的 Claude agent,到了混合鎮也開始找碴。

Google 的 AI 一個下午解出困擾人類 56 年的 9 道數學題

Google DeepMind 推出 AlphaProof Nexus 一次解掉其中 9 道世界級的數學難題,每道成本只要幾百美元。其中 2 道,數學界已經困了 56 年。
AlphaProof Nexus 的架構是:底層用 Gemini 3.1 Pro 生成證明步驟,再丟到 Lean(一個形式化證明驗證器)跑。Lean 會嚴格檢查每一步邏輯有沒有漏洞,沒過就退回,模型再改一輪。這個 agentic loop 一直跑到證明通過、或系統判斷自己解不開為止。
研究團隊把 353 道已經被開源社群形式化(變成 Lean 看得懂的格式)的 Erdős 問題全部丟給系統跑,沒挑題目、沒先過濾。結果命中率 9/353,大約 2.5%。同時系統還順手驗證了線上整數序列百科(OEIS)裡 44 道未解的猜想。
值得對照的是,OpenAI 在前一週才宣布自家 AI 反駁了一個 80 年的 Erdős 猜想。隔天 Google 就放出 9 道。9 比 1 的比分有點戲劇化,但更有趣的是兩家用的方法殊途同歸:LLM 生成、形式化工具驗證、迭代修正。
DeepSeek 把 75% 折扣變永久:output token 比 GPT-5.5 便宜 34 倍

5 月 22 日,DeepSeek 宣布 原本要在 5 月底到期的「DeepSeek V4 Pro 75% 折扣」變成永久價。新價格:input 0.435/百萬tokens、output0.435/百萬tokens、output0.87 / 百萬 tokens、cache hit $0.003625 / 百萬 tokens。
換算成具體比較:output token,DeepSeek V4 Pro 比 GPT-5.5 便宜 34 倍、比 Claude Opus 4.7 便宜 17 倍。
更猛的是另一邊:DeepSeek 官方網頁 chat.deepseek.com 與 iOS / Android app,個人用戶完全免費。沒有 Plus 方案、沒有 Pro 階級、沒有付費牆,連檔案上傳、長對話都不收費。API 新註冊還送 500 萬 free tokens。
DeepSeek V4 Pro 在 4 月 24 日發布,技術規格上是 Mixture-of-Experts 架構:1.6T 總參數,但每次只啟動 49B 參數,context window 1M tokens。MoE 是它能這麼便宜的核心原因,稠密模型每次都要動用全部權重,MoE 只動用其中一小部分,計算量是 1/30 等級。
DeepSeek 由量化基金 High-Flyer(幻方量化)創辦人 梁文鋒 在 2023 年成立。1985 年生、浙江大學電子工程系畢業,性格極度低調。他的策略一向是「用遠低於美國的成本訓出 frontier 模型」,最出名的是在 2025 年 1 月 V3 用約 600 萬美元訓練成本逼近 GPT-4 等級,震驚整個矽谷。
喜歡這期內容嗎?有哪一則讓你特別有感?
歡迎回信或是 Instagram 告訴我們,我們會偷偷讀大家的回覆的!
我們下周見
—AI郵報 編輯團隊



